hadoop系列二:HDFS文件系统的命令及JAVA客户端API
转载请在页首明显处注明作者与出处
http://www.cnblogs.com/zhuxiaojie/p/6391518.html
一:说明
此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等。
当前使用的hadoop版本为2.6.4
二:HDFS的shell命令
上一章说完了安装HADOOP集群部分,这一张讲HDFS。
其实基本上操作都是通过JAVA API来操作,所以这里的shell命令只是简单介绍一下,实际操作中自然是JAVA API更加方便,功能也更加强大,JAVA API在第三部分。
注:这里JAVA API连接的地址,其实就是server1,也就是前面安装namenode的服务器。
调用文件系统(FS)Shell命令应使用 bin/hadoop fs <args>的形式。 所有的的FS shell命令使用URI路径作为参数。URI格式是scheme://authority/path。对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。一个HDFS文件或目录比如/parent/child可以表示成hdfs://namenode:namenodeport/parent/child,或者更简单的/parent/child(假设你配置文件中的默认值是namenode:namenodeport)。大多数FS Shell命令的行为和对应的Unix Shell命令类似,不同之处会在下面介绍各命令使用详情时指出。出错信息会输出到stderr,其他信息输出到stdout
2.1:cat
使用方法:hadoop fs -cat URI [URI …]
将路径指定文件的内容输出到stdout。
示例:
- hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
返回值:
成功返回0,失败返回-1。
2.2:chgrp
使用方法:hadoop fs -chgrp [-R] GROUP URI [URI …] Change group association of files. With -R, make the change recursively through the directory structure. The user must be the owner of files, or else a super-user. Additional information is in the Permissions User Guide. -->
改变文件所属的组。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
2.3:chmod
使用方法:hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI …]
改变文件的权限。使用-R将使改变在目录结构下递归进行。命令的使用者必须是文件的所有者或者超级用户。更多的信息请参见HDFS权限用户指南。
2.4:chown
使用方法:hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
改变文件的拥有者。使用-R将使改变在目录结构下递归进行。命令的使用者必须是超级用户。更多的信息请参见HDFS权限用户指南。
2.5:copyFromLocal
使用方法:hadoop fs -copyFromLocal <localsrc> URI
除了限定源路径是一个本地文件外,和put命令相似
2.6:copyToLocal
使用方法:hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
除了限定目标路径是一个本地文件外,和get命令类似。
2.7:cp
使用方法:hadoop fs -cp URI [URI …] <dest>
将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
示例:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
返回值:
成功返回0,失败返回-1。
2.8:du
使用方法:hadoop fs -du URI [URI …]
显示目录中所有文件的大小,或者当只指定一个文件时,显示此文件的大小。
示例:
hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
2.9:dus
使用方法:hadoop fs -dus <args>
显示文件的大小。
2.10:expunge
使用方法:hadoop fs -expunge
清空回收站。请参考HDFS设计文档以获取更多关于回收站特性的信息。
2.11:get
使用方法:hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
复制文件到本地文件系统。可用-ignorecrc选项复制CRC校验失败的文件。使用-crc选项复制文件以及CRC信息。
示例:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://host:port/user/hadoop/file localfile
返回值:
成功返回0,失败返回-1。
2.12:getmerge
使用方法:hadoop fs -getmerge <src> <localdst> [addnl]
接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl是可选的,用于指定在每个文件结尾添加一个换行符。
2.13:ls
使用方法:hadoop fs -ls <args>
如果是文件,则按照如下格式返回文件信息:
文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
目录名 <dir> 修改日期 修改时间 权限 用户ID 组ID
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失败返回-1。
2.14:lsr
使用方法:hadoop fs -lsr <args>
ls命令的递归版本。类似于Unix中的ls -R。
2.15:mkdir
使用方法:hadoop fs -mkdir <paths>
接受路径指定的uri作为参数,创建这些目录。其行为类似于Unix的mkdir -p,它会创建路径中的各级父目录。
示例:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- hadoop fs -mkdir hdfs://host1:port1/user/hadoop/dir hdfs://host2:port2/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
2.16:movefromLocal
使用方法:dfs -moveFromLocal <src> <dst>
输出一个”not implemented“信息。
2.17:mv
使用方法:hadoop fs -mv URI [URI …] <dest>
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:
- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
2.18:put
使用方法:hadoop fs -put <localsrc> ... <dst>
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
- hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
2.19:rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:
- hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
2.20:rmr
使用方法:hadoop fs -rmr URI [URI …]
delete的递归版本。
示例:
- hadoop fs -rmr /user/hadoop/dir
- hadoop fs -rmr hdfs://host:port/user/hadoop/dir
返回值:
成功返回0,失败返回-1。
2.21:setrep
使用方法:hadoop fs -setrep [-R] <path>
改变一个文件的副本系数。-R选项用于递归改变目录下所有文件的副本系数。
示例:
- hadoop fs -setrep -w 3 -R /user/hadoop/dir1
返回值:
成功返回0,失败返回-1。
2.22:stat
使用方法:hadoop fs -stat URI [URI …]
返回指定路径的统计信息。
示例:
- hadoop fs -stat path
返回值:
成功返回0,失败返回-1。
2.23:tail
使用方法:hadoop fs -tail [-f] URI
将文件尾部1K字节的内容输出到stdout。支持-f选项,行为和Unix中一致。
示例:
- hadoop fs -tail pathname
返回值:
成功返回0,失败返回-1。
2.24:test
使用方法:hadoop fs -test -[ezd] URI
选项:
-e 检查文件是否存在。如果存在则返回0。
-z 检查文件是否是0字节。如果是则返回0。
-d 如果路径是个目录,则返回1,否则返回0。
示例:
- hadoop fs -test -e filename
2.25:text
使用方法:hadoop fs -text <src>
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
2.26:touchz
使用方法:hadoop fs -touchz URI [URI …]
创建一个0字节的空文件。
示例:
- hadoop -touchz pathname
返回值:
成功返回0,失败返回-1。
三:JAVA API
此部分遇到的问题参见第四章节异常部分
本部分的java代码在github中已上传,地址:
首先创建一个MAVEN项目,加入如下依赖
<hadoop.version>2.6.4</hadoop.version>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
然后在写一个测试类,先写这样一段代码初始化对象
@Before
public void init() throws IOException, InterruptedException, URISyntaxException{
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.1.4:9000");
//拿到操作HDFS的一个实例,并且设置其用户
fs = FileSystem.get(new URI("hdfs://192.168.1.4:9000"),conf,"hadoop");
}
3.1:上传文件
/**
* 上传
* @throws Exception
*/
@Test
public void upload()throws Exception{
//后面的true,是指如果文件存在,则覆盖
FSDataOutputStream fout = fs.create(new Path("/xx.jpg"), true);
InputStream in = new FileInputStream("C:/Users/Administrator/Pictures/1.png");
//复制流,并且完成之后关闭流
IOUtils.copyBytes(in, fout, 1024,true);
}
3.2:下载文件
/**
* 下载
* @throws Exception
*/
@Test
public void download()throws Exception{
FSDataInputStream fin = fs.open(new Path("/xx.jpg"));
OutputStream out = new FileOutputStream("d://axx.jpg");
IOUtils.copyBytes(fin, out, 1024,true);
}
3.3:读取文件指定的部分
/**
* 在指定位置读写
* @throws Exception
*/
@Test
public void random()throws Exception{
FSDataInputStream fin = fs.open(new Path("xx.jpg"));
//从12的位置开始读
fin.seek(12);
OutputStream out = new FileOutputStream("d://axx.jpg");
IOUtils.copyBytes(fin, out, 1024,true);
}
3.4:获取hadoop中的配置属性
/**
* 可以获取hadoop配置
* @throws Exception
*/
@Test
public void conf()throws Exception{
Iterator<Entry<String, String>> iterator = conf.iterator();
while(iterator.hasNext()){
Entry<String, String> entry = iterator.next();
System.out.println(entry);
}
}
3.5:创建文件夹
/**
* 创建文件夹
* @throws Exception
*/
@Test
public void mkdir()throws Exception{
boolean mkdirs = fs.mkdirs(new Path("/mkdir/a/b"));
if(mkdirs){
System.out.println("创建文件夹成功");
}
fs.close();
}
3.6:删除文件与目录
/**
* 删除
* @throws Exception
*/
@Test
public void delete()throws Exception{
//递归删除
boolean delete = fs.delete(new Path("/mkdir/a/b"), true);
if(delete){
System.out.println("删除成功");
}
fs.close();
}
3.7:使用迭代器递归列出所有文件
这种迭代器可以列出HDFS的所有文件,而不用担心内存溢出,因为这段代码并不是直接把所有的文件信息封装到对象中,而是一个远程迭代器。
/**
* 列出文件,可以递归所有文件,它是一个迭代器,因为客户端无法接收所有文件信息
*/
@Test
public void listFile()throws Exception{
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus lfs = listFiles.next();
System.out.println("块大小:" + lfs.getBlockSize());
System.out.println("所属组:" + lfs.getOwner());
System.out.println("大小:" + lfs.getLen());
System.out.println("文件名:" + lfs.getPath().getName());
System.out.println("是否目录:" + lfs.isDirectory());
System.out.println("是否文件:" + lfs.isFile());
System.out.println();
BlockLocation[] blockLocations = lfs.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
System.out.println("块偏移数:" + blockLocation.getOffset());
System.out.println("块长度:" + blockLocation.getLength());
System.out.println("块名称:" + Arrays.toString(blockLocation.getNames()));
System.out.println("块名称:" + Arrays.toString(blockLocation.getHosts()));
}
System.out.println("--------------------------");
}
}
3.8:列出一个目录的所有文件信息,不递归
这一段代码是列出一个目录中所有的文件信息,因为它无法递归,所以它的返回结果是一个数组,或者说直接把当前目录的信息返回到了这个数组。
/**
* 列出文件,但是不可以递归,所以可以直接用数组存储,
* @throws Exception
*/
@Test
public void listFile2()throws Exception{
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
System.out.println("块大小:" + fileStatus.getBlockSize());
System.out.println("所属组:" + fileStatus.getOwner());
System.out.println("大小:" + fileStatus.getLen());
System.out.println("文件名:" + fileStatus.getPath().getName());
System.out.println("是否目录:" + fileStatus.isDirectory());
System.out.println("是否文件:" + fileStatus.isFile());
}
}
四:问题部分
4.1:问题一
使用如下API时,报空指针

准确的说是这些和HDFS shell一样的api,都会抛出空指针,为什么呢?
其实如果看过了上面的JAVA API部分的代码,可以发现,在上面部分我没有写这些方法。首先是其它的方法可以代替,并且功能更加强大,其次这些代码运行比较麻烦。
因为这里面实际上就是使用了HDFS的shell,有可能你在HADOOP服务器安装了hadoop,但是在运行这段代码的机器并没有安装,所以会报错。
正确的做法是配置HADOOP_HOME的环境变量,而且需要是专门在运行的操作系统上编译的专属版本,不要说LINUX与WINDOWS不一样,就是WINDOWS7和WINDOWS10都可能不一样,所以要经过专门的编译。
4.2:问题二
使用java客户端时提示Missing artifact jdk.tools:jdk.tools:jar:1.6,这一段是MAVEN报的错。
可以相信,出现这个问题的人,一定没有按照本文相应的引入依赖,hadoop-common中依赖了jdk中的一个包,所以在一开始,就要求了引入如下的jar包,引入后就没事了
<dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.6</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency>
4.3:问题三
使用java客户报时,抛出异常,没有hdfs协议,它是在这样的一行代码中报错的
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.154.2:9000"), new Configuration());
抛出的异常如下:
java.io.IOException: No FileSystem for scheme: hdfs
好了,首先可以肯定,你使用的hadoop版本不是和本文的2.6.4一致,应该是更老的版本。
我们看一下源代码
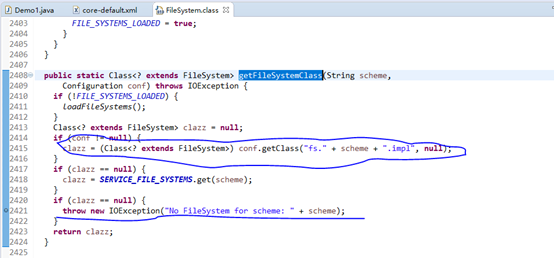
通过断点发现,参数中的scheme是hdfs,也就是我参数中的协议,然后拼接后根据一定的映射去查看对应的类实现,如果找不到,则返回null,也就是产生了这样的异常。
提示没有hdfs的协议,这是因为在hadoop-commons.jar中,有一个core-default.xml文件并没有配置这个协议,如下是我之前使用的2.2的版本
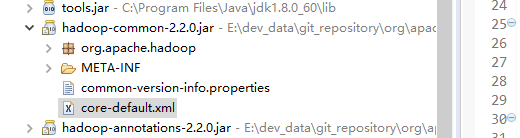
我们找到这个文件所在本地maven仓库的位置,然后用压缩软件打开这个jar包,把这个core-default.xml复制出去,然后编辑,加入这样一段配置
<property> <name>fs.hdfs.impl</name> <value>org.apache.hadoop.hdfs.DistributedFileSystem</value> <description>The FileSystem for hdfs: uris.</description> </property>
这样我们就配置了hdfs协议的实现,相应的错误也就不再出现了。

