
mysql5.7版本的explain解析
《为什么数据库中要使用B+tree索引,而不用hash索引?MySQL中的B+tree索引介绍》
看完以上这篇文章,明白B+tree索引结构,对explain解析更有帮助。
MySQL官网doc文档: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
一、建立 t_user 表并建立3个B+tree索引
先在mysql中建个表:
crete table t_user (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(36) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,
`age` int(4) NOT NULL DEFAULT 20,
`birthday_date_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`remark` varchar(36) CHARACTER SET latin1 COLLATE latin1_swedish_ci NULL DEFAULT NULL,
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`version` int(4) NOT NULL DEFAULT 0,
PRIMARY UNIQUE INDEX `idx_name`(`username`) USING BTREE,
`idx_age_remark`(`age`, `remark`) USING BTREE,
INDEX idx_create_time(create_time) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = DYNAMIC;
这个DDL创建了 4 个B+tree索引,我都用黄色背景标出来了。用同样的DDL语句再复制一个t_user2表。
现在开始使用explain对各种查询进行分析:
二、Explain解析SQL
重点:explain只认select关键字,每出现一次select,就生成一个id。所以如果有子查询或者union之类的,会生成多个id。
| select_type | table | Extra | |||
| 值 | 解释 | 值 | 解释 | No tables used | 当SQL中没有from子句时 |
| SIMPLE | 简单的select 查询,不使用 union 及子查询 | system |
当表只有一行记录(等于系统表),并且存储引擎像MyISAM在统计表数据时是精确的,就会出现system。 像innodb这个存储引擎在运行中就不会精确统计表数据(这里当然不是指select count(*)这种)。 这是const类型的特列,平时不会出现,这个也可以忽略不计。 |
Impossible WHERE | 当SQL中的where 条件永远为false时 |
| PRIMARY | 最外层的 select 查询 | const | 根据主键或者唯一二级索引列与常数进行等值匹配时 | no matching row in const table | 当查询列表处有MIN或者MAX聚集函数,但是并没有符合WHERE子句中的搜索条件的记录时,将会提示该额外信息 |
| UNION | UNION 中的第二个或随后的 select 查询,不 依赖于外部查询的结果集 | eq_ref | 主键索引(primary key)或者非空唯一索引(unique not null)等值扫描 | Using index | 当使用到覆盖索引时 |
| UNION RESULT | UNION 结果集,临时表。物化表,是结果缓存内存,临时表。 | ref | 当使用普通二级索引(不包含唯一索引)与常量进行等值匹配时 | Using index condition | 索引条件下推 |
| SUBQUERY | 子查询中的第一个 select 查询,不依赖于外 部查询的结果集。 | ref_or_null | 有时候我们不仅想找出某个二级索引列的值等于某个常数的记录,还想把该列的值为NULL的记录也找出来 | Using where | 需要使用where后面的条件一行行过滤。比如全表扫描,比如回表后又用了where其他条件过滤 |
| DEPENDENT UNION | UNION 中的第二个或随后的 select 查询,依赖于外部查询的结果集 | index_merge | 一般情况下对于某个表的查询只能使用到一个索引,在某些场景下可以使用索引合并的方式来执行查询:比如主键列范围查询,或者其他二级索引等值匹配。 | Using join buffer | 在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫join buffer的内存块来加快查询速度 |
| DEPENDENT SUBQUERY | 子查询中的第一个 select 查询,依赖于外部查询的结果集 | unique_subquery | 当使用in到子查询时,而且in的对象是一个主键时 | Not exists | 当我们使用左(外)连接时,如果WHERE子句中包含要求被驱动表的某个列等于NULL值的搜索条件,而且那个列又是不允许存储NULL值的,那么在该表的执行计划的Extra列就会提示Not exists额外信息 |
| DERIVED | 用于 from 子句里有子查询的情况。 MySQL 会 递归执行这些子查询, 把结果放在临时表里。 这个是对派生表的物化。 | index_subquery | 当使用in到子查询时,而且in的对象是二级索引时 | ||
| MATERIALIZED | 物化子查询。这个是对子查询的物化。 | range | 当使用了 = < > BETWEEN 等比较符在索引字段上时,注意mysql会把in, like也当成一种range扫描范围的 | ||
| UNCACHEABLE SUBQUERY | 结果集不能被缓存的子查询,必须重新为外层查询的每一行进行评估,出现极少。 | index | 如果用到了覆盖索引中的第二列或以上去select第一列,不需要回表,就是index | ||
| UNCACHEABLE UNION | UNION 中的第二个或随后的select 查询,属于不可缓存的子查询,出现极少。 | ALL | 全表扫描(full table scan) | ||
| 总结:通过某个小查询的select_type属性,就知道了这个小查询在整个大查询中扮演了一个什么角色。 | 总结:
执行计划的一条记录就代表着MySQL对某个表的执行查询时的访问方法/访问类型,其中的type列就表明了这个访问方法/访问类型是个什么东西,是较为重要的一个指标,结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL 一般来说,得保证查询至少达到range级别,最好能达到ref。 回表:回表是个典型的随机IO,能不回表就不回表,尽量使用主键索引、二级覆盖索引查询。 |
||||
三、EXPLAIN的select_type列例子
3.1 select_type = SIMPLE
简单的select 查询,不使用 union 及子查询。 EXPLAIN select * from t_user;

3.2 select_type = PRIMARY 或 UNION 或 UNION RESULT
EXPLAIN select * from t_user union select * from t_user;

3.3 select_type = SUBQUERY
EXPLAIN select * from t_user where id in ( select id from t_user2 ) or age = 40;

3.4 select_type = DEPENDENT SUBQUERY 或 DEPENDENT UNION
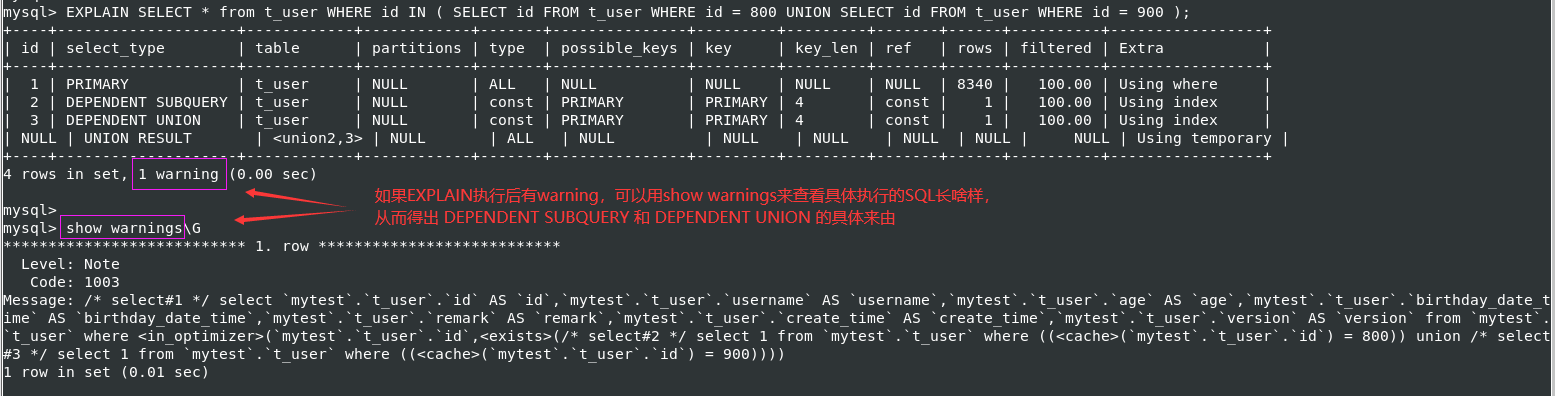
EXPLAIN warning 查看的例子也包含其中。 EXPLAIN select * from t_user where id in ( select id from t_user where id = 800 union select id from t_user where id = 900 );
3.5 select_type = DERIVED
EXPLAIN select * from ( select id, count(*) as c from t_user2 group by id ) t_derived where c > 1;

3.6 select_type = MATERIALIZED
EXPLAIN select * from t_user where age in ( select age from t_user2 );

这里的<subquery2>是子查询的结果集临时表名,外面的select查询和这个子查询结果集物化表,做了一个关联查询,所以两个id都是1.
3.7 select_type = UNCACHEABLE SUBQUERY
这种情况主要是指用了什么变量,MySQL无法缓存该SQL,出现场景极少。
set @myid = 1043; EXPLAIN select * from t_user where id = ( select id from t_user2 where id = @myid );

四、EXPLAIN的table列例子
4.1 table = system
这里没有例子。。。
4.2 table = const
根据主键或者唯一二级索引列与常数进行等值匹配时。 EXPLAIN select * from t_user where id = 1888;

4.3 table = eq_ref
这个t2是驱动表,t1是被驱动表。就像是订单表(驱动表)和订单详情表(被驱动表),一般订单表里有一条记录,而订单详情表有N条记录。
如果对这个被驱动表的访问方式,是通过等于id主键或二级唯一索引这种等值比较,则是eq_ref
EXPLAIN select * from t_user t1 inner join t_user2 t2 on t1.id = t2.id;

4.4 table = ref
EXPLAIN select * from t_user t1 where age = 50; 通过普通的二级索引查询。当使用普通二级索引(不包含唯一索引)与常量进行等值匹配时

4.5 table = ref_or_null
有时候我们不仅想找出某个二级索引列的值等于某个常数的记录,还想把该列的值为NULL的记录也找出来。
EXPLAIN select * from t_user t1 WHERE username = 'c7c70eca-903b-44b7-9a76-b3286bfa1d3a' or username is null;

4.6 table = index_merge
EXPLAIN select * from t_user t1 WHERE username = 'c7c70eca-903b-44b7-9a76-b3286bfa1d3a' or age = 10; 使用索引合并的方式查询,但是一般情况下只会使用到一个二级索引

4.7 table = unique_subquery
EXPLAIN select * from t_user t1 WHERE t1.ID IN (SELECT t2.ID FROM t_user2 t2 WHERE t1.create_time = t2.create_time) or username = 'c7c70eca-903b-44b7-9a76-b3286bfa1d3a';
当使用in到子查询时,而且in的对象是一个主键时,就会出现unique_subquery。这个例子中使用 show warnings/G 可以看到mysql把in优化成了exists

4.8 table = index_subquery
EXPLAIN select * from t_user t1 WHERE t1.username IN (SELECT t2.username FROM t_user2 t2 WHERE t1.create_time = t2.create_time) or username = 'c7c70eca-903b-44b7-9a76-b3286bfa1d3a';
当使用in到子查询时,而且in的对象是一个二级索引时,就会出现index_subquery

4.9 table = range
EXPLAIN select * from t_user where age BETWEEN 15 and 18; 当使用了 = < > BETWEEN 等比较符在索引字段上时,注意mysql会把in, like也当成一种range扫描范围的
EXPLAIN select * from t_user where username like 'a%';


4.10 table = index
EXPLAIN select age from t_user where remark = 15; 因为有个联合索引 idx_age_remark(age,remark) 所以这里用了remark列,然后只查询了age列,这两个列都是这个联合二级索引里的列,就成了索引覆盖,不需要回表,所以这个查询就是index,如果倒过来where age然后select remark的话就是ref 级别了。

4.11 table = ALL
EXPLAIN select * from t_user; 不带任何条件,就是全表扫描

五、EXPLAIN的possible_keys 与 key
possible_keys是可能用到的索引,key是实际用到的索引。 EXPLAIN select username from t_user where create_time = '2021-06-02 08:19:14' and username like 'bbb%';

在下面这个例子中,可能用到的索引没有,但实际用到了索引idx_age_remark,因为我们存在一个二级联合索引 idx_age_remark(age, reamrk)。
EXPLAIN select age from t_user where remark = 10;

六、EXPLAIN的key_len
key_len表示用到的索引长度值。 EXPLAIN select * from t_user where id = 10; 这里用到id主键,由于主键时 int(11) 所以是int是定长4个字节。

但是在varchar列中,需要看该列的字符集长度,是不定长的。
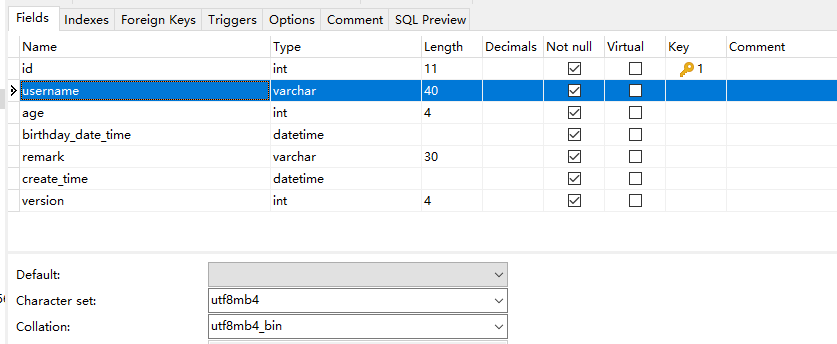
比如这里用的utf8mb4是4个字节,这里Length是40,就是 40 * 4 = 160,再加上varchar需要是否为空的标记和长度信息,共占用2个字节,所以这里是162字节:
EXPLAIN select age from t_user where username like 'c7%';

username列在db里的设计截图,是varchar(40)
数据类型本身占字节长度:
int(11) 4个字节。即使你写成int(1)也没用,仍然是占用4个字节
tinyint(3) 1个字节。即使你写成tinyint(10)也没用,仍然是占用一个字节
timestamp 4个字节,定长。
datetime 8个字节,定长。
gbk编码为: 1个字符2个字节
utf8编码为:1个字符3个字节
utf8mb4编码为: 1个字符4个字节七、EXPLAIN的ref
当使用索引列等值匹配的条件去执行查询时,也就是在访问方法是const、eg_ref、ref、ref_or_null、unique_sutbquery、index_subopery其中之一时,ref列展示的就是与索引列作等值匹配的是谁。
EXPLAIN select * from t_user t1 WHERE id = 400; 这个例子演示的是等值匹配。

ref 这一列的值是告诉你SQL中的被比较对象,是和哪个db库的哪个表的哪个列进行比较。如下例中,就是对mytest库的t2表的id列进行比较。
EXPLAIN select * from t_user t1 INNER JOIN t_user2 t2 on t1.id = t2.id; 这个例子演示的是连接产生的等值匹配。

EXPLAIN select * from t_user t1 INNER JOIN t_user2 t2 on t1.username = UPPER(t2.username) 这个例子证明,有时候等值匹配的也可以是个函数 func

八、EXPLAIN的rows
EXPLAIN select * from t_user where age = 70; 如果查询优化器决定使用全表扫描的方式对某个表执行查询时,执行计划的rows列就代表预计需要扫描的行数,如果使用索引来执行查询时,执行计划的rows列就代表预计扫描的索引记录行数。

EXPLAIN select * from t_user where username > 'a'; 这个例子中,表总数才一万条,但是EXPLAIN预计需要扫描9815条,所以还不如全表扫描,所以 type = ALL

EXPLAIN select * from t_user where username > 'z'; 这个例子中,EXPLAIN预计需要扫描一条记录就能找到,所以走了 type = range,而不是全表扫描

九、EXPLAIN的filtered
EXPLAIN select * from t_user t1 INNER JOIN t_user2 t2 on t1.id = t2.id WHERE t1.age > 80; 这个例子中,t1表结果集预计会是总数的 20.11%,而 t2表由于是需要查找的记录全部都是确定值,所以过滤出来的数据是 100%

十、EXPLAIN的Extra
Extra的种类有几十个之多,这里只介绍几种常用的。
No tables used 当SQL中没有from子句时:EXPLAIN select 1;

Impossible WHERE 当SQL中的where 条件永远为false时:EXPLAIN select * from t_user where 1 != 1;

no matching row in const table 当查询列表处有MIN或者MAX聚集函数,但是并没有符合WHERE子句中的搜索条件的记录时,将会提示该额外信息。也就是在该例子中,username = abc的记录不存在.
EXPLAIN select min(age) from t_user where username = 'abc';

Using index 当使用到覆盖索引时 EXPLAIN select remark from t_user where age = 9;

Using index condition 索引条件下推。即当 username > 'z' 找到一条记录时,不急着回表,而是看看是不是还符合 username like '%z' ,如果符合,才回表,这就叫索引条件下推。
EXPLAIN select * from t_user where username > 'z' and username like '%a';

Using where 全表扫描。因为只能依靠where后面的条件一行行过滤 EXPLAIN select * from t_user where birthday_date_time = '1991-11-27 21:58:04';

Using where 已经使用了 age = 4 这个二级索引找到确切的数据,再回表根据 username > 'c' 这个where条件来过滤数据,这里重点是使用了where条件过滤了
EXPLAIN select * from t_user where age = 4 and username > 'c';

Using join buffer 在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫join buffer的内存块来加快查询速度
EXPLAIN select * from t_user t1 INNER JOIN t_user2 t2 on t1.birthday_date_time = t2.birthday_date_time;

Not exists 当我们使用左(外)连接时,如果WHERE子句中包含要求被驱动表的某个列等于NULL值的搜索条件,而且那个列又是不允许存储NULL值的,那么在该表的执行计划的Extra列就会提示Not exists额外信息
EXPLAIN select * from t_user t1 LEFT JOIN t_user2 t2 on t1.username = t2.username where t2.id is null;

Using intersect(...) 交集合并、Using union(...) 并集合并 和 Using sort_union(...) 并集有序合并
如果执行计划的Extra列出现了Using intersect(...)提示,说明准备使用Intersect索引合并的方式执行查询,括号中的...表示需要进行索引合并的索引名称;如果出现了Using union(...)提示,说明准备使用Union索引合并的方式执行查询;出现了Using sort_union(...)提示,说明准备使用Sort-Union索引合并的方式执行查询。
Zero limit 当我们的LIMIT子句的参数为0时,表示压根儿不打算从表中读出任何记录,将会提示该额外信息。比如 limit 0;
Using filesort 当出现这个,说明SQL执行慢,比如 select * from t_user order by update_time asc limit 10; 这个排序就没用到索引列。再比如 select * from t_user order by username limit 10; 像这种情况下对结果集中的记录进行排序是可以使用到索引的。
Using temporary 临时表。在许多查询的执行过程中,MySQL可能会借助临时表来完成一些功能,比如去重、排序之类的。
EXPLAIN select DISTINCT remark from t_user;

Using temporary与Using filesort同时出现,是因为mysql在处理group by中默认加上了order by,因为只有排序,才能分组。但是因为默认加了order by会导致消耗性能,所以可以自己加上order by null; 这样手动处理后可以省去Using filesort这一步。
EXPLAIN select birthday_date_time,count(*) from t_user GROUP BY birthday_date_time;

十一、EXPLAIN的 json格式,查看更具体的cost耗时信息
想查看explain的里更具体的cost耗时信息,参考《mysql5.7版本explain解析,使用format=json查看cost耗时详细信息》
其他知识
1)UNION关键字连接
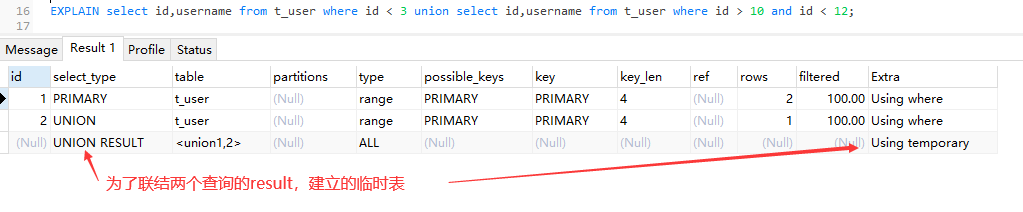
union关键字会创建一张临时表,但是union all就不会创建一张临时表,因为:union all 的结果集不用去重!!!
EXPLAIN select id,username from t_user where id < 3 union select id,username from t_user where id > 10 and id < 12;
end.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号