
Redis 相关知识点汇总
一、关于 Redis
1.Redis 是什么
Redis 是一个开放源代码(BSD 许可)的内存中数据结构存储,可用作数据库,缓存和消息代理,是一个基于键值对的 NoSQL 数据库。
2.Redis 特性有哪些
- 速度快
- 基于键值对的数据结构服务器
- 丰富的功能、丰富的数据结构
- 简单稳定
- 客户端语言多
- 持久化
- 主从复制
- 高可以 & 分布式
3.Redis 合适的应用场景
- 缓存
- 排行榜
- 计数器
- 分布式会话
- 分布式锁
- 社交网络
- 最新列表
- 消息系统
4.除了 Redis 以外的 NoSQL 数据库
MongoDB、MemcacheDB、Cassandra、CouchDB、Hypertable、Leveldb。
5.Redis 和 Memcache 区别
- 支持的存储类型不同,memcached 只支持简单的 k/v 结构。redis 支持更多类型的存储结构类型(详见问题6)。
- memcached 数据不可恢复,redis 则可以把数据持久化到磁盘上。
- 新版本的 redis 直接自己构建了 VM 机制 ,一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
- redis 当物理内存用完时,可以将很久没用到的 value 交换到磁盘。
6.Redis 的几种数据类型
基础:字符串(String)、哈希(hash)、列表(list)、集合(set)、有序集合(zset)。
还有HyperLogLog、流、地理坐标等。
7.Redis 的高级功能
消息队列、自动过期删除、事务、数据持久化、分布式锁、附近的人、慢查询分析、Sentinel 和集群等多项功能。
二、Redis 启动和执行
1.Redis 几个比较主要的可执行文件
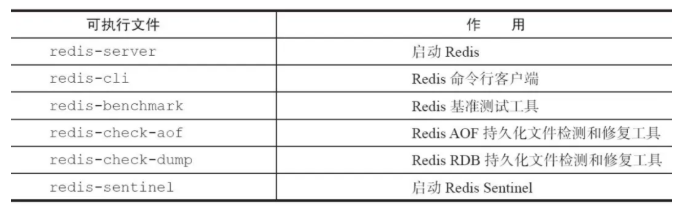
2.启动 Redis 的几种方式
- 默认配置 : ./redis-server
- 运行启动: redis-server 加上要修改配置名和值(可以是多对),没有配置的将使用默认配置。例如: redis-server ———port 7359
- 指定配置文件启动: ./redis-server/opt/redis/redis.conf
3.Redis 配置自定义配置
redis 目录下有一个 redis.conf 的模板配置。只需要复制模板配置然后修改即可。
一般来说大部分生产环境都会用指定配置文件的方式启动redis。
4.Redis 客户端命令执行的方式
- (1)交互方式:
redis-cli -h 127.0.0.1 -p 6379 # 连接到redis后,后面执行的命令就可以通过交互方式实现了。
- (2)命令行方式:
redis-cli -h 127.0.0.1 -p 6379 get value
5.停止 Redis 服务
- Kill-9 pid (粗暴,请不要使用,数据不仅不会持久化,还会造成缓存区等资源不能被优雅关闭)。
- 可以用 redis 的 shutdown 命令,可以选择是否在关闭前持久化数据。
redis-cli shutdown nosave|save
6.如何查看当前键是否存在?
exists key
7.如何删除数据?
del key
三、Redis 注意事项
1.Redis 为什么快
- redis 使用了单线程架构和 I/O 多路复用模型模型。
- 纯内存访问。
- 由于是单线程避免了线程上下文切换带来的资源消耗。
- C语言实现,优化过的数据结构,基于几种基础的数据结构,redis做了大量的优化,性能极高
C语言实现,优化过的数据结构,基于几种基础的数据结构,redis做了大量的优化,性能极高
2.为什么 Redis6.0 是想用多线程
redis 使用多线程并非是完全摒弃单线程,redis 还是使用单线程模型来处理客户端的请求,只是使用多线程来处理数据的读写和协议解析,执行命令还是使用单线程。
这样做的目的是因为 redis 的性能瓶颈在于网络 IO 而非 CPU,使用多线程能提升 IO 读写的效率,从而整体提高 redis 的性能。
3.字符串最大不能超过多少
512MB。
4.Redis 默认分多少个数据库
16个。
5.Redis 持久化的几种方式?
RDB、AOF、混合持久化。
四、RDB 持久化
RDB(Redis DataBase)持久化是把当前进程数据生成快照保存到硬盘的过程。
Tips:是以二进制的方式写入磁盘。
1.RDB 的持久化是如何触发的?
- 手动触发:
- save :阻塞当前 Redis 服务器,直到 RDB 过程完成为止,如果数据比较大的话,会造成长时间的阻塞,线上不建议。
- bgsave:redis 进程执行 fork 操作创作子进程,持久化由子进程负责,完成后自动结束,阻塞只发生在fork阶段,一半时间很短。
- 自动触发:
- savexsecends n: 表示在 x 秒内,至少有 n 个键发生变化,就会触发 RDB 持久化。也就是说满足了条件就会触发持久化。
- flushall:主从同步触发
2.RDB 的优点
- rdb 是一个紧凑的二进制文件,代表 Redis 在某个时间点上的数据快照。
- 适合于备份,全量复制的场景,对于灾难恢复非常有用。
- Redis 加载 RDB 恢复数据的速度远快于 AOF 方式。
3.RDB的缺点
- RDB 没法做到实时的持久化。中途意外终止,会丢失一段时间内的数据。
- RDB 需要 fork() 创建子进程,属于重量级操作,可能导致 Redis卡顿若干秒。
4.如何禁用持久化
一般来说生成环境不会用到,了解一下也有好处的。
config set save ""
五、AOF 持久化
AOF(appendonly file)为了解决 rdb 不能实时持久化的问题,aof 来搞定。以独立的日志方式记录把每次命令记录到 aof 文件中。
1.如何查询 AOF 是否开启
config get appendonly
2.如何开启 AOF
- 命令行方式:实时生效,但重启后失效。
config set appendonly
- 配置文件:需要重启生效,重启后依然生效。
appendonly yes
3.AOF 的工作流程
- 所有写入命令追加到 aof_buf 缓冲区。
- AOF 缓冲区根据对应的策略向硬盘做同步操作。
- 随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
- 当 redis 服务器重启时,可以加载 AOF 文件进行数据恢复。
4.为什么 AOF 要先把命令追加到缓存区(aof_buf)中
Redis 使用单线程响应命令,如果每次写入文件命令都直接追加到硬盘,性能就会取决于硬盘的负载。如果使用缓冲区,redis提供多种缓冲区策略,在性能和安全性方面做出平衡。
5.AOF 持久化如何触发的
- 自动触发:满足设置的策略和满足重写触发。策略:(在配置文件中配置
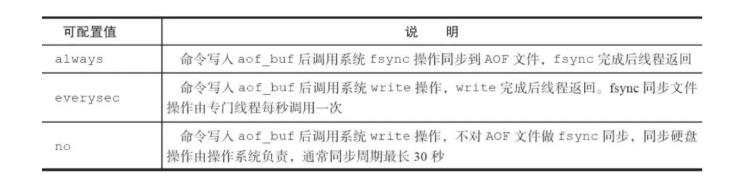
- 手动触发:(执行命令)
bgrewriteaof
6.AOF 优点
- AOF 提供了 3 种保存策略:每秒保存、跟系统策略、每次操作保存。实时性比较高,一般来说会选择每秒保存,因此意外发生时顶多失去一秒的数据。
- 文件追加写形式,所以文件很少有损坏问题,如最后意外发生少写数据,可通过 redis-check-aof 工具修复。
- AOF 由于是文本形式,直接采用协议格式,避免二次处理开销,另外对于修改也比较灵活。
7.AOF 缺点
- AOF 文件要比 RDB 文件大。
- AOF 冷备没 RDB 迅速。
- 由于执行频率比较高,所以负载高时,性能没有 RDB 好。
六、混合持久化
一般来说线上都会采取混合持久化。redis4.0 以后添加了新的混合持久化方式。
1.优点:
在快速加载的同时,避免了丢失过更多的数据。
2.缺点:
- 由于混合了两种格式,所以可读性差。
- 兼容性,需要 4.0 以后才支持。
七、缓存
1. 缓存穿透
正常情况下,我们去查询数据都是存在。那么请求去查询一条数据库中根本就不存在的数据,也就是缓存和数据库都查询不到这条数据,但是请求每次都会打到数据库上面去。这种查询不存在数据的现象称为缓存穿透。
缓存穿透产生大量的请求到数据库去查询。可能会导致数据库由于压力过大而宕机。
解决方案:在缓存中将该键对应的值为设置为 null,配置过期时间
2.缓存击穿
在平常高并发的系统中,大量的请求同时查询一个 key 时,此时若这个 key 正好失效了,就会导致大量的请求都打到数据库上面去。这种现象即缓存击穿。
解决方案:缓存击穿的现象是多个线程同时去查询数据库的同一条数据,可以在第一个查询数据的请求上使用一个互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
3.缓存雪崩
当某一时刻发生大规模的缓存失效的情况。比如缓存服务宕机或集中过期,会有大量的请求直接打到DB上。结果 DB 称不住,挂掉。
解决方案:
-
事前:使用集群缓存,保证缓存服务的高可用。如果是使用 Redis,可以使用 主从+哨兵 ,Redis Cluster 来避免 Redis 全盘崩溃的情况。
-
事中:使用 ehcache 本地缓存 + Hystrix 限流&降级 ,避免 MySQL 被打死的情况发生。使用 Hystrix 进行 限流 & 降级 ,比如一秒来了5000个请求,可以设置假设只能有一秒 2000 个请求能通过这个组件,那么其他剩余的 3000 请求就会走限流逻辑,然后去调用降级组件(降级)。比如设置的一些默认值呀之类的。以此来保护最后的 MySQL 不会被大量的请求给打死。
-
事后:开启 Redis 持久化机制,尽快恢复缓存集群
4.缓存预热
系统上线后,提前将相关数据加载到缓存系统,避免用户先查库,然后在缓存。
八、其他
1.安装 Redis 步骤
- 下载 Redis 指定版本源码安装包压缩到当前目录。
- 解压缩 Redis 源码安装包。
- 建立一个 redis 目录软链接,指向解压包。
- 进入 redis 目录
- 编译
- 安装
或者:docker pull redis。
2.Redis 事务
事务提供了一种将多个命令请求打包,一次性、按顺序的执行多个命令的机制。并且在事务执行期间,服务器不会中断事务而改去执行其他客户端命令请求,它会
3.Redis 事务开始到结束的几个阶段?
- 开启事务
- 命令入队
- 执行事务/放弃事务
4.Redis 中 key 的过期操作?
# 设置key的生存时间为n秒: expire key nseconds # 设置key的生存时间为nmilliseconds: pxpire key milliseconds # 设置过期时间为timestamp所指定的秒数时间戳: expireat key timespamp # 设置过期时间为timestamp毫秒级时间戳: pexpireat key millisecondsTimestamp
5.Redis 过期键删除策略?
- 定时删除:在设置的过期时间同时,创建一个定时器在键的过期时间来临时,立即执行队键的操作删除。
- 惰性删除:放任过期键不管,但每次从键空间中获取键时,都检查取得的键是否过期,如果过期就删除,如果没有就返回该键。
- 定期删除:每隔一段时间执行一次删除过期键操作,并通过先吃删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
定期+惰性都没有删除怎么办
假设 redis 每次定期随机查询 key 的时候没有删掉,这些 key 也没有做查询的话,就会导致这些key一直保存在 redis 里面无法被删除,这时候就会走到 redis 的内存淘汰机制。
- volatile-lru:从已设置过期时间的key中,移出最近最少使用的key进行淘汰
- volatile-ttl:从已设置过期时间的key中,移出将要过期的key
- volatile-random:从已设置过期时间的key中随机选择key淘汰
- allkeys-lru:从key中选择最近最少使用的进行淘汰
- allkeys-random:从key中随机选择key进行淘汰
- noeviction:当内存达到阈值的时候,新写入操作报错
6.Pipeline
命令批处理技术,对命令进行组装,然后一次性执行多个命令。可以有效的节省 RTT(Round Trip Time 往返时间)。
经过测试验证:
- pipeline 执行速度一般比逐条执行快。
- 客户端和服务的网络延越大,pipeline 效果越明显。
7.如何获取当前最大内存?如何动态设置?
# 获取最大内存: config get maxmemory # 设置最大内存: config set maxmemory 1GB
8.Redis 内存溢出控制
当 Redis 所用内存达到 maxmemory 上限时,会出发相应的溢出策略。
9.Redis 内存溢出策略
- noeviction(默认策略):拒绝所有写入操作并返回客户端错误信息(error) OOM command not allowed when used memory,只响应读操作。
- volatile-lru:根据 LRU 算法删除设置了超时属性(expire)的键,直到腾出足够空间为止。如果没有可删除的键对象,回退到noeviction策略。
- allkeys-lru:根据 LRU 算法删除键,不管数据有没有设置超时属性, 直到腾出足够空间为止。
- allkeys-random:随机删除所有键,直到腾出足够空间为止。
- volatile-random:随机删除过期键,直到腾出足够空间为止。
- volatile-tth 根据键值对象的 ttl 属性,删除最近将要过期数据。如果没有,回退到 noeviction 策略。
10.Redis 高可用方案
RedisSentinel(哨兵)能自动完成故障发现和转移。
哨兵功能比单纯的主从架构全面,它具备自动故障转移、集群监控、消息通知等功能。
哨兵可以同时监视多个主从服务器,并且在被监视的master下线时,自动将某个slave提升为master,然后由新的master继续接收命令。整个过程如下:
- 初始化 sentinel,将普通的 redis 代码替换成 sentinel 专用代码
- 初始化 masters 字典和服务器信息,服务器信息主要保存 ip:port,并记录实例的地址和 ID
- 创建和 master 的两个连接,命令连接和订阅连接,并且订阅 sentinel:hello 频道
- 每隔 10 秒向 master 发送 info 命令,获取 master 和它下面所有 slave 的当前信息
- 当发现 master 有新的 slave 之后,sentinel 和新的 slave 同样建立两个连接,同时每个 10 秒发送 info 命令,更新 master 信息
- sentinel 每隔 1 秒向所有服务器发送 ping 命令,如果某台服务器在配置的响应时间内连续返回无效回复,将会被标记为下线状态
- 选举出领头 sentinel,领头 sentinel 需要半数以上的 sentinel 同意
- 领头 sentinel 从已下线的的 master 所有 slave 中挑选一个,将其转换为 master
- 让所有的 slave 改为从新的 master 复制数据
- 将原来的 master 设置为新的 master 的从服务器,当原来 master 重新回复连接时,就变成了新 master 的从服务器
sentinel 会每隔 1 秒向所有实例(包括主从服务器和其他 sentinel)发送 ping 命令,并且根据回复判断是否已经下线,这种方式叫做主观下线。当判断为主观下线时,就会向其他监视的 sentinel 询问,如果超过半数的投票认为已经是下线状态,则会标记为客观下线状态,同时触发故障转移。
11.Redis 集群方案
Twemproxy、Redis Cluster、Codis。
如果说依靠哨兵可以实现 redis 的高可用,如果还想在支持高并发同时容纳海量的数据,那就需要 redis 集群。redis集群是 redis 提供的分布式数据存储方案,集群通过数据分片 sharding 来进行数据的共享,同时提供复制和故障转移的功能。
一个redis集群由多个节点 node 组成,而多个 node 之间通过 cluster meet 命令来进行连接,节点的握手过程:
- 节点A收到客户端的 cluster meet 命令
- A 根据收到的 IP 地址和端口号,向 B 发送一条 meet 消息
- 节点 B 收到 meet 消息返回 pong
- A 知道 B 收到了 meet 消息,返回一条 ping 消息,握手成功
- 最后,节点 A 将会通过 gossip 协议把节点 B 的信息传播给集群中的其他节点,其他节点也将和 B 进行握手
12.RedisCluster 槽
范围:0~16383
redis 通过集群分片的形式来保存数据,整个集群数据库被分为 16384 个槽,集群中的每个节点可以处理 0-16384 个槽,当数据库16384个槽都有节点在处理时,集群处于上线状态,反之只要有一个槽没有得到处理都会处理下线状态。通过 cluster addslots 命令可以将槽指派给对应节点处理。
槽是一个位数组,数组的长度是 16384/8=2048,而数组的每一位用 1 表示被节点处理,0 表示不处理,如图所示的话表示 A 节点处理 0-7 的槽。
当客户端向节点发送命令,如果刚好找到槽属于当前节点,那么节点就执行命令,反之,则会返回一个 MOVED 命令到客户端指引客户端转向正确的节点。(MOVED 过程是自动的)
如果增加或者移出节点,对于槽的重新分配也是非常方便的,redis 提供了工具帮助实现槽的迁移,整个过程是完全在线的,不需要停止服务。
13.Redis 锁实现思路
- setnx(set if not exists),如果创建成功则表示获取到锁。
- setnxlock true 创建锁
- dellock 释放锁
如果中途崩溃,无法释放锁?此时需要考虑到超时时间的问题。比如 :expire lock 300。由于命令是非原子的,所以还是会死锁,如何解决?Redis支持 set 并设置超时时间的功能。比如: set lock true ex 30 nx。
14.布隆过滤器
是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
Tips:当判断一定存在时,可能会误判,当判断不存在时,就一定不存在。

