
iOS--OCR图片识别
应公司财务需求,要做一个收据识别功能。所以在网上搜索了下三方SDK,其中tesseract-ocr受到了大多数网友的推荐。我当然是前往https://github.com/gali8/Tesseract-OCR-iOS 进行sdk查看下载了。然后直接下载并不好用,各种缺包,不过开发者也是有心了,提供了完善的安装说明。
点击蓝色的Installation,可以按照官方说明文档进行pod 下载
pod 'TesseractOCRiOS', '4.0.0'根据文档所述,我们还需要拖入tessdata文件夹,里面有语言包,常用包括eng英文解析和chi_sim中文解析。https://code.google.com/p/tesseract-ocr/downloads/list我们可以前往谷歌进行下载,也可以在github Tesseract-OCR-iOS中,找到他们使用的tessdata文件夹,单独下载。然后将tessdata直接拖入项目中,这里需要注意的是,拖入的时候选择creater folder references。
TesseractOCRiOS的使用非常简单,点开上面蓝色的 usage examples,就有包括swift在内的各种调用方式。需要注意的只有几点,一是
G8Tesseract *tesseract = [[G8Tesseract alloc] initWithLanguage:@"eng+ita"];
@“eng+ita”代表会搜索多个文件解析(eng.traineddata和ita.traineddata),如果只想使用eng,就可以只用使用@“eng”;这个github项目是没有提供中文解析功能的,我们需要去下载chi_sim.traineddata导入项目中,导入需要注意到是:打开 项目,show in finder,然后将chi_sim直接放入tessdata文件中即可。如果使用后result为空,乱码,甚至于崩溃,可能是chi_sim版本不对,可以去搜索3.0.1的chi_sim,重新导入项目中使用。
当然,某种情况下TesseractOCRiOS确实好用,我解析文档内容准确率极高,甚至于使用网上的解析银行卡和身份证也是相当可以的。但是,针对于油墨打印的发票内容,就有心无力了,各种解析乱码,错误,连数字都因为油墨扩散的原因解析错误。
在查询了资料发现,ocr仅仅具备图片识别,意思就是需要使用我们处理好的图片进行识别,本身并没有对图片进行很好的处理,唯一的滤镜方式g8_blackAndWhite仅仅也是针对英文与数字,因此,我为工程导入了OpenCV,本想直接采用pod openCV,然后又是一个大坑,根本没发pod,没办法,前往官网,下载了opcv2.framework,导入到项目中。使用的第一件事就是enum(NO,。。。)出错,Expected identifier,NO这个define的宏无法解析,因为OC使用的是c语言方式解析,而openCV使用的C++编写。那么我们也只能采用混合编写模式了,将使用opencv控制器改为c++编译。
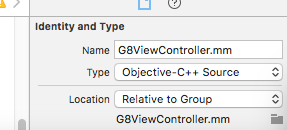
选择type方式为 C++ source;或者将文件名由.m改为.mm或.cpp
另外exposure_compensate.hpp:66:12: Expected identifier
同样的报错在blender里,解决:点到源代码处把NO改为NO_EXPOSURE_COMPENSATOR = 0,就好了
当然,还有其他的错误,文件前缀为AV或_objc文件出现错误,一般是因为少导入了AVFoundtion,coreMedia,coreVideo,AssertsLibrary等框架。而使用opencv调用相册的时候,需要设置隐私权限提示。
<key>NSPhotoLibraryUsageDescription</key>
<string>我们将要使用你的相册</string>
<key>NSPhotoLibraryAddUsageDescription</key>
<string>我们将要使用你的相册</string>
<key>NSAppleMusicUsageDescription</key>
<string>要使用到您的媒体库</string>
<key>NSCameraUsageDescription</key>
<string>我们将要使用你的相机</string>
使用opencv对拍照的图片进行 灰度处理,阀值处理,腐蚀:白色背景缩小,黑色扩大,区域设置等等功能,让图片更加清晰明显,便于识别。
ps:坑爹的是,这并没有很好的解决油墨发票上数字文字不清晰,难以识别的问题,仅仅提高了识别成功率,但是并没有很大的实际作用。一句mmp不知当讲不当讲,为什么不打印成a4效果。后续有看到图片识别训练,需要服务器配合,以及使用各大公司收费ocr。

