


常见的缓存突发状况
前言:
1.mybatis-config.xml 配置:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <settings> <!--这个配置是全局的映射器(二级缓存)启用或禁用缓存--> <setting name="cacheEnabled" value="true" /> ..... </settings>
2. mapper 处理
eviction:代表的是缓存回收策略,目前MyBatis提供以下策略。
(1) LRU,最近最少使用的,一处最长时间不用的对象
(2) FIFO,先进先出,按对象进入缓存的顺序来移除他们
(3) SOFT,软引用,移除基于垃圾回收器状态和软引用规则的对象
(4) WEAK,弱引用,更积极的移除基于垃圾收集器状态和弱引用规则的对象。这里采用的是LRU、 移除最长时间不用的对形象
flushInterval:刷新间隔时间,单位为毫秒,这里配置的是100秒刷新,如果你不配置它,那么当SQL被执行的时候才会去刷新缓存。
size:引用数目,一个正整数,代表缓存最多可以存储多少个对象,不宜设置过大。设置过大会导致内存溢出。
这里配置的是1024个对象
readOnly:只读,意味着缓存数据只能读取而不能修改,这样设置的好处是我们可以快速读取缓存,
缺点:是我们没有办法修改缓存,他的默认值是false,不允许我们修改
<cache eviction="LRU" flushInterval="100000" readOnly="true" size="1024"/>
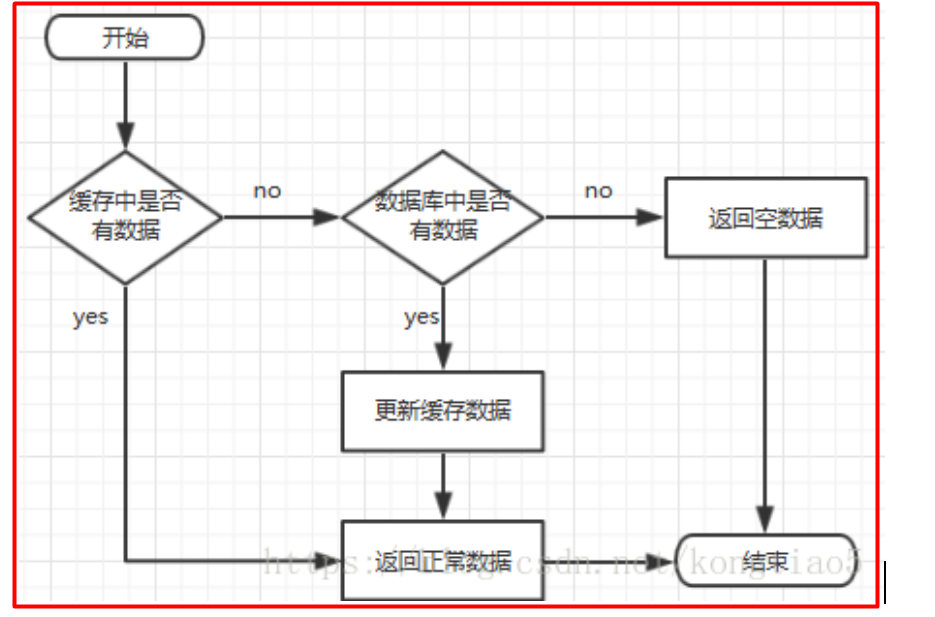
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,
数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
三:缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。
这时的用户很可能是攻击者, 攻击会导致数据库压力过大。
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,
如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,
失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
解决方案:
1. 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
2. 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,
如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
3. 有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,
一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),
如果一个查询返回的数据为空(不管是数 据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
四、缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,
同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压
解决方案:
1. 设置热点数据永远不过期。
2. 加互斥锁,互斥锁:
互斥锁,是一种信号量,常用来防止两个进程或线程在同一时刻访问相同的共享资源。可以保证以下三点:
原子性:把一个互斥量锁定为一个原子操作,这意味着操作系统(或pthread函数库)
保证了如果一个线程锁定了一个互斥量,没有其他线程在同一时间可以成功锁定这个互斥量
唯一性:如果一个线程锁定了一个互斥量,在它解除锁定之前,没有其他线程可以锁定这个互斥量。
非繁忙等待:如果一个线程已经锁定了一个互斥量,第二个线程又试图去锁定这个互斥量,
则第二个线程将被挂起(不占用任何cpu资源),直到第一个线程解除对这个互斥量的锁定为止,
第二个线程则被唤醒并继续执行,同时锁定这个互斥量。
3. 对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,
这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
五、缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。
和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:
1.缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
2.如果缓存数据库是分布式部署,将热点数据均匀分布在不同得缓存数据库中。
3.设置热点数据永远不过期。
缓存失效时的雪崩效应对底层系统的冲击非常可怕。大多数系统设计者考虑用加锁或者队列的方式
保证缓存的单线 程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
这里分享一个简单方案就时讲缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,
比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
java引用拓展:
强引用:就是普通引用。比如 A o1=new A(); A o2=o1;
强引用只有当所有对这个对象的所有引用(o1,o2)失效后,new A()的内存才会被回收。
残引用、弱引用、软引用都用来引用随时可能被回收的对象。类似o1,o2即使未失效也会回收。
区别是被回收器回收的激烈程度,由强到弱。
残影引用是对象已经finalize或者执行完析构函数,只等内存马上回收了,最容易被回收。非常接近回收时机,就像残影会随物体消失而消失,故名。
弱引用的对象是在正常情况下,回收器遇到就回收,是被积极回收的对象。
软引用是仅在内存不够时才回收,属于消极回收。
析构函数:
析构函数(destructor) 与 构造函数相反,当对象结束其 生命周期时(例如对象所在的函数已调用完毕),
系统自动执行析构函数。析构函数往往用来做“清理善后” 的工作(例如在建立对象时用new开辟了一片内存空间,应在退出前在析构函数中用delete释放

