1.配置HDFS HA (高可用)
前提条件
先搭建zk环境并启动:https://www.cnblogs.com/zhugq02/p/15759195.html
架构规划:
192.168.167.82 node2 nn\zk1\zkfc
192.168.167.83 node3 jn\zk2\dn
192.168.167.84 node4 jn\zk3\dn
192.168.167.85 node5 nn\jn\dn
一、环境初始化(所有节点)
1.关闭防火墙和iptables
systemctl stop firewalld && systemctl status firewalld
service iptables stop && service iptables status2.同步时钟服务
ntpdate -u ntp.sjtu.edu.cn3.免密码登录
两台namenode节点(node2\node5)互相免密设置
1>.先在node2执行
ssh-keygen -t rsa
ssh-copy-id -i node2
ssh-copy-id -i node5
2>.在node5上执行
ssh-keygen -t rsa
ssh-copy-id -i node2
ssh-copy-id -i node5
3>.完成后分别在node2和node5连接node2和node5验证免密设置是否成功
ssh node2
ssh node54.配置hosts文件
vi /etc/hosts
192.168.167.82 node2
192.168.167.83 node3
192.168.167.84 node4
192.168.167.85 node5二、软件部署
1.下载hadoop软件,并解压到/usr/local目录下
tar xf hadoop-2.10.0.tar.gz -C /usr/local/2.下载java软件,并解压到/usr/local目录下
tar xf jdk-8u231-linux-x64.tar.gz -C /usr/local/ && mv /usr/local/jdk-8u231-linux-x64 /usr/local/java_643.环境变量配置
#vi /etc/profile
export JAVA_HOME=/usr/local/java_64
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-2.10.0
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使环境变量生效
# . /etc/profile4.配置文件配置
进入配置文件目录:
# cd /usr/local/hadoop-2.10.0/etc/hadoop/
# vi core-site.xml
<configuration>
<!--指定hdfs的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://qf</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>qf</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zk的集群地址,用来协调namenode服务-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
</configuration>
==========================================================================================
# vi hdfs-site.xml
<configuration>
<!--副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--块大小-->
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<!--hdfs元数据存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/name</value>
</property>
<!--hdfs数据存储的位置-->
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/hadoop/data</value>
</property>
<!--指定hdfs的虚拟服务名-->
<property>
<name>dfs.nameservices</name>
<value>qf</value>
</property>
<!--指定hdfs虚拟服务名下的namenode的名字-->
<property>
<name>dfs.ha.namenodes.qf</name>
<value>node2,node5</value>
</property>
<!--指定namenode的内部通信地址-->
<property>
<name>dfs.namenode.rpc-address.qf.node2</name>
<value>node2:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.qf.node5</name>
<value>node5:9000</value>
</property>
<!--指定namenode的web ui通信地址-->
<property>
<name>dfs.namenode.http-address.qf.node2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.qf.node5</name>
<value>node5:50070</value>
</property>
<!--指定jouranlnode数据共享目录-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/qf</value>
</property>
<!--指定jouranlnode本地共享目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journaldata</value>
</property>
<!--开启namenode失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定namenode失败进行自动切换的主类-->
<property>
<name>dfs.client.failover.proxy.provider.qf</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--防止多个namenode同active(脑裂),采用某种方式杀死其中一个-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
=============================================================================================
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
# 该cluster-id不能与nameService相同
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>qf1521</value>
</property>
#指定2台Resource Manager (即Name Node )节点
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>node2,node5</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.node2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.node5</name>
<value>node5</value>
</property>
#指定zookeeper 节点
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
================================================================================
# mv mapred-site.xml.template mapred-site.xml
# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5.配置hadoop启停脚本文件用户
1>. 在start-dfs.sh和stop-dfs.sh中头部加入如下代码:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root2>. 在start-yarn.sh和stop-yarn.sh中头部加入如下代码:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=root
YARN_NODEMANAGER_USER=root6.启停应用服务
1>.启动journalnode
在node3\node4\node5启动journalnode服务,分别执行以下命令
hadoop-daemon.sh start journalnode
执行jps查看journalnode是否启动2>.初始化namenode和zkfc并启动
在node2上执行如下命令:
hdfs namenode -format(首次启动执行)
hadoop-daemon.sh start namenode
hdfs zkfc -formatZK(首次启动执行)
hadoop-daemon.sh start zkfc
start-dfs.sh
在node5上执行如下命令:
hdfs namenode -bootstrapStandby(首次启动执行)
hadoop-daemon.sh start namenode
hadoop-daemon.sh start zkfc注:Hadoop在执行start-dfs.sh 命令出现,“Error:JAVA_HOME is not set and could not be found ”这一错误提出解决办法。
vi /usr/local/hadoop-2.10.0/etc/hadoop/hadoop-env.sh
将语句 export JAVA_HOME=$JAVA_HOME
修改为 export JAVA_HOME=/usr/local/java_64
保存后退出。
再次输入start-dfs.sh启动hadoop。3>.测试
在浏览器地址栏输入 http://192.168.167.82:50070和http://192.168.167.85:50070查看谁是active谁是standby 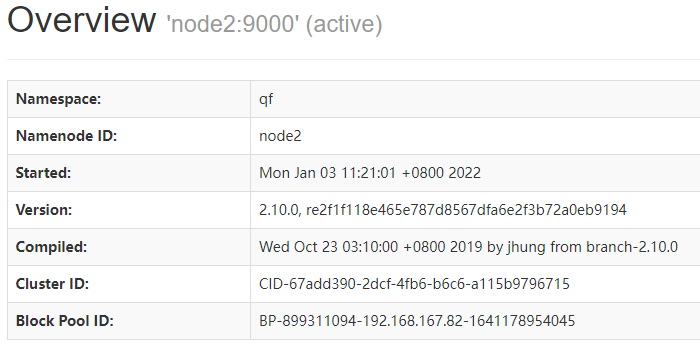
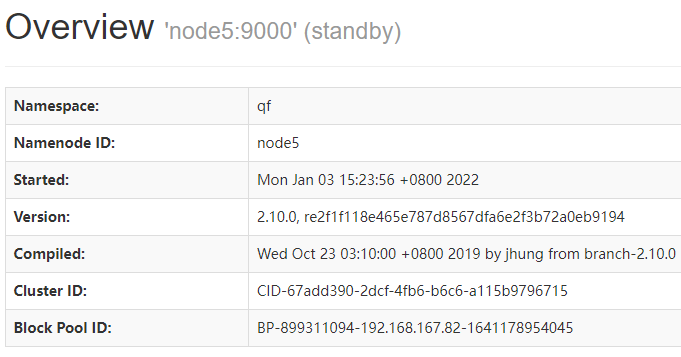
我的机器是node2为active,node5为standby
所以在node2上杀死namenode进行,查看node5状态是否变为active
注:问题:hadoop HA自动切换不成功
配置好之后杀掉active的namenode,另一台服务器并没有变为active
解决办法:在nn节点上分别安装psmisc并重启服务器
# yum install psmisc 7.使用Yarn来调度HDFS
1>. 先所有的Hadoop相关进程
# stop-dfs.sh2>. 启动 yarn
单独启动yarn使用命令:
# start-yarn.sh
# stop-yarn.sh
启动所有Hadoop相关进程使用命令
# start-all.sh
#启动完成以后,另一台NameNode需要手动启动yarn
# start-yarn.sh8. 访问 yarn
访问yarn的端口 http://node2:8088 http://node5:8088 可以看到: