
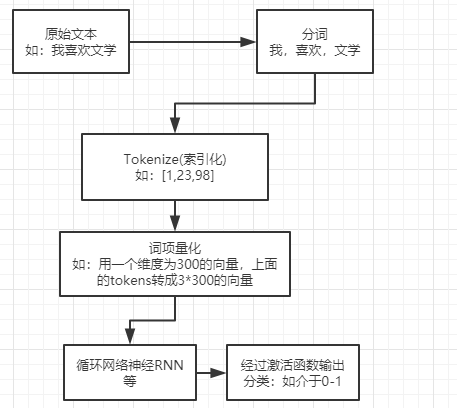
使用TensorFlow进行中文自然语言处理的情感分析
1 TensorFlow使用
分析流程:
1.1 使用gensim加载预训练中文分词embedding
加载预训练词向量模型:https://github.com/Embedding/Chinese-Word-Vectors/
from gensim.models import KeyedVectors cn_model = KeyedVectors.load_word2vec_format('H:/词向量/word+Ngram/sgns.zhihu.bigram', binary=False)
查看词语的向量模型表示: 维度为300

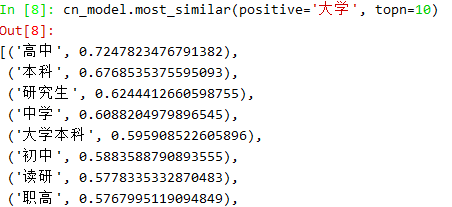
词语相似度:向量余弦值

最相似的词:
1.2 训练样本预料
准备一个训练集,4000个酒店评论,其中2000条为pos积极的,2000条为消极的,每条评论放在一个文件中。
1)文本预处理,分词、索引化
读取数据

import os import re import jieba from gensim.models import KeyedVectors cn_model = KeyedVectors.load_word2vec_format('H:/word+Ngram/sgns.zhihu.bigram', binary=False) baseDir = "H:/谭松波老师8++酒店评论++语料/utf-8/4000" pos_txts = os.listdir("H:/谭松波老师8++酒店评论++语料/utf-8/4000/pos") neg_txts = os.listdir("H:/bishe/NLP/训练集/谭松波老师8++酒店评论++语料/utf-8/4000/neg") train_text_orig = [] for i in range(len(pos_txts)): with open(baseDir+"/pos/"+pos_txts[i], errors="ignore", encoding="utf-8") as f: text = f.read().strip() train_text_orig.append(text) f.close() for i in range(len(neg_txts)): with open(baseDir+"/neg/"+neg_txts[i], errors="ignore", encoding="utf-8") as f: text = f.read().strip() train_text_orig.append(text) f.close()
分词,建立索引:
# [[句子词索引],[]] train_tokens = [] for text in train_text_orig: # 去掉标点符号 text = re.sub("[\s+\.\!\/_,$%^*(+\"\')]+|[+——()?【】“”!,。?、~@#¥%……&*()]+", "", text) # 结巴分词 cut = jieba.cut(text) # 结巴分词结果为一个生成器 cut_list = [i for i in cut] for i, word in enumerate(cut_list): try: # 将词转换成索引 cut_list[i] = cn_model.vocab[word].index except KeyError: cut_list[i] = 0 train_tokens.append(cut_list)
2)文本长度标准化:
长度参差不齐,我们需要将长度标准化,方便模型进行训练,如果长度太短,会损失太多的信息,而长度太长会浪费太多计算资源
所以说我们要取一个这种的方案,让这个长度基本上涵盖所有的训练样本,又不损失太多的信息
样本长度分布图:
# 看一下样本长度分布图 import matplotlib.pyplot as plt plt.hist(num_tokens, bins=100) plt.xlim(0, 400) plt.ylabel("number of tokens") plt.xlabel("length of tokens") plt.title("Distribution of tokens length") plt.show()
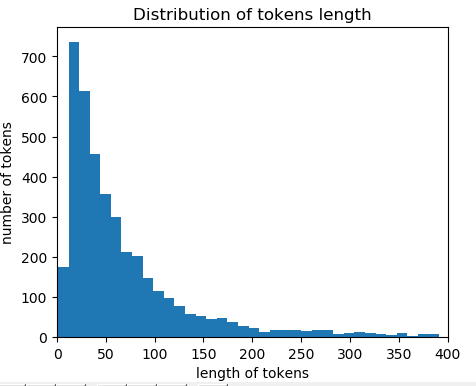
# 取tokens平均值加上两个tokens的标准差 # 假设tokens长度的分布符合正太分布,则max_tokens这个值可以涵盖95%左右的样本 max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
# 取tokens的长度为236时,大约95%左右的样本被涵盖 # 对于长度不足的进行padding,过长的进行修剪 np.sum(num_tokens<max_tokens)/len(num_tokens)
反tokenize
def reverse_token(tokens): ''' 将索引化的句子还原 :param tokens: 句子 [词语,..] :return: ''' text = "" for i in tokens: if i!=0: text = text+cn_model.index2word[i] else: text =text+" " return text
3)准备Emdedding Matrix(词向量矩阵)
根据Keras的要求,我们需要准一个维度为(numwords, embeddingdim)的矩阵,num words代表我们使用的词汇的数量,emdedding dimension在我们预训练词向量模型中是300,每个词汇都用长度为300的向量表示(例如: 较好 ->[ 0.056964, -0.127308, -0.118041,...]),注意词向量矩阵是作为训练模型的工具,
# 初始化词向量矩阵-embedding matrix(只用前50000个词) num_words = 50000 embedding_matrix = np.zeros((num_words, embedding_dim)) # 维度为(50000, 300)的矩阵 for i in range(num_words): embedding_matrix[i,:]=cn_model[cn_model.index2word[i]] # 将词向量赋值到词向量矩阵中 embedding_matrix = embedding_matrix.astype("float32") # 检查赋值是否正确 np.sum(cn_model[cn_model.index2word[333]]==embedding_matrix[333])
词向量矩阵维度:

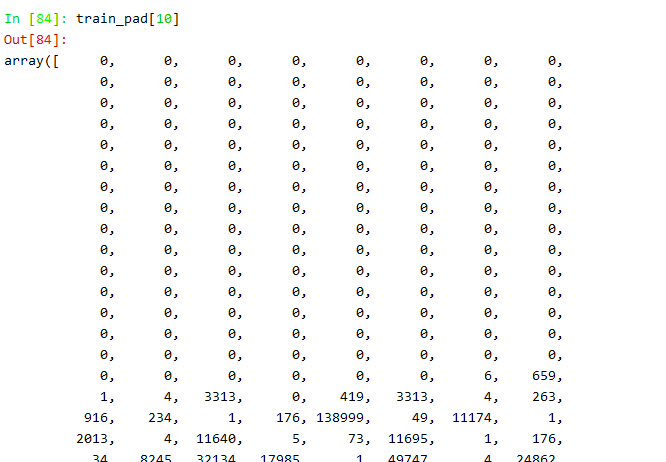
4) padding(填充)和truncating(修剪)
我们把问转换成token(索引)后,每一串索引的长度都不相等,所以为了方便模型的训练我们需要将索引的长度标准化,上面我们选择了使用236这个可以涵盖95%的训练样本的长度,接下来进行padding和truncating,我们一个采用‘pre’的方法,在文本索引的前面填充0。
# 返回一个numpy array train_pad = pad_sequences(train_tokens, maxlen=max_tokens, padding="pre", truncating="pre")
准备目标向量:
# 准备target向量,前2000个位1,后2000个位0 train_target = np.concatenate((np.ones(2000), np.zeros(2000)))
训练样本和测试样本分离,使用90%的样本来做训练,10%的样本用来做测试:
# 进行训练和测试样本的分割 from sklearn.model_selection import train_test_split # 90用作训练,正面和负面打乱 X_train, X_test, y_train, y_test = train_test_split(train_pad, train_target, test_size=0.1, random_state=12)

5)使用Keras搭建神经网络模型(LSTM),模型的第一层是Embedding层
end

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步