System | CSE | Atomic
对于崩溃一致性,要求系统要具有原子性(Atomic)
An action is atomic if happens completely or not at all
可以用事务来衡量一个行为,在事务提交之前所做的修改为nothing,如果系统发生崩溃则全部undo。事务提交之后则是all,如果崩溃则需要redo。
以一个日志系统来考虑整个流程,并且所有的读写都发生在这个日志上。

对于一个事务有五种行为:
- 开始:分配一个新的事务号
- 写:添加一个新的记录到日志
- 读:搜索整个日志寻找最近的一次提交,读取其中的值
- 提交(commit):对于原子性最重要的一步,将nothing转换成all。(原子性由磁盘支撑)
- 放弃(abort):中止此次事务
对于这样一个简单的日志系统,评价它的性能:
- 写的性能还不错:是顺序写,不需要转动磁盘
- 恢复性能非常好:不需要干任何事
- 读性能很糟糕:每次读都需要遍历整个日志
而读数据是系统中最常用的操作,恢复是极少见的,违背了"make the common case fast"的设计原则。
性能优化
在磁盘中中添加一个cell storage,用来存储数据的最新值。读操作时只需要从该位置直接读取数据。但这样会破坏事务的原子性,即当事务没有提交时也可以读到修改后的值,在不引入“锁”时无法解决这个问题。
在数据更新时,先将数据写入日志,再更新cell中的值。日志的原则是 "Write-ahead-log protocol" (WAL)。
当崩溃时,需要撤销没有提交的事务,因此需要从后往前扫描日志,对没有提交的事务将cell storager中的值恢复为最新提交事务中的值。
这个系统的性能发生了改变:
- 读性能很好,可以直接读取cell storage中的值
- 写性能一般,每次写要写两次磁盘,更新cell和log
- 恢复需要扫描整个log
因此还存在一些问题,写两次磁盘代价依然很高,并且随着日志的延伸,扫描日志的代价将越来越大。
优化写性能
在系统中用cache储存写入的值,每次写只需要写日志,不需要写cell。在将cache刷入磁盘之前可能会对值有多次的更新。读数据时也可以直接读cache中的值。
但发生崩溃后,cell中的值可能超前,也可能落后,因此既需要undo也需要redo。
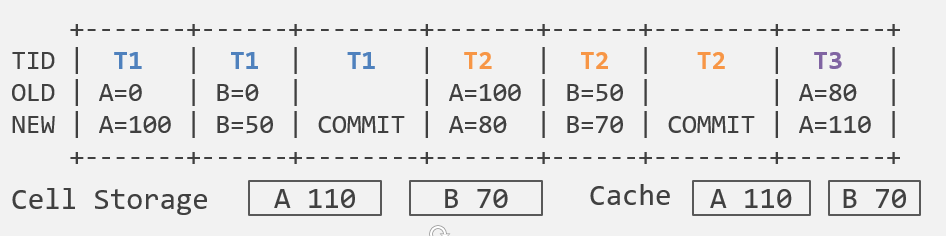
优化恢复
在日志中加入checkpoint,对于checkpoint之前的事务无需再进行检查。因此在checkpoint之前,需要暂停接收新事务,等待所有活动的事务提交或者中止,在日志中写入< CKPT >,才能执行新的事务。
暂停整个系统往往是不能接受的,因此一种优化方案是Fuzzy CheckPoint:
- 在日志中记录<START CKPT(T1...Tk)>,即记录还在活动的事务。
- 等待这些事务全部提交或中止,但同时允许新事务的开始
- 写入< END CKPT >
在恢复时如果日志中存在
优化日志
考虑整个流程,我们都需要把日志直接写入磁盘,但写入磁盘是很慢的。因此我们可以考虑Lazy Writting,仅当外部观察(请求)数据的时候,再将数据写入磁盘。通过外部可观察的行为来定义同步I/O。
这是一种比较极端的优化,如果在没观察之前发生了崩溃,就当这段时间没有发生任何改动。
