


MySQL索引
一、介绍
1、什么是索引
①索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。索引时一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
②通俗的讲,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。在没有索引的情况下,数据库会按照顺序逐条遍历记录,直至找到需要的数据为止。而有了相应的索引之后,数据库会直接在索引中查找符合条件的选项,直接在索引中定位需要的数据。
③通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
2、 索引的原理
索引一般以文件形式存在磁盘中(也可以存于内存中),存储的索引的原理大致概括为以空间换时间,数据库在未添加索引的时候进行查询默认的是进行全量搜索,也就是进行全局扫描,有多少条数据就要进行多少次查询,然后找到相匹配的数据就把他放到结果集中,直到全表扫描完。而建立索
引之后,会将建立索引的KEY值放在一个n叉树上(BTree)。因为B树的特点就是适合在磁盘等直接存储设备上组织动态查找表,每次以索引进行条件查询时,会去树上根据key值直接进行搜索。
3、索引的优点:建立索引的目的是加快对表中记录的查找或排序
① 建立索引的列可以保证行的唯一性,生成唯一的rowId
② 建立索引可以有效缩短数据的检索时间
③ 建立索引可以加快表与表之间的连接
④ 为用来排序或者是分组的字段添加索引可以加快分组和排序顺序
4、索引的缺点
① 创建索引和维护索引需要时间成本,这个成本随着数据量的增加而加大
② 创建索引和维护索引需要空间成本,每一条索引都要占据数据库的物理存储空间,数据量越大,占用空间也越大(数据表占据的是数据库的数据空间)
③ 会降低表的增删改的效率,因为每次增删改索引需要进行动态维护,导致时间变长
二、聚簇索引与非聚簇索引
1、聚簇索引
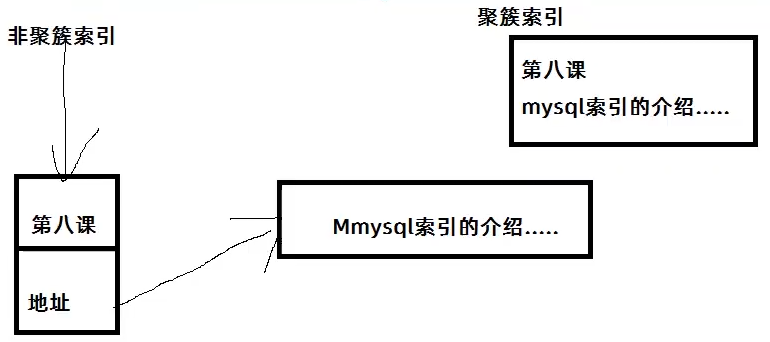
①InnoDB将通过主键聚集数据,如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引,一个表只能有一个聚簇索引
②聚簇索引可以说是一种索引,也可以说是一种数据存储的方式。它的索引号和对应的记录是存在一起的。存储数据的顺序和索引顺序一致
③优势:当主键为自增时,做按主键的范围查询
④缺点:主键如果时uuid,无法保证顺序,做范围条件查询时,开销很大
2、非聚簇索引
①非聚簇索引的叶子节点仍然是索引节点,只有有指向对应数据块的指针
②一张表可以最多建249个非聚簇索引,建索引需要额外的内存。索引不是越多越好。每次往表里插入数据时,要同步更新索引。所以建索引是要慎重考虑
③非聚簇索引中叶子节点的记录中需要保存主键,如需访问记录中其他部分还需要通过主键回表查询。即两次索引查找。有人疑问非聚簇索引中为什么不保存记录项的物理地址呢,当然可以记录物理地址,但是主键索引更新操作带来的索引分裂合并会改变其物理地址,这样索引的维护代价比较大,而即使回表查询,主键查找速度一般较快,影响不大。另外也可以通过覆盖索引【即索引项覆盖了select中的项】避免回表查询
三、索引的数据结构分类
mysql默认存储引擎innodb只显式支持B树索引,对于频繁访问的表,innodb会透明建立自适应hash索引, 即在B树索引基础上建立hash索引,可以显著提高查找效率,对于客户端是透明的,不可控制的,隐式的。支持范围查询,前缀匹配查询,等值查询,可以避免排序
1、B+TREE,索引用的数据结构时B+TREE,B是balance,成为
①普通索引
②唯一性索引:普通索引+字段取值必须唯一
③主键自带索引
④联合索引(多列)
2、HASH索引
①通过hash函数将键值直接映射为物理存储地址,使时间复杂度降低到O(1),本身存储是无序的,所以不能通过hash索引避免排序
②很快、占内存,需要算hash值。只支持包括 “=” "in "在内的等值查询,不支持范围、前缀匹配查询
3、Mysql采用B+TREE索引的原因
B-树和B+树的区别在于B+树所有键值全部保存在叶子节点,而B-树则不然,B-树的键值根据树的结构分布在整个树上
①遍历方便。B+树可以将键值保存在(线性表【数组或链表】)中,遍历线性表比索引树要快,因为保存在线性表中数据存储更加密集,B-Tree分散的 存储会导致更多的随机I/O,对于磁盘访问,随机I/O是比顺序I/O慢很多的,因为随机I/O需要额外的磁头寻道操作。顺序I/O有效减少寻道的次数
②插入更新索引树时可以避免移动节点
③遍历任何节点的时间复杂度相同,即访问路径总是从根节点到叶子节点.相比B-树,访问时间略长.所以某些高频访问的搜索采用B-树,即访问频率越高 使其距离根节点越近
④范围查找方便。对于[A,B]区间的范围查找,B-树索引可以直接找到A,B对应的线性表中节点,只需要返回区间的所有节点 即为目标结果。而B-树则稍显麻烦需要继续遍历索引树
四、Mysql索引管理
1、MySQL的索引分类
① 普通索引:index:加速查找
② 唯一索引:unique:加速查找+约束(唯一)
③ 主键索引:primary key :加速查找+约束(不为空且唯一)
④ 联合索引
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
⑤ 全文索引fulltext:用于搜索很长一篇文章的时候,效果最好
2、索引创建的语句
CREATE TABLE table_name[col_name data type][unique|fulltext][index|key][index_name](col_name[length])[asc|desc]
-
unique|fulltext为可选参数,分别表示唯一索引、全文索引
-
index和key为同义词,两者作用相同,用来指定创建索引
-
col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择
-
index_name指定索引的名称,为可选参数,如果不指定,默认col_name为索引值
-
length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度
-
asc或desc指定升序或降序的索引值存储
3、索引的创建
(1)普通索引(单列索引):单列索引是最基本的索引,它没有任何限制。
① 直接创建索引:CREATE INDEX index_name ON table_name(col_name);
② 修改表结构的方式添加索引:ALTER TABLE table_name ADD INDEX index_name(col_name);
③ 创建表的时候同时创建索引
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
CREATE TABLE `news` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` varchar(255) NOT NULL ,
`content` varchar(255) NULL ,
`time` varchar(20) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
INDEX index_name (title(255))
)
(2)复合索引(组合索引):复合索引是在多个字段上创建的索引。复合索引遵守“最左前缀”原则,即在查询条件中使用了复合索引的第一个字段,索引才会被使用。因此,在复合索引中索引列的顺序至关重要。
① 创建复合索引:create index index_name on table_name(col_name1,col_name2,...);
② 修改表结构的方式添加索引:alter table table_name add index index_name(col_name,col_name2,...);
(3)唯一索引:唯一索引和普通索引类似,主要的区别在于,唯一索引限制列的值必须唯一,但允许存在空值(只允许存在一条空值)
如果在已经有数据的表上添加唯一性索引的话:
- 如果添加索引的列的值存在两个或者两个以上的空值,则不能创建唯一性索引会失败。(一般在创建表的时候,要对自动设置唯一性索引,需要在字段上加上 not null)
- 如果添加索引的列的值存在两个或者两个以上的null值,还是可以创建唯一性索引,只是后面创建的数据不能再插入null值 ,并且严格意义上此列并不是唯一的,因为存在多个null值。
对于多个字段创建唯一索引规定列值的组合必须唯一。
比如:在order表创建orderId字段和 productId字段 的唯一性索引,那么这两列的组合值必须唯一!
“空值” 和”NULL”的概念:
1:空值是不占用空间的 .
2: MySQL中的NULL其实是占用空间的.
长度验证:注意空值的之间是没有空格的。
> select length(''),length(null),length(' ');
+------------+--------------+-------------+
| length('') | length(null) | length(' ') |
+------------+--------------+-------------+
| 0 | NULL | 1 |
+------------+--------------+-------------+
① 创建唯一索引
# 创建单个索引 CREATE UNIQUE INDEX index_name ON table_name(col_name); # 创建多个索引 CREATE UNIQUE INDEX index_name on table_name(col_name,...);
② 修改表结构
# 单个 ALTER TABLE table_name ADD UNIQUE index index_name(col_name); # 多个 ALTER TABLE table_name ADD UNIQUE index index_name(col_name,...);
③ 创建表的时候直接指定索引
CREATE TABLE `news` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` varchar(255) NOT NULL ,
`content` varchar(255) NULL ,
`time` varchar(20) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
UNIQUE index_name_unique(title)
)
(4)主键索引:主键索引是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引
① 主键索引(创建表时添加)
CREATE TABLE `news` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` varchar(255) NOT NULL ,
`content` varchar(255) NULL ,
`time` varchar(20) NULL DEFAULT NULL ,
PRIMARY KEY (`id`)
)
② 主键索引(创建表后添加)
alter table tbl_name add primary key(col_name);
CREATE TABLE `order` (
`orderId` varchar(36) NOT NULL,
`productId` varchar(36) NOT NULL ,
`time` varchar(20) NULL DEFAULT NULL
)
alter table `order` add primary key(`orderId`);
(5)全文索引
在一般情况下,模糊查询都是通过 like 的方式进行查询。但是,对于海量数据,这并不是一个好办法,在 like “value%” 可以使用索引,但是对于 like “%value%” 这样的方式,执行全表查询,这在数据量小的表,不存在性能问题,但是对于海量数据,全表扫描是非常可怕的事情,所以 like 进行模糊匹配性能很差。
这种情况下,需要考虑使用全文搜索的方式进行优化。全文搜索在 MySQL 中是一个 FULLTEXT 类型索引。FULLTEXT 索引在 MySQL 5.6 版本之后支持 InnoDB,而之前的版本只支持 MyISAM 表。
全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。目前只有char、varchar,text 列上可以创建全文索引。
小技巧:在数据量较大时候,先将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
① 创建表的适合添加全文索引
CREATE TABLE `news` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` varchar(255) NOT NULL ,
`content` text NOT NULL ,
`time` varchar(20) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
FULLTEXT (content)
)
② 修改表结构添加全文索引:ALTER TABLE table_name ADD FULLTEXT index_fulltext_content(col_name)
③ 直接创建索引:CREATE FULLTEXT INDEX index_fulltext_content ON table_name(col_name)
4、索引的查询和删除
索引的查看:
show indexes from `表名`;
或者
show keys from `表名`;
索引的删除:
DROP INDEX index_name ON table_name;
或者
alter table `表名` drop index 索引名;
五、正确使用索引
1、覆盖索引
select * from s1 where id=123;
该sql命中了索引,但未覆盖索引。
利用id=123到索引的数据结构中定位到该id在硬盘中的位置,或者说再数据表中的位置。
但是我们select的字段为*,除了id以外还需要其他字段,这就意味着,我们通过索引结构取到id还不够,
还需要利用该id再去找到该id所在行的其他字段值,这是需要时间的,很明显,如果我们只select id,
就减去了这份苦恼,如下
select id from s1 where id=123;
这条就是覆盖索引了,命中索引,且从索引的数据结构直接就取到了id在硬盘的地址,速度很快

2、联合索引

3、索引合并
#分析:
组合索引能做到的事情,我们都可以用索引合并去解决,比如
create index ne on s1(name,email);#组合索引
我们完全可以单独为name和email创建索引
组合索引可以命中:
select * from s1 where name='egon' ;
select * from s1 where name='egon' and email='adf';
索引合并可以命中:
select * from s1 where name='egon' ;
select * from s1 where email='adf';
select * from s1 where name='egon' and email='adf';
乍一看好像索引合并更好了:可以命中更多的情况,但其实要分情况去看,如果是name='egon' and email='adf',
那么组合索引的效率要高于索引合并,如果是单条件查,那么还是用索引合并比较合理
六、使用索引应注意的规则
1、查看索引的使用情况:
show status like ‘Handler_read%’; handler_read_key:这个值越高越好,越高表示使用索引查询到的次数 handler_read_rnd_next:这个值越高,说明查询低效
2、使用索引时,有以下一些技巧和注意事项:
(1) 越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2) 简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3) 尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
(4) 索引不会包含有NULL值的列。
注:如果是同样的sql如果在之前能够使用到索引,那么现在使用不到索引,以下几种主要情况:
① 随着表的增长,where条件出来的数据太多,大于15%,使得索引失效(会导致CBO计算走索引花费大于走全表)
② 统计信息失效:需要重新搜集统计信息
③ 索引本身失效:需要重建索引
create index ix_name_email on s1(name,email,)
- 最左前缀匹配:必须按照从左到右的顺序匹配
select * from s1 where name='egon'; #可以
select * from s1 where name='egon' and email='asdf'; #可以
select * from s1 where email='alex@oldboy.com'; #不可以
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,
d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
#2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器
会帮你优化成索引可以识别的形式
#3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),
表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、
性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,
这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
#4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’
就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,
但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。
所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
3、常见索引失效的情况:使用explain查看索引是否生效
创建一个students表:
其中stud_id为主键!
DROP TABLE IF EXISTS `students`;
CREATE TABLE `students` (
`stud_id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`email` varchar(50) NOT NULL,
`phone` varchar(1) NOT NULL,
`create_date` date DEFAULT NULL,
PRIMARY KEY (`stud_id`)
)
INSERT INTO `learn_mybatis`.`students` (`stud_id`, `name`, `email`, `phone`, `create_date`) VALUES ('1', 'admin', 'student1@gmail.com', '18729902095', '1983-06-25');
INSERT INTO `learn_mybatis`.`students` (`stud_id`, `name`, `email`, `phone`, `create_date`) VALUES ('2', 'root', '74298110186@qq.com', '2', '1983-12-25');
INSERT INTO `learn_mybatis`.`students` (`stud_id`, `name`, `email`, `phone`, `create_date`) VALUES ('3', '110', '7429811086@qq.com', '3dsad', '2017-04-28');
① 在where后使用or,导致索引失效(尽量少用or)
简单实例演示:
创建两个普通索引,
CREATE INDEX index_name_email ON students(email);
CREATE INDEX index_name_phone ON students(phone);
使用下面查询sql,
# 使用了索引
EXPLAIN select * from students where stud_id='1' or phone='18729902095'
# 使用了索引
EXPLAIN select * from students where stud_id='1' or email='742981086@qq.com'
#--------------------------
# 没有使用索引
EXPLAIN select * from students where phone='18729902095' or email='742981086@qq.com'
# 没有使用索引
EXPLAIN select * from students where stud_id='1' or phone='222' or email='742981086@qq.com'
② 使用like ,like查询是以%开头
在1的基础上,还是使用 index_name_email 索引。 使用下面查询sql # 使用了index_name_email索引 EXPLAIN select * from students where email like '742981086@qq.com%' # 没有使用index_name_email索引,索引失效 EXPLAIN select * from students where email like '%742981086@qq.com' # 没有使用index_name_email索引,索引失效 EXPLAIN select * from students where email like '%742981086@qq.com%'
③ 复合索引遵守“最左前缀”原则,即在查询条件中使用了复合索引的第一个字段,索引才会被使用
删除1的基础创建的 index_name_email 和 index_name_phone 索引。
重新创建一个复合索引:
create index index_email_phone on students(email,phone);
使用下面查询sql
# 使用了 index_email_phone 索引
EXPLAIN select * from students where email='742981086@qq.com' and phone='18729902095'
# 使用了 index_email_phone 索引
EXPLAIN select * from students where phone='18729902095' and email='742981086@qq.com'
# 使用了 index_email_phone 索引
EXPLAIN select * from students where email='742981086@qq.com' and name='admin'
# 没有使用index_email_phone索引,复合索引失效
EXPLAIN select * from students where phone='18729902095' and name='admin'
④ 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
给name创建一个索引!
CREATE INDEX index_name ON students(name);
# 使用索引
EXPLAIN select * from students where name='110'
# 没有使用索引
EXPLAIN select * from students where name=110
⑤ 使用in导致索引失效
# 使用索引
EXPLAIN select * from students where name='admin'
# 没有使用索引
EXPLAIN SELECT * from students where name in ('admin')
⑥ DATE_FORMAT()格式化时间,格式化后的时间再去比较,可能会导致索引失效。
删除 students 上的创建的索引!重新在create_date创建一个索引!
CREATE INDEX index_create_date ON students(create_date);
# 使用索引
EXPLAIN SELECT * from students where create_date >= '2010-05-05'
# 没有使用索引
EXPLAIN SELECT * from students where DATE_FORMAT(create_date,'%Y-%m-%d') >= '2010-05-05'
⑦ 对于order by、group by 、 union、 distinc 中的字段出现在where条件中时,才会利用索引!
