《机器学习》周志华 习题答案4.3
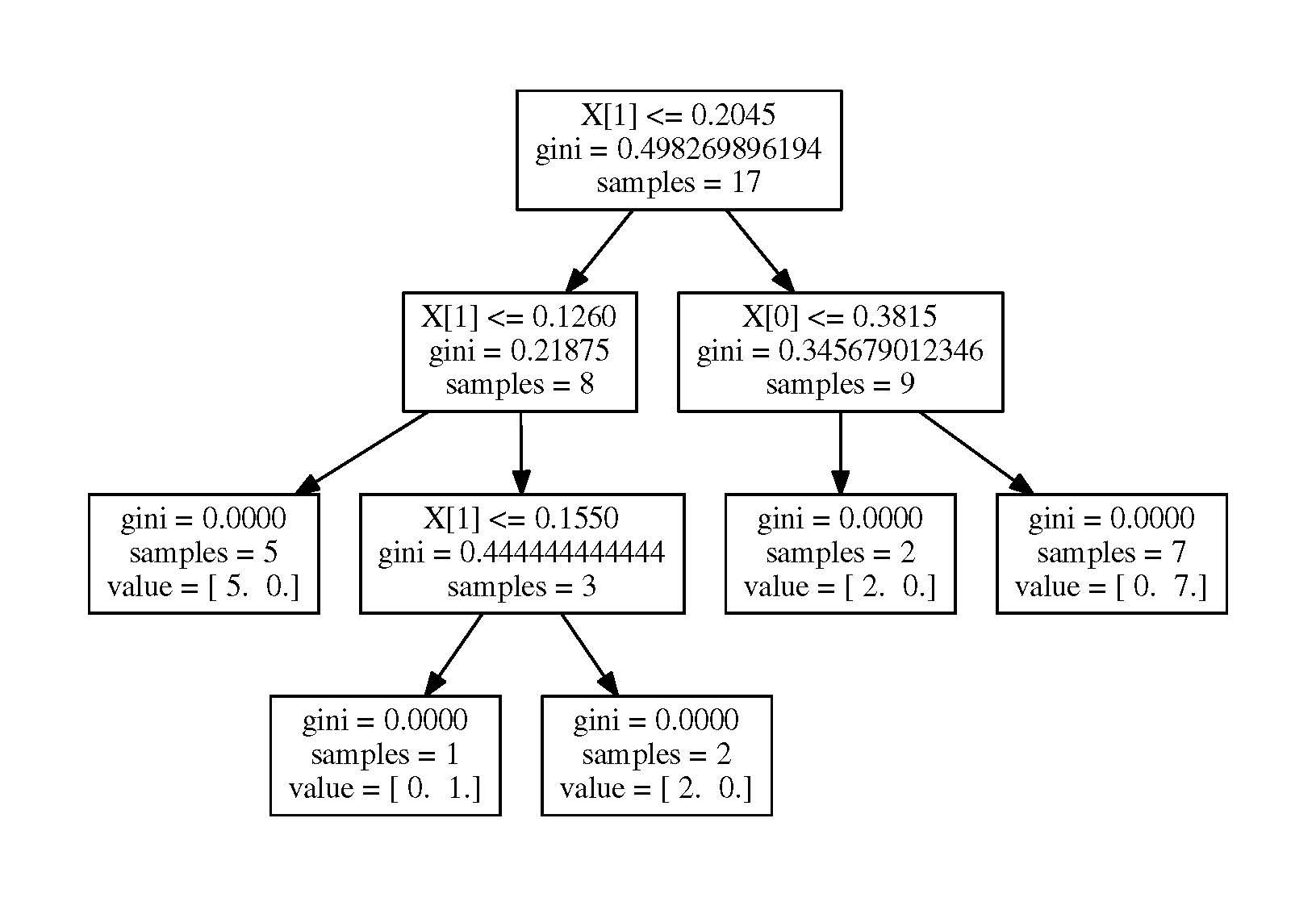
原题,对西瓜数据集用决策树来进行划分,此处我只选取了西瓜的密度和含糖率这两个连续属性来进行划分,
#!/usr/bin/python # -*- coding:utf-8 -*- import numpy as np import matplotlib.pyplot as plt from matplotlib import colors from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis file1 = open('c:\quant\watermelon.csv','r') data = [line.strip('\n').split(',') for line in file1] X = [[float(raw[-3]), float(raw[-2])] for raw in data[1:]] y = [1 if raw[-1]=='1' else 0 for raw in data[1:]] X = np.array(X) y = np.array(y) print y #######################################################################以上是西瓜 from sklearn.datasets import load_iris from sklearn import tree from sklearn.externals.six import StringIO import pydot iris = load_iris() clf = tree.DecisionTreeClassifier() clf = clf.fit(iris.data, iris.target) #with open("iris.dot", 'w') as f: # f = tree.export_graphviz(clf, out_file=f) filename = "iris.pdf" dot_data = StringIO() tree.export_graphviz(clf, out_file=dot_data) graph = pydot.graph_from_dot_data(dot_data.getvalue()) print graph graph.write_pdf(filename)
结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号