alertmanger
1. 安装alertmanger
1 2 3 | wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gztar -zxvf alertmanager-0.21.0.linux-amd64.tar.gz -C /usr/localcd /usr/local/alertmanager-0.21.0.linux-amd64 |
2. 启动
1 | ./alertmanger |
3. 编写启动文件启动
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | [Unit]Description=alertmanagerAfter=network.target[Service]Type=simpleUser=rootGroup=rootWorkingDirectory=/usr/local/alertmanagerExecStart=/bin/sh -c '/usr/local/alertmanager/alertmanager --web.external-url=http://192.168.17.12:9093/ --log.level=debug >>/usr/local/alertmanager/alertmanager.log 2>&1 'Restart=on-failure[Install]WantedBy=multi-user.target |
4. 启动服务
1 | systemctl daemon-reload && systemctl enable alertmanager.service && systemctl start alertmanager.service |
5. 新建报警文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | cd /usr/local/prometheus/prometheus-2.46.0.linux-amd64/mkdir rulescat node_rule.yml# groups:组告警groups:# name:组名。报警规则组名称- name: general.rules # rules:定义角色 rules: # alert:告警名称。 任何实例5分钟内无法访问发出告警 - alert: NodeFilesystemUsage # expr:表达式。 获取磁盘使用率 大于百分之80 触发 expr: 100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80 # for:持续时间。 表示持续一分钟获取不到信息,则触发报警。0表示不使用持续时间 for: 1m # labels:定义当前告警规则级别 labels: # severity: 指定告警级别。 severity: warning # annotations: 注释 告警通知 annotations: # 调用标签具体指附加通知信息 summary: "Instance {{ $labels.instance }} :{{ $labels.mountpoint }} 分区使用率过高" # 自定义摘要 description: "{{ $labels.instance }} : {{ $labels.job }} :{{ $labels.mountpoint }} 这个分区使用大于百分之80% (当前值:{{ $value }})" # 自定义具体描述 - alert: CpuUserdAlert <br> # cpu使用率大于7就报警 expr: (1 - avg(rate(node_cpu_seconds_total{host="node1",env=~"test",mode="idle"}[5m])) by (instance)) * 100 > 7 for: 1m labels: severity: warning annotations: summary: "cpu使用率过高" description: "cpu使用率过高" |
6. prometheus主配置文件关联报警文件,在rule_files下面引用报警文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).# Alertmanager configurationalerting: alertmanagers: - static_configs: - targets: - localhost:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files: - "/usr/local/prometheus/prometheus-2.46.0.linux-amd64/rules/node_rule.yml" # - "first_rules.yml" # - "second_rules.yml" |
7. 报警效果
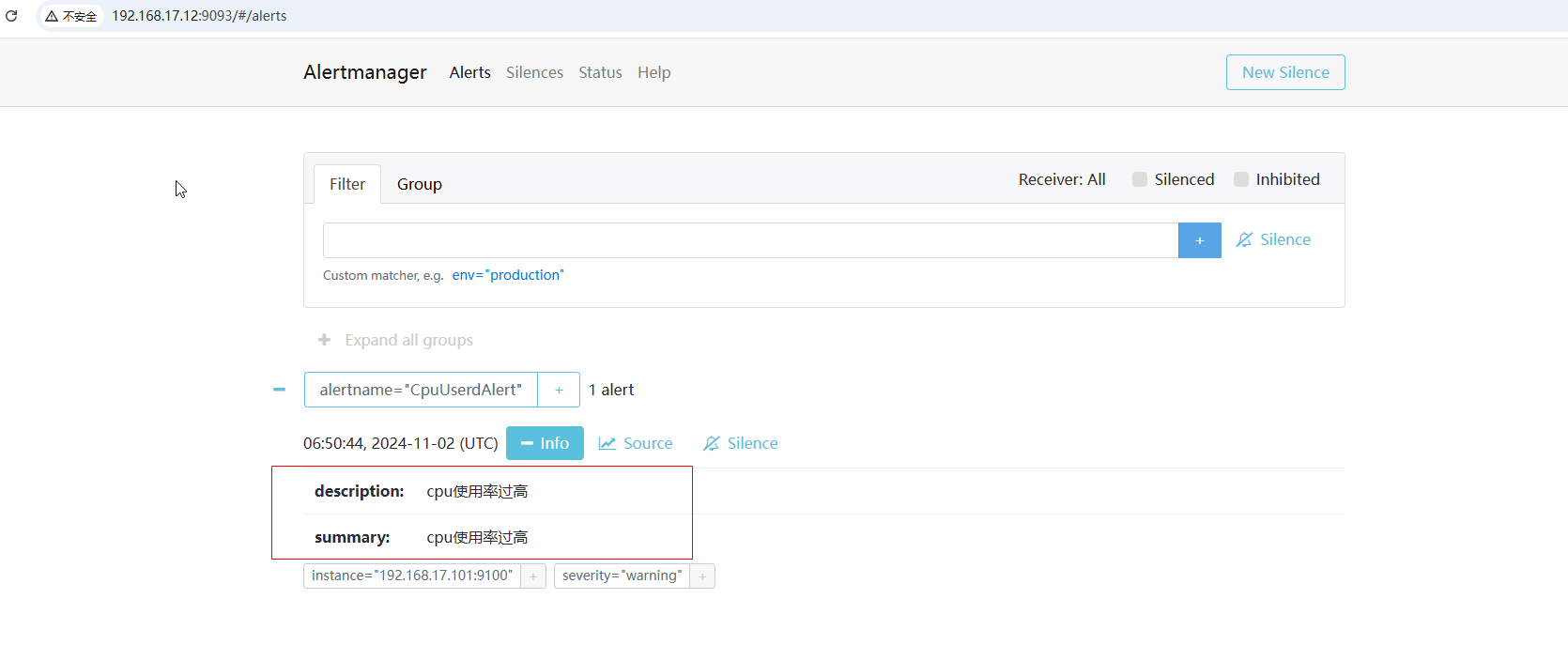


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律