20171114_Python学习五周二次课
今日任务:
五周二次课(11月14日)
11.1 常用正则表达式
11.2 re正则对象和正则匹配效率比较
11.3 编译正则对象
笔记:
1 常用正则表达式
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | |
| re{ n,} | 精确匹配n个前面表达式。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | G匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]. |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
正则表达式实例
字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类
| 实例 | 描述 | ||
|---|---|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 | ||
| \d | 匹配一个数字字符。等价于 [0-9]。 | ||
| \D | 匹配一个非数字字符。等价于 [^0-9]。 | ||
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 | ||
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 | ||
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 | ||
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
2.re模块
re模块是python中处理正则表达式的一个模块,通过re模块的方法,把正则表达式pattern编译成正则对象,以便使用正则对象的方法。那为什么要使用re模块来把正则表达式搞成正则对象呢,最主要的是可以提高代码的执行效率,我们来看个例子:
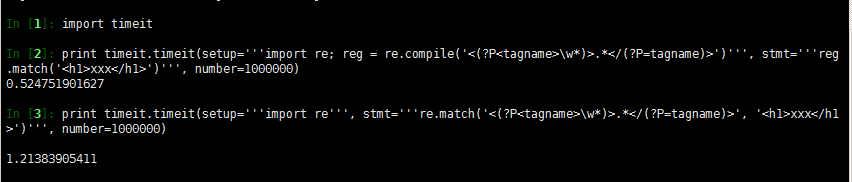
解释:timeit.timeit是用来统计程序执行的时间的,和明显第一个print的执行时间要比第二个的执行时间快好多,这个就是把正则表达是表示成正则对象最明显的好处。下面我们就可以看看如何把正则表达式转换成正则对象。
3.re.compile(pattern[, flags])
这个方法是就是将字符串的正则表达式编译城正则对象,第二个参数flag是匹配模式,取值可以使用按位或者运算符“|”表示同时生效,比如:re.I | re.M,flag的可选值有:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
M(MULTILINE): 多行模式,改变'^'和'$'的行为
S(DOTALL): 点任意匹配模式,改变'.'的行为
L(LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
U(UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
b = re.compile(r"\d+\.\d*")

