

PyTorch图像分类全流程实战--图像分类可解释性06
教程
-
代码运行云GPU平台:https://featurize.cn/?s=d7ce99f842414bfcaea5662a97581bd1
-
DFF https://jacobgil.github.io/pytorch-gradcam-book/Deep Feature Factorizations.html
可解释性分析方法
1. torch-cam工具包、torch-grad-cam工具包,热力图
使用torchcam算法库,对图像进行各种基于CAM的可解释性分析。
from torchcam.methods import SmoothGradCAMpp
# CAM GradCAM GradCAMpp ISCAM LayerCAM SSCAM ScoreCAM SmoothGradCAMpp XGradCAM
cam_extractor = SmoothGradCAMpp(model)
#生成可解释性分析热力图
activation_map = cam_extractor(pred_id, pred_logits)
activation_map = activation_map[0][0].detach().cpu().numpy()
最后得到一个热力图,盖在原图上显示,得到高亮的区域,即为分类特征区域。
from torchcam.utils import overlay_mask
result = overlay_mask(img_pil, Image.fromarray(activation_map), alpha=0.7)

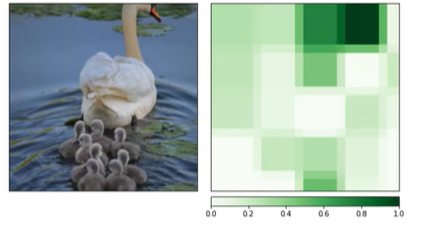
2. DFF图像子区域可解释性
concept 个数对应图块颜色个数
top_k 每个概念展示几个类别

3. Captum 遮挡可解释性分析(PyTorch官方出品)
可以进行图像分类、自然语言处理、数据集鲁棒性测试。
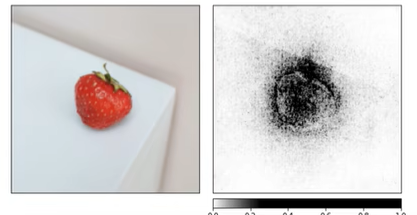
遮挡可解释性分析,用小滑块遮挡图像上不同的区域,观察哪个区域遮挡后会显著影响分类决策。
可以调整的超参数:滑块尺寸、移动步长。
颜色越深表示:遮挡此区域之后,分类效果显著降低。
以上,可以看出挡住脖子区域对分类效果影响最大,所以学习的特征主要是天鹅的脖子。
4. Integrated Gradients
加入高斯噪声后,使用smoothgrad_sq平滑,可以实现图像分割的效果。
5. GradientShap可解释性分析
是一种线性模型可解释性分析方法,使用多张参考图像解释模型预测结果。
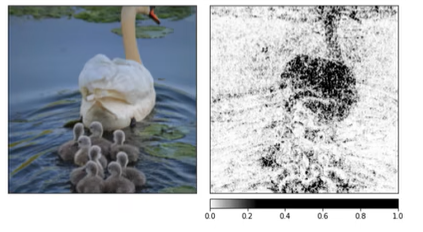
类似上个方法,也可以继续用高斯噪声平滑,效果会更加明显
6. Fearure Ablation特征消融可解释性分析
根据实例分割标注图,分别去除图像中不同语义分组区域,观察对模型预测结果的影响。
实例分割标注图中,每个类别被划为一类feature group,根据feature group 特征分组, Fearure Ablation就是分析每个feature group存在或不存在的影响。
特征消融:把这个特征组从图片上抹去,看有何影响。
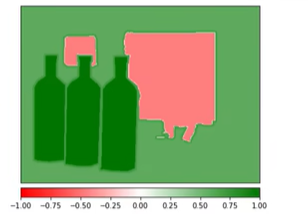
绿色最深的区域是酒瓶,抹掉对模型影响最大。显示器为红色,抹掉是对模型预测为white_bottle有正面积极影响。
7. shap工具包
基于博弈论的Shapley值实现机器学习可解释性分析,计算每个数据、每个特征,对模型每类预测结果的Shapley值,反映边际贡献(特征重要度)。对Pytorch预训练ImageNet图像分类模型、自己训练得到的30类水果图像分类模型,进行可解释性分析,可视化指定预测类别的shap值热力图。

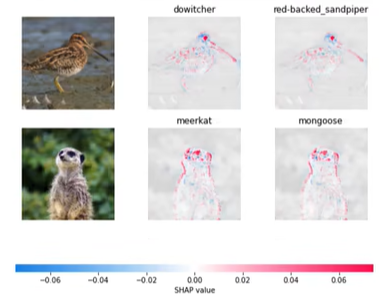
可以看出,模型浅层输出的显著性分析图,虽然具有细粒度、高分辨率,但不具有类别判别性。而模型深层输出的显著性分析图,虽然分辨率低,但具有类别判别性。
所以现在的研究热点主要是如何既保证分辨率,又具有类别判别性。如下图,但是代价是消耗更多的计算资源。

8. lime可解释性工具包
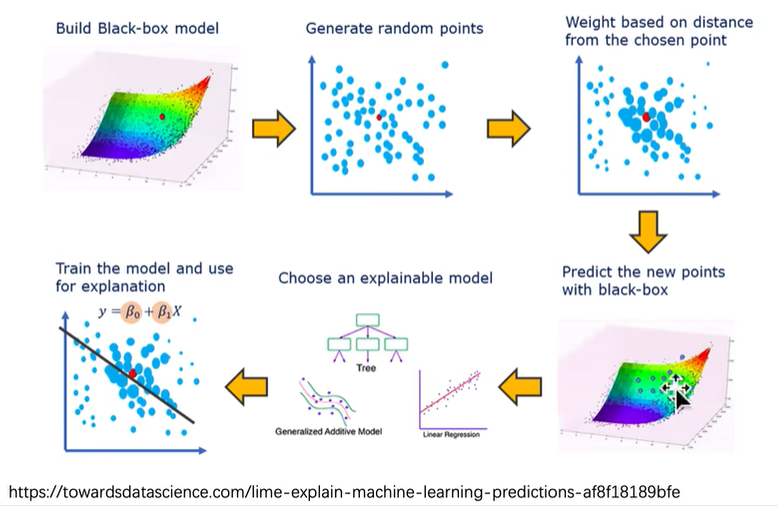
把待测样本生成许多邻域样本,也放入模型进行预测,把邻域样本做一个简单的线性模型进行拟合,在局部拟合出原模型的行为,并可以反映待测样本的重要度以及对模型的贡献。所以LIME生成的领域图像个数越多,拟合出的结果越准。
主要思路:定量评估出某个样本、某个特征(图块),对模型预测为某个类别的贡献影响。
文本数据:

可以看出模型为啥预测为good,哪些特征有助于预测为good,哪些不利于预测为good。
黄色的更认为是good,蓝色的更认为是bad。
图像数据:
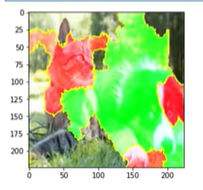
表示绿色区域对预测为牧羊犬的类别有很大的正向贡献,红色的是负向贡献。
无监督学习(unsupervised learning):已知数据不知道任何标签,按照一定的偏好,训练一个智能算法,将所有的数据映射到多个不同标签的过程。
弱监督学习(weakly supervised learning): 已知数据和其一一对应的弱标签,训练一个智能算法,将输入数据映射到一组更强的标签的过程。标签的强弱指的是标签蕴含的信息量的多少,比如相对于分割的标签来说,分类的标签就是弱标签,如果我们知道一幅图,告诉你图上有一只猪,然后需要你把猪在哪里,猪和背景的分界在哪里找出来,那么这就是一个已知若标签,去学习强标签的弱监督学习问题。
什么是监督学习、无监督学习、强化学习、弱监督学习、半监督学习、多示例学习
视频每帧画面处理思路
- 先定义一个每一帧的图像处理函数
- 用mmcv.VideiReader处理每一帧,调用图像处理函数
- 把每一帧串成视频文件
- 删除临时文件夹
摄像头实时画面处理思路
- 在本地运行,因为要调用摄像头(使用本地cpu)
- 选择快的算法:CAM
- 用摄像头拍摄一帧画面,转为RGB再转PIL
# 获取摄像头,传入0表示获取系统默认摄像头
cap = cv2.VideiCapture(1)
...
#BGR转RGB
img_rgb = cv2.cvtColor(img_bgr,cv2.COLOR_BGR2RGB)
#转Pil
img_pil = Image.fromarray(img_rgb)
- 执行前向预测
- 画热力图
- 把3-5封装成单帧的函数,从摄像头循环获取图像,并执行单帧函数


