


REDIS基础学习笔记
一. 背景说明
学习每一种新技术之前,我都会尽量提醒自己从这三个方面依次递进的去学:是什么,能干嘛?为什么用它?怎么用?
Redis是什么?一项基于分布式缓存的nosql数据库技术。能干嘛?做分布式缓存呗。
为什么用它?一般来说,每一项新技术的出现,都有其历史背景及使命(要解决的问题),技术来源于问题。为什么已经有了传统的关系型数据库,还要非关系型数据库干啥?毋庸置疑,肯定是原有的老技术有其无法避免的缺点及弊端,即使很有可能总体来说它已经很优秀了。传统的关系型数据库,如Oracle、Mysql、SQLServer、DB2,基本上都是把数据主要存放位置放在磁盘上,在一些大数据量,高并发的情况下,磁盘的读写速度已经无法满足需求了,我们迫切需要一个基于更快的物理硬件如内存的数据库。于是Redis就应运而生了。
怎么用?后面自然会说,在这之前先按正常节奏一步步的了解并同时学习用法。
二. 用法
2.1 安装和启动
首先需要注意下的是,据说Redis在Windows Server中的性能表现要比Linux中差很多。所以,条件允许的话,尽可能的选择Linux平台。如果选择了Linux平台的话,需要另外注意的一个事情是:Redis是用C语言编写的,而我们下载的Redis一般源码安装程序,所以在这之前你需要确保系统里有合适的编译器。gcc或gcc-c++都行,我的系统(CentOS7)里是之前自己都安装了:
[root@qingxin ~]# rpm -qa gcc*
gcc-4.8.5-28.el7_5.1.x86_64
gcc-c++-4.8.5-28.el7_5.1.x86_64
没有的话先自行安装下:
yum install gcc gcc-c++
环境都准备好了之后就可以用下载下来的文件开始安装了:
解压
[root@qingxin software]# tar -zxvf redis-4.0.9.tar.gz
进入到解压出来的目录里面,编译
[root@qingxin redis-4.0.9]# make
安装到指定目录
[root@qingxin redis-4.0.9]# make PREFIX=/usr/local/redis-4.0.9/ install
复制配置文件到安装目录
[root@qingxin redis-4.0.9]# cp redis.conf /usr/local/redis-4.0.9/bin/
到这里我们的Redis安装基本就算完成了,接下来可以尝试启动Redis了。
关于Redis的启动主要是要知道两种启动方式:前端启动和后端启动。Redis默认使用前端启动方式,这样当你运行redis-server启动了之后,它会一直卡在哪里,必须另外开一个session使用redis-cli去访问它,这样挺麻烦的。所以推荐后端启动方式:修改redis.conf配置文件,把daemonize由no改成yes,这样redis-server就可以在后台跑着了。(为了方便建议将Redis安装目录加入PATH里)
[root@qingxin bin]# redis-server redis.conf
检查是否启动成功:
[root@qingxin bin]# ps -aux|grep redis-server
访问直接使用redis-cli,带密码的话使用-a参数。关闭也是使用redis-cli,只是多加一个shutdown。
2.2 Jedis的使用
Redis本身的使用来讲主要就是一堆命令。在说哪些之前,先说说Jedis。Jedis对于redis就类似于JDBC于Mysql、Oracle。都是对数据库访问的接口,在Java中要想直接操作数据库都需要通过这类接口。
- 单实例连接
首先说明下,因为还没说其他数据类型,所以暂时只用String类型的做测试。这一个和下一个例子我们只引入jedis,commons-pool,junit做测试:
单实例连接比较简单,做完之后,我们会看下使用连接池方式怎么写。
package com.zqx;
import org.junit.Test;
import redis.clients.jedis.Jedis;
public class TestJedis {
@Test
public void testJedisSingle(){
Jedis jedis = new Jedis("192.168.15.142",6379);
jedis.set("username","zqx");
String user = jedis.get("username") + "," + jedis.get("country");
System.out.println(user);
jedis.close();
}
}
这里需要注意,因为我这里的测试程序是跑在windows系统里的。而我的redis-server运行在我的Linux虚拟机里,所以要想看到测试效果,需要先确保能从windows访问到虚拟机里的redis。要做到这一点,需要注意两个问题:
一. redis.conf里的bind项改成0.0.0.0以让任意IP都能访问
二. Linux的防火墙开启对redis默认6379端口的访问,
[root@qingxin bin]# iptables -A INPUT -ptcp --dport 6379 -j ACCEPT
因为centosos7默认使用firewalld管理了,我的系统是centos7的,所以用下面这个
[root@qingxin bin]# firewall-cmd --permanent --zone=public --add-port=6379/tcp
改完记得重启一下服务:
[root@qingxin bin]# systemctl restart firewalld
或
[root@qingxin bin]# service iptables restart
做完这些本地测试下能否正常连接:
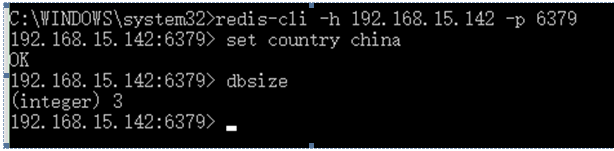
代码测试结果:

验证一下数据是否写入到redis-server了:

-
连接池连接
连接池方式可以实现对连接的共享和复用,以提高连接资源的利用率。@Test public void testJedisPools(){ JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); //最大连接数 jedisPoolConfig.setMaxTotal(30); //最大连接空闲数,即使没有任何连接也可以保留的连接数 jedisPoolConfig.setMaxIdle(2); JedisPool jedisPool = new JedisPool(jedisPoolConfig,"192.168.15.142",6379); Jedis jedis = null; try{ jedis = jedisPool.getResource(); jedis.set("username1","zhuqingxin"); String user1 = jedis.get("username1")+","+jedis.get("country"); System.out.println(user1); }catch (Exception e){ throw e; }finally { if(jedis != null){ jedis.close(); } } }
测试结果:

验证一下写入是否成功:

-
整合Spring
首先第一步肯定是把Spring核心该导的包都导入进来了:

然后就可以写测试代码做测试了:
ApplicationContext.xml<!-- 连接池配置 --> <bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig"> <!-- 最大连接数 --> <property name="maxTotal" value="30" /> <!-- 最大空闲连接数 --> <property name="maxIdle" value="10" /> <!-- 每次释放连接的最大数目 --> <property name="numTestsPerEvictionRun" value="1024" /> <!-- 释放连接的扫描间隔(毫秒) --> <property name="timeBetweenEvictionRunsMillis" value="30000" /> <!-- 连接最小空闲时间 --> <property name="minEvictableIdleTimeMillis" value="1800000" /> <!-- 连接空闲多久后释放, 当空闲时间>该值 且 空闲连接>最大空闲连接数 时直接释放 --> <property name="softMinEvictableIdleTimeMillis" value="10000" /> <!-- 获取连接时的最大等待毫秒数,小于零:阻塞不确定的时间,默认-1 --> <property name="maxWaitMillis" value="1500" /> <!-- 在获取连接的时候检查有效性, 默认false --> <property name="testOnBorrow" value="true" /> <!-- 在空闲时检查有效性, 默认false --> <property name="testWhileIdle" value="true" /> <!-- 连接耗尽时是否阻塞, false报异常,ture阻塞直到超时, 默认true --> <property name="blockWhenExhausted" value="false" /> </bean> <!--配置 jedisPool --> <bean id="jedisPool" class="redis.clients.jedis.JedisPool" destroy-method="close"> <constructor-arg name="poolConfig" ref="jedisPoolConfig"></constructor-arg> <constructor-arg name="host" value="192.168.15.142"/> <constructor-arg name="port" value="6379"/> </bean>
这种东西还是建议本地保存一份,用的时候copy过来改改就能用了。
TestSpringJedis.java
package com.zqx;
import org.junit.Before;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
public class TestSpringJedis {
private ApplicationContext applicationContext;
@Before
public void init(){
applicationContext = new ClassPathXmlApplicationContext("classpath:ApplicationContext.xml");
}
@Test
public void testJedisPool(){
JedisPool pool = (JedisPool) applicationContext.getBean("jedisPool");
Jedis jedis = null;
try{
jedis = pool.getResource();
jedis.set("username2","11242");
String user2= jedis.get("username2") + "," + jedis.get("country");
System.out.println(user2);
}catch (Exception e){
throw e;
}finally {
if (jedis!=null){
jedis.close();
}
}
}
}
测试结果:

验证一下写入是否成功:

另外,说一下,这里的连接和连接池你不关闭,Spring也会帮你关的。
好的,到这里,Jedis的基础用法就差不多了,下面看看Redis的数据类型。
2.3 Redis数据类型
总的来说,Redis有5种数据类型:
String 字符串
list 列表
hash 哈希
set 集合 无序且不允许重复
zset 有序集合 有序不允许重复
这里我们不扣概念,重点关注命令怎么用。
- String类型
其实我们前面一直用的就是String,主要就是用了set,get命令。再总的走一遍:
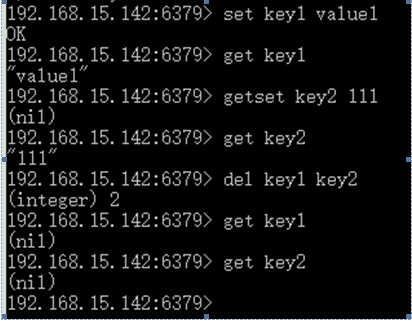
Set是赋值,get是取值。getset是先取当前值,再赋值。Del是删除,更新就再set一次。
除了这些还有一些实用的命令
递增递减(incr,decr,incrby,decrby):

追加(append):

获取长度(strlen):

同时设置获取多个值(mset,mget):

2 Hash类型
Hash表类似于关系型数据库里的一条记录。一条记录对应一个Hash类型的key,下面可以有多个属性。

基本的hget,hset获取设置单个field值,hmget,hmset操作多个属性。Hgetall获取所有属性,hdel删除一个或多个属性。其他还有hkeys,hvals只获取key,只获取值。

3 List类型
Redis里面的list类似于LinkedList,就像一个双向循环链表。这个时候对其添加和删除的操作就有几种区别,在表头插入,表尾插入,表头删除,表尾删除。或者其实按它的实际命令来看,我们可以也可以把它看成一个双向栈,对应的操作就变成了正向入栈,反向入栈,正向出栈,反向出栈了。
192.168.15.142:6379> lpush lkey1 1 2 3
(integer) 3
192.168.15.142:6379> lrange lkey1 0 -1
1) "3"
2) "2"
3) "1"
192.168.15.142:6379> rpush lkey1 4 5 6
(integer) 6
192.168.15.142:6379> lrange lkey1 0 -1
1) "3"
2) "2"
3) "1"
4) "4"
5) "5"
6) "6"
192.168.15.142:6379> llen lkey1
(integer) 6
基础命令就是lpush,rpush,对应正向入栈,反向入栈。对应的出栈操作就是lpop,rpop,都是类似的就不演示了,llen可以获取总数,还有lrem可以移除元素。其实到这里已经能发现,redis的命令不少,全部记下来也不容易,但就和学linux命令一样,我们很多时候还是需要用到什么查什么,但是基本的一些命令还是最好能记下来。
需要注意一下的是lrange,我试了下redis里list好像只能正向遍历,没有rrange的说法。lrange的用法,需要自己去试下就明白了,我总结起来是:
格式: lrange key start end
end为负数表示逆向遍历,此时start也为负数且小于end,则按顺序遍历下来。
为负数还大于end则取不到元素,为正数则两边按自己的索引规则来
最常用的是: lrange key 0 -1取所有的元素。
1.1.3.4 Set和Zset类型
这里有个问题先记一下:redis会自动把中文转为Unicode存储。
Set表示无序集合,ZSet表示有序集合,Zset多一个score的概念。
192.168.15.142:6379> sadd skey1 1 2 3 4 5
(integer) 5
192.168.15.142:6379> smembers skey1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
192.168.15.142:6379> sadd skey1 1 3 4
(integer) 0
192.168.15.142:6379> smembers skey1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
192.168.15.142:6379> sismember skey1 3
(integer) 1
192.168.15.142:6379> sadd skey2 3 4 6 7
(integer) 4
192.168.15.142:6379> sdiff skey1 skey2
1) "1"
2) "2"
3) "5"
192.168.15.142:6379> sinter skey1 skey2
1) "3"
2) "4"
192.168.15.142:6379> sunion skey1 skey2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
192.168.15.142:6379>
Sadd添加,srem移除。Smembers查看所有,sismember判断是否存在某元素。Sdiff取差集,sinter取交集,sunion取并集。下面继续简单说下下有序集合的用法,不再演示:
zadd zkey1 10 zhangsan 20 lisi 30 wangwu 往有序集合里面添加元素
zrange zkey1 0 -1 查看有序集合所有元素
zrem zkey1 wangwu
zrange zkey1 0 -1 withscores 带分数(排名)的查看元素
zrevrange zkey1 0 -1 withscores 带分数的降序(从大到小)查看元素
可以看到redis数据类型相关命令很多,但也很简单很类似。关键在于自己去试,去查。
4 Redis通用命令
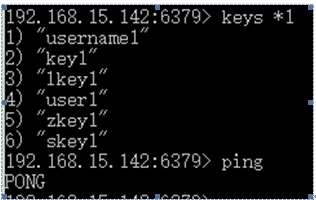
只说两个:keys 和 ping。
Keys可以使用通配符实现模糊查询,ping可以检查redis-server是否挂掉。
2.4 Redis持久化及主从复制
-
两种持久化方式
RDB:
间隔固定时间去持久化一次
速度较快
AOF:
实时保存
大大拖慢redis系统的速度,比较鸡肋。适用于特定情形。
使用方法:
修改配置文件,redis.conf 。 默认的rdb模式,存储的数据都在dump.rdb文件里面。
配置文件里appendonly 项为 no . 使用aof模式,把它改成yes,数据默认保存在
appendonly.aof文件里面。然后重启一下就行了:./redis-server redis.conf -
主从复制
和前面说的两种持久化方式相关,因为aof模式不适合主从复制,只适用于rbd模式。
备份原理:从服务器发送sync请求命令,主redis发生dump.rdb文件,已经当前未持久化的缓存中所有写命令,这样就能保证主从一致。这种方式不适应与aof模式。从redis使用ping命令,遵从心跳机制,检测主redis是否挂掉了,如果挂掉,则从redis临时顶替,且从redis此时默认是只读的,以保证主从一致。
用法演示:
在同一台机器上模拟,把dump.rdb文件先删掉或备份出来,保证没有历史数据。拷贝一份redis出来,主redis不需要做更改,从redis的配置文件里,port修改一下避免冲突,另外取消slaveof项的配置,设置要同步那个主服务器。此时,先启动主redis,后启动从redis,在主redis里面设置一些key,然后shutdown掉。进入从redis-cli,看看主redis里面set过的key是否能够get以验证备份是否正常。
