

C# start with connect by prior 递归查询用法
create table a_test
( parentid varchar2(10),
subid varchar2(10));
insert into a_test values ( '1', '2' );
insert into a_test values ( '1', '3' );
insert into a_test values ( '2', '4' );
insert into a_test values ( '2', '5' );
insert into a_test values ( '3', '6' );
insert into a_test values ( '3', '7' );
insert into a_test values ( '5', '8' );
insert into a_test values ( '5', '9' );
insert into a_test values ( '7', '10' );
insert into a_test values ( '7', '11' );
insert into a_test values ( '10', '12' );
insert into a_test values ( '10', '13' );
commit;
select * from a_test;
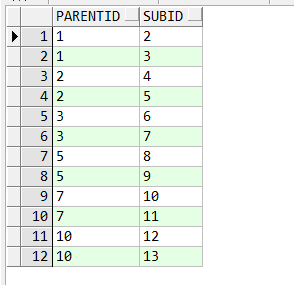
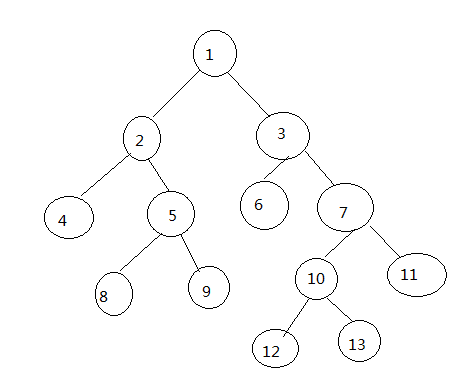
对应B树结构为:
接下来看一个示例:
要求给出其中一个结点值,求其最终父结点。以7为例,看一下代码
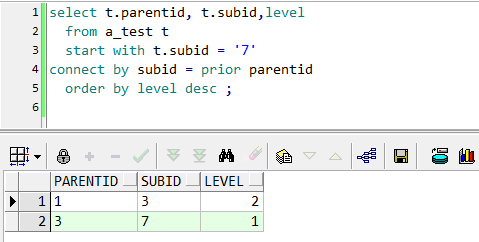
start with 子句:遍历起始条件,有个小技巧,如果要查父结点,这里可以用子结点的列,反之亦然。
connect by 子句:连接条件。关键词prior,prior跟父节点列parentid放在一起,就是往父结点方向遍历;prior跟子结点列subid放在一起,则往叶子结点方向遍历,
parentid、subid两列谁放在“=”前都无所谓,关键是prior跟谁在一起。
order by 子句:排序,不用多说。
--------------------------------------------------
下面看看往叶子结点遍历的例子:
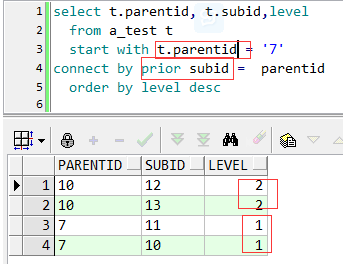
这里start with 子句用了parentid列,具体区别后面举例说明。
connect by 子句中,prior跟subid在同一边,就是往叶子结点方向遍历去了。因为7有两个子结点,所以第一级中有两个结果(10和11),10有两个子结点(12,13),11无,所以第二级也有两个结果(12,13)。即12,13就是叶子结点。
下面看下start with子句中选择不同的列的区别:
以查询叶子结点(往下遍历)为例
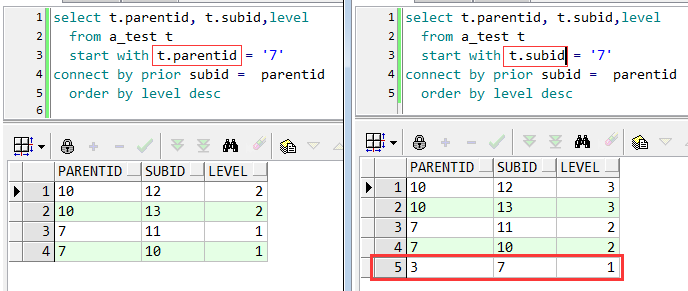
结果很明显,原意是要以7为父结点,遍历其子结点,左图取的是父结点列的值,结果符合原意;右图取的是子结点列的值,结果多余的显示了7 的父结点3.
---------------------------------------
关于where条件的语句,以后验证后再记录。先留个疑问


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗