
storm(一)
storm 处理数据的方式是基于消息的流水线处理,因此特别适合无状态的计算,也就是说计算单元依赖的数据全部在接受的消息中可以找到。
storm架构图
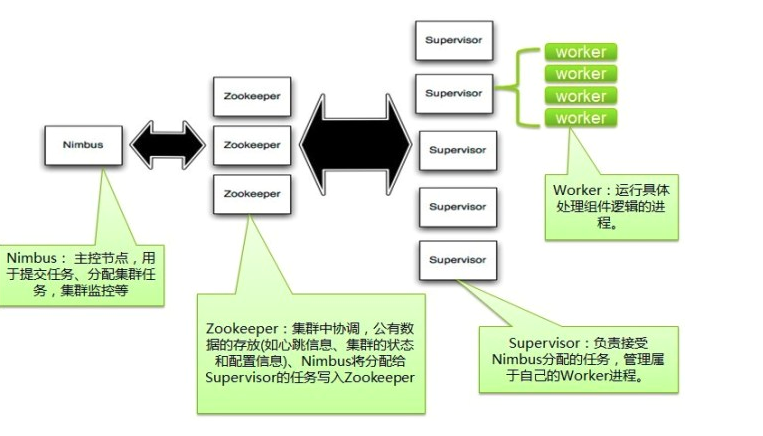
Nimbus:
storm集群的master节点,负责分发用户代码,指派给具体的supervisor节点上的worker节点,取运行topology对应的组件(spout/bolt)的task
supervisor:
负责接收nimbus分配的任务,启动和暂停属于自己管理的worker进程。通过storm配置文件中的supervisor.slots.ports配置项,可以指定在一个supervisor上最大允许多少个slot,每个slot通过端口号来唯一标识,一个端口号对应一个worker进程(如果该worker进程被启动)。
worker:
运行具体处理组件逻辑的进程。worker的任务类型只有两种,一种是spout任务,一种是bolt任务。
Task:
worker 中每一个spout/bolt的线程称为一个task。同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。(worker下面是executor,executor下面是task)
zookeeper:
用来协调nimbus和supervisor,如果supervisor因故障出现问题而无法运行topology,nimbus会第一时间感知到,并重新分配topology到其他可用的supervisor上运行
Storm编程模型
storm程序在运行过程中主要有spout和bolt这两个组件,数据源重spout开始,数据已tuple的方式发送到bolt
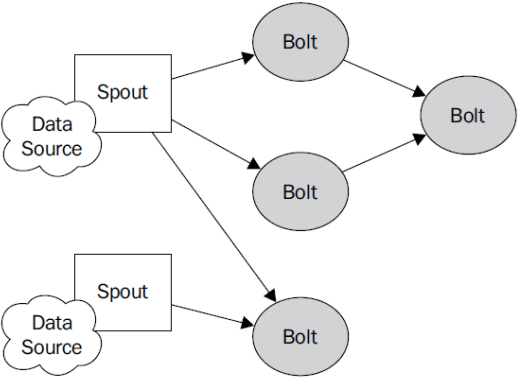
Topologies:
storm中运行的一个事实应用程序的名称。将spout,bolt整合起来的拓扑图。定义了spout和bolt的结合关系,并发数量,配置等等。
spout:
topology 中获取源数据流的组件,一般spout会从外部数据源读取数据然后将它们发送到拓扑中。根据需求不同,spout既可以定义为可靠的数据源,也可以定义为不可靠的数据源。可靠的数据可以再发送失败的时候重新发送该元组,以确保所有的元组都能得到正确的处理;不可靠的spout就不会再元组发送之后进行其他的任何操作。
Bolt:
拓扑中所有的数据处理均是由bolt完成的。通过数据过滤,函数处理,聚合,关联(joins),数据库交互等功能。bolt几乎能够完成任何一种数据处理需求。
Tuple:
一次消息传递的基本单元,理解为一组消息就是一个tuple
Stream: tuple的集合,标识数据的流向
Stream grouping
也就是消息是怎么划分的。
-
随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。 跨服务器通信,浪费网络资源,尽量不适用
-
无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)
-
字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。 跨服务器,除非有必要,才使用这种方式。
-
全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。 人人都有,完全没有必要
-
全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
-
直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收
-
LocalOrShuffle 分组。 优先将数据发送到本地的Task,节约网络通信的资源
Streams: 一个数据流指定的在分布式环境中并行创建,处理的一组元组的无界序列

