6.MySQL简介
MySQL简介
·点击查看MySQL官方网站
·MySQL是一个关系型数据库管理系统,由瑞典MySQLAB公司开发,后来被Sun公司收购,Sun公司后来又被Oracle公司收购,目前属于facle旗下产品
特点
·使用C和C++编写,并使用了多种编译器进行测试,保证源代码的可移植性
·支持多种操作系统,如Linux、Widdows、AlX、FreeBSD、HP-UX、MacOS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris等
·为多种编程语言提供了API,如C、C++、Python、Java、Perl、PHP、Eiffel、Ruby等
·支持多线程,充分利用CPU资源
·优化的SQL查询算法,有效地提高查询速度
·提供多语言支持,常见的编码如GB2312、BIG5、UTF8
·提供TCP/IP、ODBC和JDBC等多种数据库连接途径
·提供用于管理、检查、优化数据库操作的管理工具
·大型的数据库。可以处理拥有上千万条记录的大型数据库
·支持多种存储引擎
·MySQL软件采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择MySQL作为网站数据库
·MySQL使用标准的SQL数据语言形式
·Mysql是可以定制的,采用了GPL协议,你可以修改源码来开发自己的Mysql系统
·在线DDL更改功能
·复制全局事务标识
·复制无崩渍从机
·复制多线程从机
数据类型与约束
·为了更加准确的存储数据,保证数据的正确有效,需要合理的使用数据类型和约束来限制数据的存储。
常用数据类型
·整数:int,有符号范围(-2147483648~2147483647),无符号范围(0~429496725)
·小数:decimal,如decimal(5.2)表示共存5位数,小数占2位,整数占3位
·字符串:varchar,范围(0~65533),如varchar(3)表示最多存3个字符,一个中文或一个字母都占一个字符
·日期时间:datetime,范围(1000-01-01 00:00:00~9999-12-3123:59:59),如12020-01-01 12:29:59'
约束
·主键(primary key):物理上存储的顺序
·非空(not nul):此字段不允许填写空值
·惟一(unique):此字段的值不允许重复
·默认值(default):当不填写此值时会使用默认值,如果填写时以填写为准
·外键foreign key):维护两个表之间的关联关系
数据库的基本操作
创建数据库的语法格式:
create databases 数据库名称 ;
例:创建一个名称为xiaoxu的数据库,SQL语句如下:
create databases xiaoxu ;
查看数据库的语法格式:
show databases ;
查看某个已创建好的数据库的语法格式:
show create databases 数据库名称 ;
修改数据库编码的语法格式:
lter database 数据库名称 default character set 编码方式 collate 编码方式_bin ;
例:将数据库xiaoxu 的编码修改为 gbk,SQL语句如下所示:
alter database xiaoxu default character set gbk collate gbk_bin ;
删除数据库的语法格式:
drop database 数据库名称 ;
数据表的基本操作
创建数据表语法格式:
create table 表名 { 字段名 1,数据类型[完整性约束条件], 字段名 2,数据类型[完整性约束条件], ... 字段名 n,数据类型[完整性约束条件], }
例:创建学生表,字段要求如下
姓名(长度为10),年龄
create table student( id int unsigned primary key auto_increment, name varchar(10), age int unsigned, height decimal(5,2) )
查看数据表的语法格式:
show create table 表名 ; 或者 describe 表名 ; 简写为 desc 表名 ;
删除表
drop table 表名; 或者 drop table if exists 表名;
例:删除学生表
drop table students 或 drop table if exists students
添加数据
添加一行数据
格式一:所有字段设置值,值的顺序与表中字段的顺序对应
·说明:主键列是自动增长,插入时需要占位,通常使用0或者default 或者nul来占位,插入成功后以实
insert into 表名 values(...)
例:插入一个学生,设置所有字段的信息
insert into students values(e,'亚瑟”,22,177.56)
格式二:部分字段设置值,值的顺序与给出的字段顺序对应
insert into 表名(字段1,..) values(值1.…)
例:插入一个学生,只设置姓名
insert into students(name) values(“老夫子")
添加多行数据
方式一:写多条insert语句,语句之间用英文分号隔开
insert into students(name) values(“老夫子2); insert into students(name) values('老夫子3’); insert into students values (0,‘亚瑟2",23,167.56)
方式二:写一条insert语句,设置多条数据,数据之间用英文逗号隔开
格式一:insert into 表名 values(..),(...)... 例:插入多个学生,设置所有字段的信息 insert into students values(0,'亚瑟3',23,167.56),(0,‘亚瑟4,23,167.56)
格式二:insert into 表名(列1,..)values(值1..),(值1...... 例:插入多个学生,只设置姓名 insert into students(name) values('老夫子5),('老夫子6)
修改
格式:update 表名 set 列1=值1,列2=值2 … where条件
例:修改id为5的学生数据,姓名改为狄仁杰,年龄改为20
update students set name='数仁杰’,age=20 where id=5
删除
格式:delete from 表名 where 条件
例:删除id为6的学生数据
delete from students where id=6
逻辑删除
1、设计表,给表添加一个字段isdelete,1代表删除,0代表没有删除 2、把所有的数据isdelete都改为0 3、要删除某一条数据时,更新他的isdelete为1 4、当要查询数据时,只查询isdelete为0的数据 update students3 set isdelete=0 update students3 set isdelete=1 where id=1 select * from students3 where isdelete=0
查询数据
创建数据表
drop table if exists students; create table students( studentNo varchar(10) primary key, name varchar(18), sex varchar(1), hometown varchar(20), age tinyint(4), class varchar(10), card varchar(28), )
准备数据
insert into students values (‘001’,‘王昭君’,‘女’,‘北京’,‘20’,‘1班‘,‘340322199001247654’), (‘002',‘诸葛亮’,‘男’,‘上海’,‘18’,‘2班’,'340322199002242354‘), (‘003',‘张飞‘,‘男’,‘南京’,‘24’,'3班’,‘340322199003247654’), (‘084’,‘白起’,‘男’,‘安徽’,‘22’,14班’,‘348322199005247654’), (‘005’,‘大乔’,‘女’,‘天津”,‘19’,‘3班’,‘340322199004247654’), (‘086’,‘孙尚香,‘女’,‘河北’,‘18’,‘1班’,‘340322199006247654’), (‘007’,‘百里玄策”,‘男’,‘山西’,‘20’,‘2’班”,‘340322199007247654’),
查询所有字段 select *from 表名 select * from students
查询指定字段 在select后面的列名部分,可以使用as为列起别名,这个别名出现在结果集中 select列1,列2,..from表名 --表名.字段名 select students,name,students.age from students --可以遥过as给表起别名 select s.name,s.age from students as s --如果是单表查询可以省略表名 select name,age from students -使用as给字段起别名 select studentNo as 学号,name as 名字,sex as 性别 from students
条件
·使用where子句对表中的数据筛选,符号条件的数据会出现在结果集中
·语法如下
select 字段1,字段2...from 表名 where 条件; 例: select *from students Where id=1;
·where后面支持多种运算符,进行条件的处理
。比较运算
。逻辑运算
。模糊查询
。范围查询
。空判断
比较运算符
·等于:=
·大于:>
·大于等于:>=
·小于:<
·小于等于:<=
·不等于:!=或<>
例1:查询小乔的年龄 select age from students where name='小乔' 例2:查询20岁以下的学生 select * from students where age<20 例3:查询家乡不在北京的学生 select * from students where hometown!='北京'
逻辑运算符
·or
·not
·and
例1:查询年龄小于20的女同学 select * from students where age<20 and sex=‘女' 例2:查询女学生或1班”的学生 select * from students where sex='女”or class='1班’ 例3:查询非天津的学生 select * from students where not hometown=‘天津
模糊查询
·like
·%表示任意多个任意字符
·表示一个任意字符
例1:查询姓孙的学生 select *from students where name like ‘孙%' 例2:查询姓孙且名字是一个字的学生 select * from students where name like‘孙_' 例3:查询叫乔的学生 select *from students where name like '%乔!'
范围查询
·in表示在一个非连续的范围内
例1:查询家乡是北京或上海或广东的学生 select * from students where hometown in('北京”,‘上海’,‘广东”)
·between...and....表示在一个连续的范围内
例2:查询年龄为18至20的学生 select * from students where age between 18 and 20
空判断
·注意null与“是不同的
·判空is null
例1:查询没有填写身份证的学生
select * from students where card is null
·判非空is not null
例2:查询填写了身份证的学生
select* from students where card is not null
排序
·为了方便查看数据,可以对数据进行排序
·语法:
select *from 表名 order by 列1 asc l desc,列2 asc l desc..
·将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
·默认按照列值从小到大排列
·asc从小到大排列,即升序
·desc从大到小排序,即降序
例1:查询所有学生信息,按年龄从小到大排序
select *from students order by age
例2:查询所有学生信息,按年龄从大到小排序,年龄相同时,再按学号从小到大排序
select *from students order by age desc,studentNo
聚合函数
·为了快速得到统计数据,经常会用到如下5个聚合函数
·count(*)表示计算总行数,括号中写星与列名,结果是相同的
·聚合函数不能在where中使用
例1:查询学生总数
select count(*)from students;
·max()表示求此列的最大值
例2:查询女生的最大年龄
select max(age) from students where sex='女';
·min(列)表示求此列的最小值
例3:查询1班的最小年龄
select min(age) from students;
分组
·按照字段分组,表示此字段相同的数据会被放到一个组中
·分组后,分组的依据列会显示在结果集中,其他列不会显示在结果集中
·可以对分组后的数据进行统计,做聚合运算
·语法:
select 列1,列2,聚合.…from表名 group by 列1,列2...
例1:查询各种性别的人数
select sex,count(*) from students group by sex
例2:查询各种年龄的人数
select age,count(*) from students group by age
分组后的数据筛选
·语法:
select 列1,列2,聚合..from表名 group by 列1,列2,列3... having 列1.…聚合...
·having后面的条件运算符与where的相同
例1:查询男生总人数
方案一 select count(*)from students where sex='男’ 方案二: select sex,count(*)from students group by sex having sex='男'
获取部分行
·当数据量过大时,在一页中查看数据是一件非常麻烦的事情
·语法
select *from 表名 limit start,count
·从start开始,获取count条数据
·start索引从0开始
例1:查询前3行学生信息
select *from students limit 0,3
要求每页显示3条
select count(*)from students
12/3获取总页数
第一页
select* from students limit 0,3 3*(1-1)
第二页
select * from students limit 3,3 3*(2-1)
第三页
select * from students limit 6,3 3*(3-1)
第四页
select * from students limit 9,3 3*(4-1)
连接查询
·当查询结果的列来源于多张表时,需要将多张表连接成一个大的数据集,再选择合适的列返回
·等值连接查询:查询的结果为两个表匹配到的数据
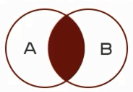
·左连接查询:查询的结果为两个表匹配到的数据加左表特有的数据,对于右表中不存在的数据使用null
填充

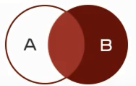
·右连接查询:查询的结果为两个表匹配到的数据加右表特有的数据,对于左表中不存在的数据使用null
填充
准备数据
drop table if exists courses;
create table courses( courseNo int(18) unsigned primary key auto_increment, name varchar(18) ); insertinto courses values ('1','数据库'), ('2',‘qtp'), ('3','linux'), ('4’,‘系统测试'), ('5,‘单元测试'), ('6',‘测试过程'); drop table if exists scores; create table scores( id int(10) unsigned primary key auto_increment, courseNo int(10), studentno varchar(10), score tinyint(4) ); insert into scores values ('1',‘1',‘001',‘90'), ('2',‘1',‘002','75'), ('3', '2',‘002','98'), ('4',‘3',‘001',‘86'), ('5',‘3',‘003',‘80'), ('6',‘4',‘004',‘79'), ('7',‘5',‘005',‘96'), ('8',‘6',‘006',‘80');
等值连接
方式一 select*from 表1,表2 where表1.列=表2.列
例1:查询学生信息及学生的成绩
select * from students,scores where students.studentno=scores.studentno
方式二(又称内连接)
不会产生笛卡尔积,不会产生临时表,性能高
select * from 表1 inner join 表2 on 表1.列=表2.列
select * from students inner join scores on students.studentno=scores.studentno
例2:查询课程信息及课程的成绩
select * from courses,scores where courses.courseNo=gcores.courseNo
select * from couses inner join acores on courses.courseNo=acores.courseNo
例3:查询学生信息及学生的课程对应的成绩
select from students,courses,scores where students.studentNo=scores.studentNo and scores.courseNo=courses.courselNo
select * from students inner join scores on students.studentNo=scores,studentNo inner join courses on scores.courseNo=courses.courseNo
左连接
select * from 表1 left join 表2 on表1.列=表2.列
例1:查询所有学生的成绩,包括没有成绩的学生
select from students stu left join scores sc on stu.studentNo=sc.studentNo
例1:查询所有学生的成绩,包括没有成绩的学生
左连接 : join前面的表称为左表 , join后面的表称为右表
select * from students left join scores on students.studentNo=scores.studentNo
例2:查询所有学生的成绩,包括没有成绩的学生,需要显示课程名
select *from students left join scores on students.studentNo-scores.studentNo left join courses on courses.courseNo=scores.courseNo
右连接
insert into courses values (0,语文), (0,数学);
例1:查询所有课程的成绩,包括没有成绩的课程
select * from scores rioht join courses on scores.courseNo=courses.courseNo
例2:查询所有课程的成绩,包括没有成绩的课程,包括学生信息 select* trom scores right join courses on scorea.courseNo-courses.courseNo right join students on students.studentNo=scores.studentNo.
子查询
·在一个select 语句中,嵌入了另外一个select 语句,那么被嵌入的select 语句称之为子查询语句
主查询
·主要查询的对象,第一条select语句
主查询和子查询的关系
·子查询是嵌入到主查询中
·子查询是辅助主查询的,要么充当条件,要么充当数据源
·子查询是可以独立存在的语句,是一条完整的 select 语句
子查询分类
·标量子查询:子查询返回的结果是一个数据(一行一列)
例一:查询大于平均年龄的学生 select avg(age) from students 21.5833 select * from students where age>21.5833 select *from students where age>(select avg(age)from students)
例2:查询王昭君的成绩,要求显示成绩 select studentNo from students where name='王昭君' select score from scores where studentNo=(select studentNo from students where name='王昭君')
·列子查询:返回的结果是一列(一列多行)
例3:查询18岁的学生的成绩,要求显示成绩 select *trom atudenta where age=18 select * from scores where studentNo in(1002','006') select * from scores where studentNo in (select studentno from students where age=18)
·行子查询:返回的结果是一行(一行多列)
例4:查询男生中年龄最大的学生信息 select * from students where sex='男‘ and age=(select max(age) from students) select * from students where (sex,age)=(‘男‘,30) select * from students where (sex,age)=(select sex,age from students where sex=‘男‘ order by age desc limit 1)
·表级子查询:返回的结果是多行多列
例5:查询数据库和系统测试的课程成绩 select from scores as s inner join (select * from courses where name in(‘数据库‘,‘系统测试’)) as c on s.courseNo=c.courseNo
子查询中特定关键字使用
·in 范围
。格式:主查询where条件in(列子查询)
·anyl some任意一个
。格式:主查询where列=any(列子查询)
。在条件查询的结果中匹配任意一个即可,等价于in
·all
。格式:主查询where列=all(列子查询):等于里面所有
。格式:主查询where列<>all(列子查询):不等一其中所有
数据库DOS命令
数据库
·查看所有数据库 show databases; ·使用数据库 use数据库名; ·查看当前使用的数据库 select database(); ·创建数据库 create database 数据库名 charset=ut棉; 例: create database ceshi charset=utf8; ·删除数据库 drop database数据库名; 例: drop database ceshi;
数据表
·查看当前数据库中所有表 show tables; ·查看表结构 desc 表名; 查看表的创建语句 show create table 表名; 例: show create table students;
备份
首先要以管理员身份运行
·运行mysqldump 命令 mysqldump -uroot -p 数据库名 > ceshi.sql #按提示输入mysqL的密码
恢复
·先创建新的数据库 mysql -uroot -p新数据库名<ceshi.sql #根据提示输入my5q1密码
内置函数
字符串函数
·拼接字符串 concat(str1,str2..) select concat(12,34,'ab'); ·包含字符个数 length(str) select length('abc'); ·截取字符串 。left(str,len)返回字符串str的左端len个字符 。right(str,len)返回字符串str的右端len个字符 。substring(str,pos,len)返回字符串str的位置pos起len个字符 select substring('abc123',2,3); ·去除空格 。trim(str)返回删除了左空格的字符串str 。rtrim(str)返回删除了右空格的字符串str select ltrim('bar '); ·大小写转换,函数如下 。lower(str) 。upper(str) select lower('aBcD');
数学函数
·求四舍五入值round(n.d),n表示原数,d表示小数位置,默认为0 select round(1.6); ·求x的y次幂pow(x.y) select pow(2,3); ·获取圆周率Pl() select PI(); ·随机数rand(),值为0-1.0的浮点数 select rand(); 随机0-10的整数 select round(rand()*18) 随机从一个表中取一条记录 select * from goods order by rand() limit 1
日期时间函数
·当前日期current_date0 select current_date(); ·当前时间current_time0 select current_time(); ·当前日期时间now0 select now(); ·日期格式化date_fomat(date,format) ·参数format可选值如下 %Y获取年,返回完整年份 %y获取年,返回简写年份 %册获取月,返回月份 %d获取日,返回天值 H获取时,返回24进制的小时数 %h获取时,返回12进制的小时数 i获取分,返回分钟数 %s获取秒,返回秒数 ·例:将使用-拼接的日期转换为使用空格拼接 select date_format('2016-12-21','%Y %m %d");
流程控制
·case语法:等值判断 ·说明:当值等于某个比较值的时候,对应的结果会被返回;如果所有的比较值都不相等则返回else的结果;如果没有else并且所有比较值都不相等则返回null case 值 when 比较值1 then结果1 when 比较值2 then 结果2...else 结果end 例: select case 1 when 1 then ‘one' when 2 then ‘two' else 'zero' end as result;
自定义函数
创建 ·语法如下 delimiter $$ create function函数名称(参数列表)returns 返回类型 begin sql语句 end $$ delimiter;
·说明:delimiter用于设置分割符,默认为分号 ·在“sql语句”部分编写的语句需要以分号结尾,此时回车会直接执行,所以要创建存储过程前需要指定其它符号作为分割符,此处使用∥,也可以使用其它字符
示例 ·要求:创建函数my_trim,用于删除字符串左右两侧的空格 ·step1:设置分割符 delimiter $$ ·step2:创建函数 create function my_trim(str varchar(100)) returns varchar(100) begin return ltrim(rtrim(str)); end * $$ ·step3:还原分割符 delimiter;
创建
·语法如下 delimiter// create procedure 存储过程名称(参数列账) begin sql语句 end // delimiter; ·说明:delimiter用于设置分割符,默认为分号 ·在“sql语句”部分编写的语句需要以分号结尾,此时回车会直接执行,所以要创建存储过程前需要指定其它符号作为分割符,此处使用∥,也可以使用其它字符
调用
·语法如下
call存储过程(参数列表);
调用存储过程proc_stu
call proc_stu();
·存储过程和函数都是为了可重复的执行操作数据库的sql语句的集合。
·存储过程和函数都是一次编译,就会被缓存起来,下次使用就直接命中缓存中已经编译好的sql,不需要重复编译
·减少网络交互,减少网络访问流量
视图
·对于复杂的查询,在多个地方被使用,如果需求发生了改变,需要更改sql语句,则需要在多个地方进行修改,维护起来非常麻烦 ·解决:定义视图 ·视图本质就是对查询的封装 ·定义视图,建议以v开头 create view 视图名称 as select 语句; ·例:创建视图,查询学生对应的成绩信息 create view v_stu_score_course as select stu.*,cs.courseNo,Cs.name courseName,sc.score from students stu inner join scores sc on stu.studentNo = sc.studentNo inner join courses cs on cs.courseNo = sc.courselo ·查看视图:查看表会将所有的视图也列出来 show tables; ·删除视图 drop view 视图名称; 例: drop view v_stu_score_course; ·使用:视图的用途就是查询 select * from v_stu_score_course;
事务
为什么要有事务?
·事务广泛的运用于订单系统、银行系统等多种场景
·例如:A用户和B用户是银行的储户,现在A要给B转账500元,那么需要做以下几件事:
1.检查A的账户余额>500元;
2.A账户中扣除500元;
3.B账户中增加500元;
·正常的流程走下来,A账户扣了500,B账户加了500,皆大欢喜。那如果A账户扣了钱之后,系统出故障了呢?A白白损失了500,而B也没有收到本该属于他的500。以上的案例中,隐藏着一个前提条件:A扣钱和B加钱,要么同时成功,要么同时失败。事务的需求就在于此
·所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转帐工作:从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。所以,应该把他们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性
转账 大乔500 小乔200 begin; update account set money=money-100 where name=‘大乔! update account set money=money+100 where name=‘小乔! 。。。。。。。。。。。 。。。。。。。。。。。 若以上所有操作都成功 commit; begin; 任何一步失败 rollback;
索引
语法 ·查看索引 show index from表名; ·创建索引 方式一:建表时创建索引 create table create_index( id int primary key, name varchar(10)unique, age int, key(age) ); 方式二:对于已经存在的表,添加索引 如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致 字段类型如果不是字符串,可以不填写长度部分 create index索引名称 on表名(字段名称(长度)) 例: create index age_index on create_index(age); create index name_index on create_index(name(10)); ·删除索引: drop index索引名称on表名;
示例
查询 ·开启运行时间监测: set profiling=1; ·查找第1万条数据test10000 select * from test_index where title='test10000'; ·查看执行的时间: show profiles; ·为表itle_index的title列创建索引: create index title_index on test_index(title(10)); ·执行查询语句: select* from test_index where title='test10000'; ·再次查看执行的时间 show profiles; 缺点 ·虽然索引大大提高了查询速度,同时却会降凭更新表的速度,如对表进行INSERT、UPDATE和DELETE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件 ·但是,在互联网应用中,查询的语句远远大于增别改的语句,甚至可以占到80%~90%,所以也不要太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引
外键foreign key
·如果一个实体的某个字段指向另一个实体的主键,就称为外键。被指向的实体,称之为主实体(主表),也叫父实体(父表)。负责指向的实体,称之为从实体(从表),也叫子实体(子表) ·对关系字段进行约束,当为从表中的关系字段填写值时,会到关联的主表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并报错 语法 ·查看外键 show create table 表名 ·设置外键约束 方式一:创建数据表的时候设置外键约束 create table class( id int unsigned primary key auto_increment, name varchar(10) create table stu( name varchar(10), class_id int unsigned, foreign key(class_id)references class(id) ); foreign key(自己的字段)references 主表(主表字段) 方式二:对于已经存在的数据表设置外键约束 alter table 从表名 add foreign key(从表字段)references 主表名(主表字段); alter table stu add foreign key(class_id)references class(id); ·删除外键 需要先获取外键约束名称 show create table stu; 获取名称之后就可以根据名称来删除外键约束 alter table 表名 drop foreign key 外键名称; alter table stu drop foreign key stu_ibfk_1; 在实际开发中,很少会使用到外键约束,会极大的降低表更新的效率
修改密码
·使用root登录,修改mysql数据库的user表 。使用password0函数进行密码加密 。注意修改完成后需要刷新权限 use mysql; update user set pas sword=password(’新密码”)where user='用 户名’; 例: update user set password=password('123')where user='root'; 刷新权限:flush privileges;
忘记root账户密码怎么办?
1、配置mysql登录时不需要密码,修改配置文件 ·Centos中:配置文件位置为/etc/my.cnf ·Windows中:配置文件位置为C:\\Program Files(×86)MySQL\\MySQL Server 5.1\\my.ini 修改,找到mysqld,在它的下一行,添加skip-grant-tables [mysqld] skip-grant-tables 2、重启mysql,免密码登录,修改mysql数据库的user表 use mysql; update user set password=password('新密码”)where user=‘用户名’; 例: update user set password=password('123') where user='root'; 刷新权限:flush privileges; 3、还原配置文件,把刚才添加的skip-grant-tables刷除,重启

