


mysql5.7事务的原理和MVCC,redo log与bin log的区别
WAL机制 write ahead logging 预写日志,写完日志,再写入实际数据文件。
redo log 保证事务的持久性
undo log 保证事务的一致性
redo日志记录内容:表空间id,页id,页面上的偏移量,偏移量改了什么值,这样记录空间就很小。而且记录是一条一条产生的,是一个顺序IO。而insert、update、delete都是随机IO。redo type大概有53种。

每逢row id是256的倍数时,就会写入系统表空间第7号页面的某个位置,位于information库的。因为redo type很多,所以redo日志格式会有不同,比如MLOG_8BYTE redo日志格式:
举例:在0号表空间(space ID)7号页面(page Number)200的位置(offset)写入一个值1024(data)。每个row id都占据8个字节,因为是对8个字节的修改,所以type是MLOG_8TYPE,如果是修改一个字节,那么就是MLOG_1TYPE等等,MLOG_WRITE_STRING表示修改的是string。
当fsync函数有返回值时,mysql才会确确实实把数据落盘到磁盘上,做持久化了。
show variables like 'innodb_flush_log_at_trx_commit'; --默认值是1,表示当事务提交时,确保redo日志落盘到磁盘。值为2的话,只能保证写到缓冲区,但是日志能不能落盘不保证。值为0的话,事务提交时,不立即提交redo日志,将由后台线程去做,缺点是如果事务提交时,mysql挂了,后台线程来不及同步redo日志,那么将不保证完全的事务持久性。
每一个redo日志都有一个序列号Log Sequence Number 简称LSN。flushed_to_disk_lsn表示已落盘到磁盘上的事务,mysql在恢复数据的时候就是根据这两个LSN的差值来决定事务从哪里开始到哪里结束,所以LSN是非常有用。
崩溃后的恢复为什么不用bin log? bin log主要用于mysql的主从复制上,主库会把ddl和dml的修改通过网络传递给从库,从库接收后执行。
bin log 与redo log有何不同?
1、使用方式不一样。bin log会用于所有的更改操作,主要用于人工恢复数据。而redo log是mysql自己恢复使用的。
2、使用机制不一样。redo log是innodb独有的,bin log是mysql server层实现的,所有存储引擎均可使用bin log。
3、redo 日志所记录的是物理日志,记载的是页面上的某个offset做了什么修改。而bin log是逻辑日志,比如id = 2的字段我做了 +1操作,记录的是原始逻辑。
4、写盘机制不一样。redo log只有两个,循环写,记录的是事务已经提交但是数据尚未落盘的数据,一旦落盘就会从redo log中删除。而bin log是追加日志,保存的是全量修改日志。
5、通过redo日志文件保存内容,可以判断出哪些数据已经落盘。
【undo日志】
如果要进行delete和update操作,我要记录它本来的值,记录下来的信息就是undo日志,是为事务的一致性操作准备的。然后在一堆的undo日志里,需要分配一个事务id,事务可以分为两种,只读和读写,只读事务不可以对普通的用户表,就是create table这些表进行增删改查,但是可以对用户的临时表进行增删改查,比如create tempory table,在事务创建过程中,创建的临时表。
【事务】
begin开始一个事务,只有事务中出现了对表的增删改的时候,才会分配事务ID。delete操作对应的undo日志 TRX_UNDO_DEL_MARK_REC,Page Header里包含Page_Free垃圾链表,delete操作的第一步:在page header里面有个delete mask标记,未删除的标为0,已删除的标为1,会产生一条undo日志,第二步:当事务commit提交之后,便会将该记录放到page free垃圾链表里,这时数据才会被真正删除。这个过程称为合并过程。
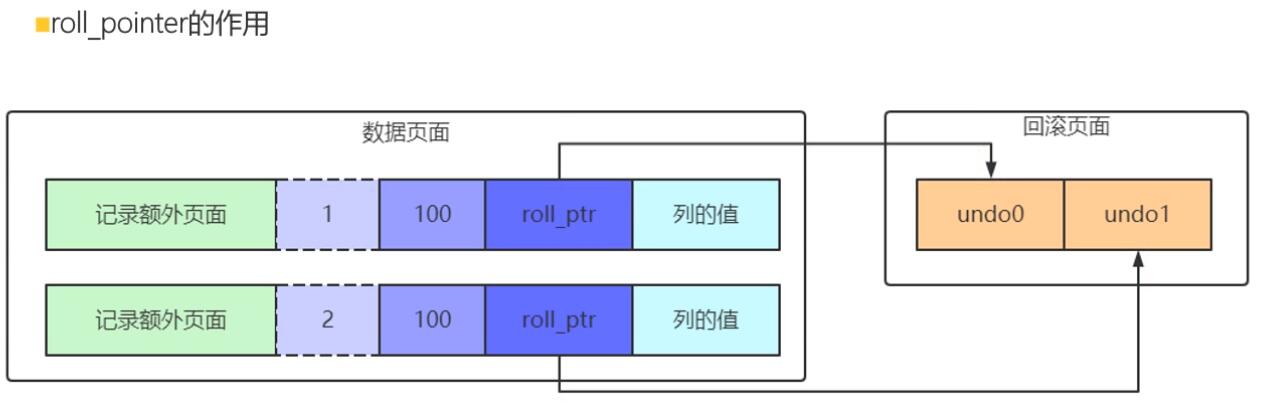
【MVCC】Multi-Version Concurrency Control
行格式里有个roll_ptr回滚指针,会指向trx_id事务id,而trx_id又会指向undo log,这样就形成了一个回滚链。MVCC只对普通的select查询生效。
那我们再讲讲MVCC里的版本链:
【版本链】
比如我们要插入一行数据:number(主键) = 1, name = Mark, password = mypassword 那么行存储格式大概如下:
| 1 (列1值) | myname (列2值) | mypassword (列3值) | trx_id (事务ID) | roll_ptr (回滚指针) |
现在回滚指针指向了insert undo,那么insert undo有一条记录了,此后事务1做了两次update,事务2做了两次update,在都未提交的情况下,就会形成一个版本链:

【Read View】
每个事务都会产生一个Read View,简称RV,RV包含:
m_ids : 记录生产RV时,活跃的读写事务id列表
min_trx_id : m_ids 中最小事务id
max_trx_id : 系统中将要分配的下一个id值
creator_trx_id : 生成RV(Read View)的事务id,就是创建RV的事务
假如我们现在有3个事务,那么m_ids = 1,2,3 min_trx_id = 1, max_trx_id = 4, create_trx_id = 0
那么问题来了,访问某条记录时,如何判断记录的某个版本是否可见?(判断规则)
1、如果被访问版本的trx_id属性值与Read View中的create_trx_id相同,表示本条记录是自己这个事务创建的,可见。
2、如果被访问版本的trx_id属性值小于Read View中的min_trx_id值,表示访问到了比活跃事务id最小值还要小,表示不活跃了,表示已经提交了,可见。
3、如果被访问版本的trx_id属性值大于或等于Read View中的max_trx_id值,表示被访问的事务创建时间晚于自己这个事务,所以不能访问,不可见。
4、如果被访问版本的trx_id属性值在Read View的min_trx_id和max_trx_id之间,min_trx_id < trx_id < max_trx_id,就需要判断被访问的trx_id是否还在m_ids活跃事务列表里,如果不活跃了表示事务已提交可访问,如果还在表示事务还在活跃尚未提交不可访问。这个过程就是遍历版本链,一个一个找,看哪个能访问,如果一个都找不到,那么查询结果里这条记录就不可见。
5、如果某个版本的数据对当前事务不可见的话
【判断规则举例】
比如当前Read View事务是这样的: m_ids[80,120] min_trx_id = 80 max_trx_id = 121 creator_trx_id = 0,而版本链是这样的:
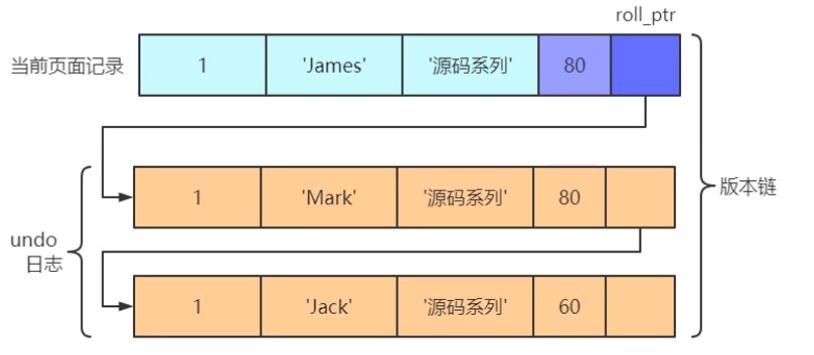
那么对应各个事务隔离级别,mysql将会读取哪一条数据呢?参考《mysql的innodb存储引擎事务隔离级别》我们来一个一个对应:
Read uncommitted 未提交读。只要m_ids活跃事务列表里有数据,就读到了,所以会出现脏读。
Read committed 已提交读。在每次读取数据之前,都会生成一个Read View。因为m_ids事务活跃列表里有80,120两个尚未提交事务,所以会读取到trx_id = 60这个已提交事务行。
Repeatable read 可重复读。只在第一次读取数据时生成一个Read View。因为RV不会变,所以即使在两个update过程中有其它事务已提交,mysql仍然会以旧RV的标准永远只读到相同的那一条记录。
Serializable 可序列化。
【Read Committed 已提交读,很大程度上避免了幻读,但是在某些特殊情况下还是会产生幻读现象,举例】
| 事务1 | 事务2 |
| begin; | |
| select * from teacher where number = 35; -- 没有存在 | |
| begin; | |
| insert into teacher values(35, 'Mark2', 'ELK'); | |
| commit; | |
| select * from teacher where number = 35; -- 依然查不到 | |
| update teacher set domain = 'mysql' where number = 35; | |
|
select * from teacher where number =35; -- 查到了,出现了幻读! 那为什么这里出现了幻读?是因为当上一条update sql时的trx_id是本事务id,所以这个值就这样被特殊的读到了。 |
|
| commit; |
end.


