Python之Scrapy爬虫框架 入门实例(一)
一、开发环境
1.安装 scrapy
2.安装 python2.7
3.安装编辑器 PyCharm
二、创建scrapy项目pachong
1.在命令行输入命令:scrapy startproject pachong
(pachong 为项目的名称,可以改变)

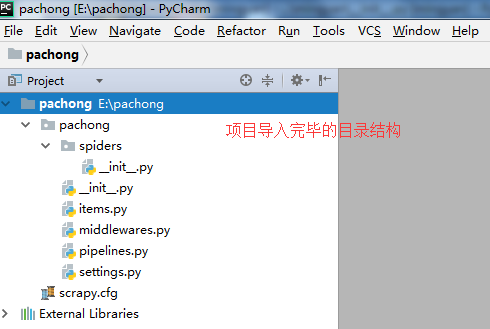
2.打开编辑器PyCharm,将刚刚创建的项目pachong导入。
(点击file—>选择open—>输入或选择E:\pachong—>点击ok)
三、创建scrapy爬虫文件pachong_spider.py
在pachong_spider.py这个文件夹中编写爬取网站数据的内容。
(右击文件spiders—>选择New,在选择PhthonFile—>输入文件名pachong_spider)

四、编写爬虫pachong
将 网址 http://lab.scrapyd.cn/ 博客中的所有博客标题和博客标签,以作者名-语录为名分别保存在各自作者对应的txt文件中。
1.查看http://lab.scrapyd.cn/源代码,获取自己所需的博客标题、作者、标签三个内容的对应HTML标签信息。

2.获取网址的内容,保存到变量pachong里。
(分析HTML结构,每一段需要提取的内容都被一个 <div class="quote post">……</div> 包裹。)

3.获取循环获取标题、作者的第一个内容,和对应标签的内容,并对标签的内容进行逗号分隔后,进行分类保存。

4.查看下一页的HTML标签,对下一页获取的内容进行循环。
(查看存在不存在下一页的链接,如果存在下一页,把下一页的内容提交给parse然后继续爬取。如果不存在下一页链接结束爬取。)


5.爬虫源代码。
1 # -*- coding: utf-8 -*- 2 import sys 3 reload(sys) 4 sys.setdefaultencoding('utf-8') 5 #Python 默认脚本文件都是 UTF-8 编码的,当脚本出现中文汉字时需要对其进行解码。 6 import scrapy 7 class itemSpider(scrapy.Spider): 8 # scrapy.Spider 是一个简单的爬虫类型。 9 # 它只是提供了一个默认start_requests()实现。 10 # 它从start_urlsspider属性发送请求,并parse 为每个结果响应调用spider的方法。 11 name ="pachong" 12 # 定义此爬虫名称的字符串。 13 # 它必须是唯一的。 14 start_urls = ['http://lab.scrapyd.cn'] 15 #爬虫抓取自己需要的网址列表。 16 #该网站列表可以是多个。 17 def parse(self, response): 18 # 定义一个parse规则,用来爬取自己需要的网站信息。 19 pachong = response.css('div.quote') 20 # 用变量pachong来保存获取网站的部分内容。 21 for v in pachong: 22 text = v.css('.text::text').extract_first() 23 autor = v.css('.author::text').extract_first() 24 tags = v.css('.tags .tag::text').extract() 25 tags = ','.join(tags) 26 # 循环提取所有的标题、作者和标签内容。 27 fileName = u'%s-语录.txt' % autor 28 # 文件的名称为作者名字—语录.txt。 29 with open(fileName, "a+")as f: 30 f.write(u'标题:'+text) 31 f.write('\n') 32 f.write(u'标签:' + tags) 33 f.write('\n------------------------------------------------\n') 34 # 打开文件并写入标题和标签内容。 35 f.close() 36 # 关闭文件 37 next_page = response.css('li.next a::attr(href)').extract_first() 38 if next_page is not None: 39 next_page = response.urljoin(next_page) 40 yield scrapy.Request(next_page, callback=self.parse) 41 # 查看存在不存在下一页的链接,如果存在下一页,把下一页的内容提交给parse然后继续爬取。 42 # 如果不存在下一页链接结束爬取。
五、运行爬虫pachong
1.在命令行输入命令:scrapy crawl pachong
(在pachong的目录下输入命令)


2.打开e盘 pachong文件夹,已经按要求爬取网址 http://lab.scrapyd.cn/ 的内容。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号