

为什么数据库中要使用B+tree索引,而不用hash索引?MySQL中的B+tree索引介绍
Hash索引的查找速度很快,几乎是O1的,但是为什么不适用 HashMap 来做数据库索引呢?
1、区间值难找。因为单个值计算会很快,而找区间值,比如 100 < id < 200 就悲催了,需要遍历全部hash节点。
2、排序难。通过hash算法,也就是压缩算法,可能会很大的值和很小的值落在同一个hash桶里,比如一万个数压缩成1000个数存到hash桶里,也就是会产生hash冲突。
MySQL的InnoDB存储引擎支持以下常见索引:B+tree索引(最关键)、全文索引、Hash索引(内部)
二叉树、二叉查找树
B+tree是通过二叉查找树,再由平衡二叉树,B树演化而来。一个int有序数组转化为二叉查找树示例图,取最中间值作为第一节点:
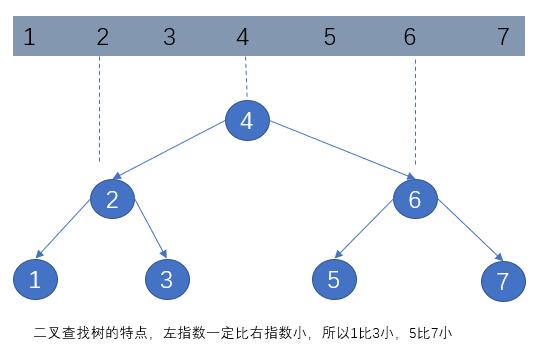
在二叉查找树设计不良的情况下,可能会产生极端情况,就是只存在右指数的情况,这时查找效率反而会降低。这时为了提高性能,就产生了平衡二叉树(AVL树)概念,也就是两个指数的之间的高度差不能大于1.
所有的节点都有,称之为满二叉树。
二叉查找树通过左旋右旋,能够很好的实现平衡二叉树,但是为什么不使用二叉树来作为mysql的索引呢?因为二叉树在数据量大的情况下会太高!而磁盘的每次IO时间需要0.01秒!
B+tree索引
B-tree和B+tree和B*tree的区别?
1)B-tree的中间节点里存放:关键字、数据区、子节点引用。
而B+tree的中间节点没有数据区,B+tree会在底层的叶子节点中才会放数据。
2)B+tree的叶子节点存放数据,而叶子节点也会多一个指针,指向下一个叶子节点。
3)B+tree只是叶子节点有个指针指向下一个叶子节点,而B*tree连中间索引节点都有个指针指向下一个中间索引节点。(oracle里用的是B*tree)
B-tree和B+tree都是一种平衡树,不会产生极度倾斜的情况,而且数据的存储都是有序的。
新增数据时,叶子节点满的情况下,会分裂出叶子节点,把原叶子节点的中间数据提到上一层。
删除数据时,叶子节点会萎缩,可能会层层萎缩。
B-tree和B+tree又被称为多路查找树,或者多叉平衡查找树。
重点:B+tree每个节点的叶子节点是多个,而二叉树每个节点的叶子节点都是2个,所以B+tree的节点高度远低于二叉树。
MySQL官方innodb存储引擎doc文档: https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html
索引使用案例
联合索引设计时,比如:CREATE INDEX idx_name_age_address ON t1 (name, age, address) 则在B+tree里存放的每个索引节点有3行,第一行按照name顺序排列,第二行按照name值相同的情况下age顺序排列,第三行按照name值相同age值也相同的情况下address顺序排列。所以联合索引使用最左原则就是这个原理。
根据上述原理,select age from t1 where name = 'zhangsan' 这个SQL要查询的age值刚好是name联合索引里的第二行索引,就不需要再回表到主键索引去查,直接从联合索引里取值即可,这被称为索引覆盖。
回表: 回表是典型的随机IO,能尽量不回表就不回表,尽量使用主键索引或者二级覆盖索引这类查询。
MySQL索引使用例子,参考《mysql5.7版本的explain解析》
end.


