
桐花万里python路-基础篇-11-常用模块
- time:时间
- 时间元组
序号 属性 值 0 tm_year 2008 1 tm_mon 1 到 12 2 tm_mday 1 到 31 3 tm_hour 0 到 23 4 tm_min 0 到 59 5 tm_sec 0 到 61 (60或61 是闰秒) 6 tm_wday 0到6 (0是周一) 7 tm_yday 1 到 366(儒略历) 8 tm_isdst -1, 0, 1, -1是决定是否为夏令时的旗帜 %y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身
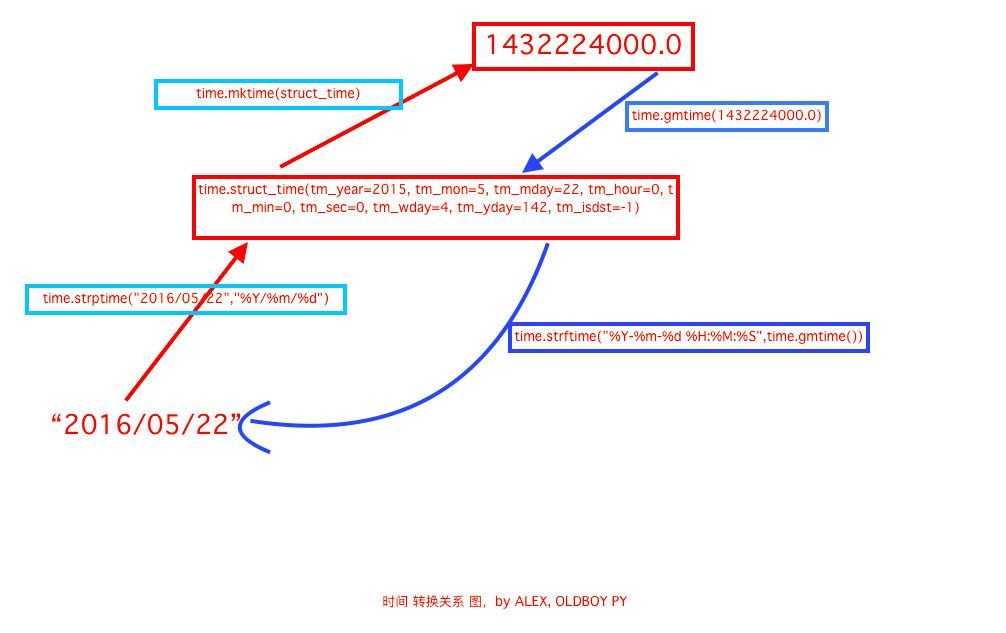
- time.localtime([secs]):将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
- time.gmtime([secs]):和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
- time.time():返回当前时间的时间戳。
- time.mktime(t):将一个struct_time转化为时间戳。
- time.sleep(secs):线程推迟指定的时间运行。单位为秒。
- time.asctime([t]):把一个表示时间的元组或者struct_time表示为这种形式:'Sun Oct 1 12:04:38 2017'。如果没有参数,将会将time.localtime()作为参数传入。
- time.ctime([secs]):把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
-
time.strftime(format[, t]):把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
- time.strptime(string[, format]):把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作
 View Code
View Codeimport time print(time.time()) print(time.mktime(time.localtime())) print(time.gmtime()) # 可加时间戳参数 print(time.localtime()) # 可加时间戳参数 print(time.strptime('2018-01-11', '%Y-%m-%d')) print(time.strftime('%Y-%m-%d %H:%M:%S')) # 默认当前时间 print(time.strftime('%Y-%m-%d', time.localtime())) # 默认当前时间 print(time.asctime())# 返回时间格式"Thu Jan 18 16:37:24 2018" print(time.asctime(time.localtime()))# 返回时间格式"Thu Jan 18 16:37:24 2018" print(time.ctime(time.time()))# 返回时间格式"Thu Jan 18 16:37:24 2018" """ 1516264644.6415637 1516264644.0 time.struct_time(tm_year=2018, tm_mon=1, tm_mday=18, tm_hour=8, tm_min=37, tm_sec=24, tm_wday=3, tm_yday=18, tm_isdst=0) time.struct_time(tm_year=2018, tm_mon=1, tm_mday=18, tm_hour=16, tm_min=37, tm_sec=24, tm_wday=3, tm_yday=18, tm_isdst=0) time.struct_time(tm_year=2018, tm_mon=1, tm_mday=11, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=11, tm_isdst=-1) 2018-01-18 16:37:24 2018-01-18 Thu Jan 18 16:37:24 2018 Thu Jan 18 16:37:24 2018 Thu Jan 18 16:37:24 2018 """
- 时间元组
- datetime:时间
- datetime模块的接口则更直观、更容易调用
-
- datetime.date:表示日期的类。常用的属性有year, month, day;
- datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond;
- datetime.datetime:表示日期时间。
- datetime.timedelta:表示时间间隔,即两个时间点之间的长度。
- datetime.tzinfo:与时区有关的相关信息
import datetime # 把一个时间戳转为datetime日期类型 print(datetime.date.fromtimestamp(1512322222)) # 2017-12-04 # 返回当前的datetime日期类型 d = datetime.datetime.now() print(d.date(),d.year,d.month,d.day)# 2018-01-18 2018 1 18 print(d.time(),d.hour,d.minute,d.second,d.microsecond) # 16:45:47.782493 16 45 47 782493 # 时间运算 newdt =datetime.datetime.now() + datetime.timedelta(4) #当前时间 +4天 print(newdt) # 2018-01-22 16:48:28.938439 newhr = datetime.datetime.now() + datetime.timedelta(hours=4) print(newhr) # 2018-01-18 20:51:57.899933 # 时间替换 print(d.replace(year=2099,day=30).strftime("%Y-%m-%d %H:%M:%S")) # 2099-01-30 16:51:57
- random:随机
View Code
import random print(random.randrange(1,10)) #返回1-10之间的一个随机数,不包括10 print(random.randint(1,10)) #返回1-10之间的一个随机数,包括10 print(random.randrange(0, 100, 2)) #随机选取0到100间的偶数 print(random.random()) #返回一个随机浮点数 print(random.choice('abce3#$@1')) #返回一个给定数据集合中的随机字符 print(random.sample('abcdefghij',3)) #从多个字符中选取特定数量的字符 #生成随机字符串 import string print(''.join(random.sample(string.ascii_lowercase + string.digits, 6))) #打乱 a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] random.shuffle(a) print(a) """ 8 10 18 0.0371166610238336 3 ['h', 'a', 'd'] tfmj34 [5, 2, 1, 8, 9, 7, 4, 0, 6, 3] """
- os:对操作系统进行调用
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
- sys
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write('please:') val = sys.stdin.readline()[:-1]
- shutil:高级的 文件、文件夹、压缩包 处理模块。对os中文件操作的补充
- shutil.copyfileobj(fsrc, fdst[, length]),将文件内容拷贝到另一个文件中,可以部分内容
- shutil.copyfile(src, dst) 拷贝文件
- shutil.copymode(src, dst) 仅拷贝权限。内容、组、用户均不变
- shutil.copystat(src, dst) 拷贝状态的信息,包括:mode bits, atime, mtime, flags
- shutil.copy(src, dst) 拷贝文件和权限
- shutil.copy2(src, dst) 拷贝文件和状态信息
- shutil.copytree(src, dst, symlinks=False, ignore=None) 递归的去拷贝文件
- shutil.rmtree(path[, ignore_errors[, onerror]]) 递归的删除文件
- shutil.move(src, dst) 递归的移动文件
- shutil.make_archive(base_name, format,...) 创建压缩包并返回文件路径
- base_name,文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径
- format 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir 要压缩的文件夹路径(默认当前目录)
- owner 默认当前用户
- group 默认当前组
- logger 用于记录日志,通常是logging.Logger对象
- 压缩解压 ZipFile 和 TarFile
import zipfile # 压缩 z = zipfile.ZipFile('laxi.zip', 'w') z.write('a.log') z.write('data.data') z.close() # 解压 z = zipfile.ZipFile('laxi.zip', 'r') z.extractall() z.close()
- json和pickle 序列化
- json 用于字符串 和 python数据类型间进行转换
- pickle 仅作为python对象的持久化或者python程序间进行互相传输对象的方法,因此它支持了python所有的数据类型
- pickle反序列化后的对象与原对象是等值的副本对象,类似与deepcopy。
- pickle在不同版本的Python序列化可能还有差异
- 都有dumps、dump、loads、load
- dumps 将 Python 对象编码成 JSON 字符串 或 pickle
- loads 将已编码的 JSON 字符串 或pickle解码为 Python 对象
- dump 持久化到文件
- load 从文件反序列回来
import json import pickle dic = {'a':'ss','sss12':'231321'} txt = json.dumps(dic) print(txt) with open('json.txt','w') as f: json.dump(dic,f) with open('json.txt','r') as f: print(json.load(f)) # {'a': 'ss', 'sss12': '231321'} from datetime import date dic['today'] = date.today() with open('pickle.txt','wb') as f: pickle.dump(dic,f) with open('pickle.txt','rb') as f: print(pickle.load(f)) # {'a': 'ss', 'sss12': '231321', 'today': datetime.date(2018, 1, 18)}
- shelve 一个简单的key-value,将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve sp = shelve.open('shelve') sp['dic'] = dic sp['ok'] = ('12','22') sp['123'] = 123.321 sp.close() dsp = shelve.open('shelve') print(dsp['dic'],dsp['123'],dsp['ok']) - configparse 处理特定格式的文件 ini
import configparser # 获取所有节点 sections config = configparser.ConfigParser() config.read('conf.ini', encoding='utf-8') ret = config.sections() print(ret) # 获取指定节点下所有的键值对 items 包含DEFAULT ret = config.items('User') print(ret) # 获取指定节点下所有的键 options 包含DEFAULT ret = config.options('User') print(ret) # 获取指定节点下指定key的值 v = config.get('sec1', 'user') print(v) # 检查 section has_section has_sec = config.has_section('section1') print(has_sec) # 添加 section add_section if not config.has_section('Database'): config.add_section("Database") config.write(open('conf.ini', 'w+',encoding='utf-8')) # 删除 section remove_section if config.has_section('Database'): config.remove_section("Database") config.write(open('conf.ini', 'w+',encoding='utf-8')) # 检查、删除、设置指定组内的键值对 # 检查 option has_option has_sec = config.has_option('User','name') print(has_sec) # 添加 option set if not config.has_option('DB','password'): config.set("DB",'password','123') config.set("DB",'host','123.123.0.12') config.write(open('conf.ini', 'w+',encoding='utf-8')) # 删除 option remove_option if config.has_option('DB','password'): config.remove_option("DB",'password') config.write(open('conf.ini', 'w+',encoding='utf-8'))
- hashlib 加密相关
- 主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib md = hashlib.md5() print(md) md.update('admin'.encode('utf8')) print(md.digest()) print(md.hexdigest()) #21232f297a57a5a743894a0e4a801fc3 md.update('admin'.encode('utf8')) print(md.hexdigest()) #f6fdffe48c908deb0f4c3bd36c032e72 md2 = hashlib.md5() md2.update('adminadmin'.encode('utf8')) print(md2.hexdigest()) #f6fdffe48c908deb0f4c3bd36c032e72 print('-'*50) md3 = hashlib.sha256() md3.update('admin'.encode('utf8')) print(md3.hexdigest())
- 主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
- subprocess 实现对系统命令或脚本的调用
- run(*popenargs, input=None, timeout=None, check=False, **kwargs) #官方推荐
- call(*popenargs, timeout=None, **kwargs) #跟上面实现的内容差不多,另一种写法
- Popen() #上面各种方法的底层封装,执行复杂的系统命令
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 - shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用 \n
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
-
import subprocess # 标准写法 subprocess.run(['df','-h'],stderr=subprocess.PIPE,stdout=subprocess.PIPE,check=True) # 涉及到管道|的命令需要这样写 subprocess.run('df -h|grep disk1',shell=True) # shell=True的意思是这条命令直接交给系统去执行,不需要python负责解析 #执行命令,返回命令执行状态 , 0 or 非0 ret = subprocess.call(["ipconfig", "-l"], shell=True) # 执行命令,如果命令结果为0,就正常返回,否则抛异常 subprocess.check_call(["ls", "-l"]) # 执行命令,如果命令结果为0 ,则返回执行结果,否则抛异常 subprocess.check_output(["echo", "Hello World!"]) subprocess.check_output("exit 1", shell=True) subprocess.Popen("mkdir t3", shell=True, cwd='/home/dev',)
- logging
- 记录日志且线程安全的模块
- 日志级别
NOTSET=0- debug()
DEBUG=10 - info()
INFO=20 - warning()
WARNING=30 - error()
ERROR=40 - critical()
CRITICAL=50
- 写入文件
-
import logging logging.basicConfig(level=logging.INFO, filemode='a',#w|a filename='log.txt', datefmt='%Y-%m-%d %H:%M:%S', format='%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s' ) logging.debug('debug message') logging.info('info message') logging.warning('warning message') #默认显示 logging.error('error message') logging.critical('critical message') # level=loggin.INFO意思是,把日志纪录级别设置为INFO,也就是说,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,debug被忽略
模板
- %(name)s Logger的名字
- %(levelno)s 数字形式的日志级别
- %(levelname)s 文本形式的日志级别
- %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
- %(filename)s 调用日志输出函数的模块的文件名
- %(module)s 调用日志输出函数的模块名|
- %(funcName)s 调用日志输出函数的函数名|
- %(lineno)d 调用日志输出函数的语句所在的代码行
- %(created)f 当前时间,用UNIX标准的表示时间的浮点数表示|
- %(relativeCreated)d 输出日志信息时的,自Logger创建以来的毫秒数|
- %(asctime)s 字符串形式的当前时间。默认格式是“2003-07-08 16:49:45,896”。逗号后面的是毫秒
- %(thread)d 线程ID。可能没有
- %(threadName)s 线程名。可能没有
- %(process)d 进程ID。可能没有
- %(message)s 用户输出的消息
- 同时输出到屏幕和文件
logger = logging.getLogger() logger.setLevel(logging.DEBUG) #文件对象 fh = logging.FileHandler('log.log') # 屏幕对象 ch = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s') fh.setFormatter(formatter) ch.setFormatter(formatter) #文件记录 logger.addHandler(fh) #屏幕输出 logger.addHandler(ch) logger.debug('debug message') logger.info('info message') logger.warning('warning message') logger.error('error message') logger.critical('critical message')
- re 正则表达式 :用来匹配字符串的强有力的武器
- 元字符
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) '$' 匹配字符结尾, 若指定flags MULTILINE ,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到foo1 '*' 匹配*号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa' '+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] '?' 匹配前一个字符1次或0次 ,re.search('b?','alex').group() 匹配b 0次 '{m}' 匹配前一个字符m次 ,re.search('b{3}','alexbbbs').group() 匹配到'bbb' '{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' '(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45' '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,相当于re.match('abc',"alexabc") 或^ '\Z' 匹配字符结尾,同$ '\d' 匹配数字0-9 '\D' 匹配非数字 '\w' 匹配[A-Za-z0-9] '\W' 匹配非[A-Za-z0-9] 's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
- 语法
- re.match(pattern, string, flags=0) 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags: 用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
- 返回值 匹配成功re.search方法返回一个匹配的对象,否则返回None
- re.search(pattern, string, flags=0) 扫描整个字符串并返回第一个成功的匹配
- pattern:匹配的正则表达式
- string:要匹配的字符串
- flags:用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
- 返回值 匹配成功re.search方法返回一个匹配的对象,否则返回None
- re.group和re.groups
- group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组
- groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号
- re.findall(pattern, string, flags=0) 如果想要匹配到字符串中所有符合条件的元素
- re.sub(pattern, repl, string, count=0, flags=0) 用于替换匹配的字符串
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- re.split(pattern, string, maxsplit=0, flags=0)
- re.fullmatch(pattern, string, flags=0)
- re.match(pattern, string, flags=0) 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
- Flags标志符
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变'^'和'$'的行为
- S(DOTALL): 改变'.'的行为,make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline.
- X(re.VERBOSE) 可以给你的表达式写注释,使其更可读
- 其他说明
- re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配
import re line = "Cats are smarter than dogs" matchObj = re.match(r'(.*) are (.*?) .*', line, re.M | re.I) if matchObj: print("matchObj.group() : ", matchObj.group()) print("matchObj.group(1) : ", matchObj.group(1)) print("matchObj.group(2) : ", matchObj.group(2)) else: print("No match!!") """ matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter """ str = 'hello world' ret = re.search('w\w{2}l',str+'world') #匹配出第一个满足条件的结果 print(ret) #<_sre.SRE_Match object; span=(6, 10), match='worl'> print(ret.group()) ret = re.findall('w\w{2}l',str) print(ret) #元字符 # . 除换行符的任意一个字符 # ^ 匹配以某字符开始 # $ 匹配以某字符结束 # * 重复匹配0到无穷 {0,} # + 重复匹配1到无穷 {1,} # ? 0或1个 {0,1} # {} 范围 # [] 字符集[a,c,e]中的一个 [0-9][a-z][A-Z] 取消 除 \ - ^ 元字符的特殊功能 # | # () # \ 1.取消元字符的特殊功能 2.跟部分普通字符实现特殊功能 # \d [0-9] # \D [^0-9] 非数字字符 # \s [\t\n\f\r\v] # \S [^\t\n\f\r\v] # \w [0-9a-zA-Z] # \W [^0-9a-zA-Z] # \b 单词边界 单词和空格之间的位置 特殊字符 ret = re.findall('a?b','aaaaaabsdsabfffb') print(ret) ret = re.findall(r'I\b','Hello ,I am CHINESE') print(ret) ret = re.findall(r'I\b','Hello ,I am CHI$NESE') print(ret) ret = re.findall(r'I\b','Hello ,I am CHI#NESE') print(ret) # 分组 ret = re.search('(?P<id>\d{3})/(?P<name>\w{3})','Hello 678/ESE') print(ret.group()) print(ret.group('id')) #678 print(ret.group('name')) #ESE # re.match与re.search的区别 line = "Cats are smarter than dogs"; matchObj = re.match(r'dogs', line, re.M | re.I) if matchObj: print("match --> matchObj.group() : ", matchObj.group()) else: print("No match!!") matchObj = re.search(r'dogs', line, re.M | re.I) if matchObj: print("search --> matchObj.group() : ", matchObj.group()) else: print("No match!!") """ No match!! search --> matchObj.group() : dogs """ #re.match() ret = re.split('[k,s]','sdasdkdssds') #分割 print(ret) ret = re.sub('[k,s]','1','sdasdkdssds') #替换 print(ret) phone = "2004-959-559 # 这是一个国外电话号码" # 删除字符串中的 Python注释 num = re.sub(r'#.*$', "", phone) print("电话号码是: ", num) # 删除非数字(-)的字符串 num = re.sub(r'\D', "", phone) print("电话号码是 : ", num) """ 电话号码是: 2004-959-559 电话号码是 : 2004959559 """
- 元字符
- XML 很多传统公司如金融行业的很多系统的接口还主要是xml
- xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
import xml.etree.ElementTree as ET # 自己创建xml文档 new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19' et = ET.ElementTree(new_xml) # 生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) # 打印生成的格式 # 编辑xml文件 tree = ET.parse("test.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml') # 解析xml tree = ET.parse("test.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text)
- xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml

