
【SQL查询】获取分区里最大和最小值_first_value/last_value
FIRST_VALUE | LAST_VALUE
1. 语法
FIRST_VALUE | LAST_VALUE ( expression [ IGNORE NULLS | RESPECT NULLS ] ) OVER ( [ PARTITION BY expr_list ] [ ORDER BY order_list frame_clause ] )
2. 参数说明
【expression】:对其执行函数的目标列或表达式。
【IGNORE NULLS】:将此选项与 FIRST_VALUE 结合使用时,该函数返回不为 NULL 的框架中的第一个值(如果所有值为 NULL,则返回 NULL)。将此选项与 LAST_VALUE 结合使用时,该函数返回不为 NULL 的框架中的最后一个值(如果所有值为 NULL,则返回 NULL)。
【RESPECT NULLS】:指示 Amazon Redshift 应包含 null 值以确定要使用的行。如果您未指定 IGNORE NULLS,则默认情况下不支持 RESPECT NULLS。
【OVER】:引入函数的窗口子句。
【PARTITION BY expr_list】:依据一个或多个表达式定义函数的窗口。
【ORDER BY order_list】:对每个分区中的行进行排序。如果未指定 PARTITION BY 子句,则 ORDER BY 对整个表进行排序。如果指定 ORDER BY 子句,则还必须指定frame_clause。
3.示例
- 初始化脚本


/*创建表格(emp)*/
create table emp(
EMPNO NUMBER(4) primary key,
ENAME VARCHAR2(10),
JOB VARCHAR2(9),
MGR NUMBER(4),
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER(2)
);
/*向表格中插入数据*/
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7369, 'SMITH', 'CLERK', 7902, to_date('1980-12-17','YYYY-MM-DD'), 800, NULL, 20);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7499, 'ALLEN', 'SALESMAN', 7698, to_date('1981-02-20','YYYY-MM-DD'), 1600, 300, 30);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7521, 'WARD', 'SALESMAN', 7698, to_date('1981-02-22','YYYY-MM-DD'), 1250, 500, 20);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7566, 'JONES', 'MANAGER', 7839, to_date('1981-04-02','YYYY-MM-DD'), 2975, NULL, 20);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7654, 'MARTIN', 'SALESMAN', 7698, to_date('1981-09-28','YYYY-MM-DD'), 1250, 1400, 30);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7698, 'BLAKE', 'MANAGER', 7839, to_date('1981-05-01','YYYY-MM-DD'), 2845, NULL, 30);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7782, 'CLARK', 'MANAGER', 7839, to_date('1981-06-09','YYYY-MM-DD'), 2450, NULL, 10);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7788, 'SCOTT', 'ANALYST', 7566, to_date('1987-04-19','YYYY-MM-DD'), 3000, NULL, 20);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7839, 'KING', 'PRESIDENT', NULL, to_date('1981-11-17','YYYY-MM-DD'), 5000, NULL, 10);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7844, 'TURNER', 'SALESMAN', 7698, to_date('1981-09-08','YYYY-MM-DD'), 1500, 0, 30);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7876, 'ADAMS', 'CLERK', 7788, to_date('1987-05-23','YYYY-MM-DD'), 1100, NULL, 20);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7900, 'JAMES', 'CLERK', 7698, to_date('1981-12-03','YYYY-MM-DD'), 950, NULL, 30);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7902, 'FORD', 'ANALYST', 7566, to_date('1981-12-03','YYYY-MM-DD'), 3000, NULL, 20);
insert into emp (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7934, 'MILLER', 'CLERK', 7782, to_date('1982-01-23','YYYY-MM-DD'), 1300, NULL, 10);
commit;
- FIRST_VALUE: 获取每个部门最高的工资
select emp.*, first_value(emp.sal) over(partition by emp.deptno order by emp.sal desc) "最高工资" from emp
结果:

- LAST_VALUE:获取每个部门最低工资
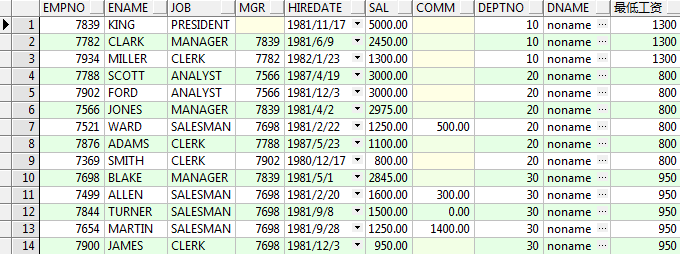
select emp.*, last_value(emp.sal) over(partition by emp.deptno order by emp.sal desc) "最低工资" from emp
结果:

和预期的结果不一样,系统未获取分区中最小的工资。根本原因如下:last_value()默认统计范围是:rows between unbounded preceding and current row, 而应该采用以下的统计范围: rows between unbounded preceding and unbounded following(两者统计范围的差别,可参考注释)。修改代码如下:
select emp.*, last_value(emp.sal) over(partition by emp.deptno order by emp.sal desc rows between unbounded preceding and unbounded following) "最低工资" from em
结果:
注:
unbounded:无界限
preceding:从分区第一行头开始,则为 unbounded。 N为:相对当前行向前的偏移量
following :与preceding相反,到该分区结束,则为 unbounded。N为:相对当前行向后的偏移量
current row:顾名思义,当前行,偏移量为0

