

MySQL 之【约束】【数据库设计】
1.MySQL 约束:
1.约束的概念:
约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
MySQL中,常用的几种约束:
约束类型: 非空 主键 唯一 外键 默认值 关键字: NOT NULL
PRIMARY KEY UNIQUE FOREIGN KEY DEFAULT 1.非空约束(NOT NULL),听名字就能理解,被非空约束的列,在插入值时必须非空。
create table t1( id int(10) not null primary key );2.主键(PRIMARY KEY)是用于约束表中的一行,作为这一行的标识符,在一张表中通过主键就能准确定位到一行,因此主键十分重要。
注意: 主键这一行的数据不能重复且不能为空。
create table t2( id int(10) not null primary key );还有一种特殊的主键——复合主键。主键不仅可以是表中的一列,也可以由表中的两列或多列来共同标识
create table t3( id int(10) not null, name varchar(255) , primary key(id,name) );//alter删除主键约束
alter table t3 drop primary key;
//alter添加主键约束
alter table t3 add primary key(name, pwd);
//alter 修改列为主键
alter table t3 modify id int primary key;3.唯一约束(UNIQUE)比较简单,它规定一张表中指定的一列的值必须不能有重复值,即这一列每个值都是唯一的。
当INSERT语句新插入的数据和已有数据重复的时候,如果有UNIQUE约束,则INSERT失败.
create table t4( id int(10) not null, name varchar(255) , unique id_name(id,name) ); //添加唯一约束 alter table t4 add unique id_name(id,name); //删除唯一约束 alter table t4 drop index id_name;4,外键(FOREIGN KEY)既能确保数据完整性,也能表现表之间的关系。
注意: 一个表可以有多个外键,被外键约束的列,取值必须在它参考的列中有对应值。
-- 部门表 create table dept( dept_id int(30) not null auto_increment primary key, dept_name varchar(255) not null ); -- 员工表 create table emp( id int(10) not null auto_increment primary key, name varchar(50) not null, dept_id int(10) not null, constraint f_key foreign key (dept_id) references dept(dept_id) on delete cascade );注意:添加外键约束后,部门表中的数据如果被员工表中的数据使用了,则不可以删除.默认情况下.
注意:员工表中的外键字段只能添加部门表中存在的数据.
级联删除:删除主表的数据时,关联的从表数据也删除,
则需要在建立外键约束的后面增加on delete cascade或on delete set null, 前者是级联删除,
后者是将从表的关联列的值设置为null
警告:进公司工作时,最好问清楚,表的主外建设计是否需要添加约束?
5.默认值约束(DEFAULT)规定,当有DEFAULT约束的列,插入数据为空时该怎么办。
DEFAULT约束只会在使用INSERT语句时体现出来,INSERT语句中,如果被DEFAULT约束的位置没有值,那么这个位置将会被DEFAULT的值填充
create table t5( id int(10) not null primary key, name varchar(255) default '张三' );

2.数据库设计
1.概念
简单来说,数据库设计就是对需求进行分析、逻辑设计、物理设计以及维护和优化的过程。可以看到,数据库设计不仅仅体现在软件开发过程中,还体现在软件后期的维护上。(时间周期)
这里的软件需求分析与软件开发过程中的需求分析不太一样,数据库设计中的需求分析更侧重数据源(什么数据)、数据的属性以及数据和属性的特点。总结:
1.有效存储数据.
2.满足用户的多种需求
2.规则:
数据库设计三范式:
1.第一范式:确保每列保持原子性
2.第二范式:确保表中的每列都和主键相关
3.第三范式:确保表中每一列都和主键列直接相关,而不是间接相关.详情参考:数据库三范式-详解
3.数据库表关系
表与表之间一般存在三种关系,即一对一,一对多,多对多关系。
下面分别就三种关系讲解数据库相关设计的思路和思考过程;1.一对一关系
CREATE TABLE IF NOT EXISTS person( id INT PRIMARY KEY AUTO_INCREMENT, sname VARCHAR(10), sex CHAR(1), husband INT, wife INT ); INSERT INTO person VALUES(1,'小花','0',3,0); INSERT INTO person VALUES(2,'小明','1',0,4); INSERT INTO person VALUES(3,'张三','1',0,1); INSERT INTO person VALUES(4,'小丽','0',2,0); INSERT INTO person VALUES(5,'王五','1',0,0);sql代码对应的person表:
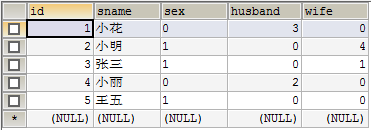
从表中可以看出,小花和张三是夫妻,小明和小丽是夫妻。
通常为了查询方便,需要两个表,但实际项目中为了省空间,通常只建一个表.
2、一对多关系
例如:一个人可以拥有多辆汽车,要求查询某个人拥有的所有车辆。
分析:这种情况其实也可以采用 一张表,但因为一个人可以拥有多辆汽车,如果采用一张表,会造成冗余信息过多。好的设计方式是,人和车辆分别单独建表,那么如何将两个表关联呢?有个巧妙的方法,在车辆的表中加个外键字段(人的编号)即可。
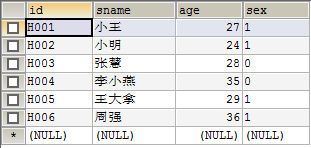
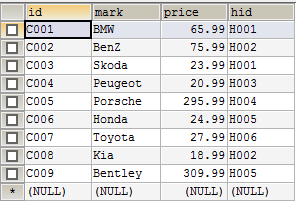
* (思路小结:’建两个表,一’方不动,’多’方添加一个外键字段)*//建立人员表 CREATE TABLE people( id VARCHAR(12) PRIMARY KEY, sname VARCHAR(12), age INT, sex CHAR(1) ); INSERT INTO people VALUES('H001','小王',27,'1'); INSERT INTO people VALUES('H002','小明',24,'1'); INSERT INTO people VALUES('H003','张慧',28,'0'); INSERT INTO people VALUES('H004','李小燕',35,'0'); INSERT INTO people VALUES('H005','王大拿',29,'1'); INSERT INTO people VALUES('H006','周强',36,'1'); //建立车辆信息表 CREATE TABLE car( id VARCHAR(12) PRIMARY KEY, mark VARCHAR(24), price NUMERIC(6,2), hid VARCHAR(12), CONSTRAINT fk_people FOREIGN KEY(hid) REFERENCES human(id) ); INSERT INTO car VALUES('C001','BMW',65.99,'H001'); INSERT INTO car VALUES('C002','BenZ',75.99,'H002'); INSERT INTO car VALUES('C003','Skoda',23.99,'H001'); INSERT INTO car VALUES('C004','Peugeot',20.99,'H003'); INSERT INTO car VALUES('C005','Porsche',295.99,'H004'); INSERT INTO car VALUES('C006','Honda',24.99,'H005'); INSERT INTO car VALUES('C007','Toyota',27.99,'H006'); INSERT INTO car VALUES('C008','Kia',18.99,'H002'); INSERT INTO car VALUES('C009','Bentley',309.99,'H005');sql代码对应的人员表:
sql代码对应的车辆信息表:
3.多对多关系
例如:学生选课,一个学生可以选修多门课程,每门课程可供多个学生选择。
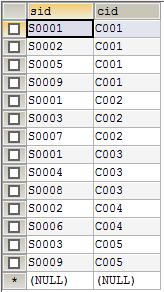
分析:这种方式可以按照类似一对多方式建表,但冗余信息太多,好的方式是实体和关系分离并单独建表,实体表为学生表和课程表,关系表为选修表,其中关系表采用联合主键的方式(由学生表主键和课程表主键组成)建表。//建立学生表 CREATE TABLE student( id VARCHAR(10) PRIMARY KEY, sname VARCHAR(12), age INT, sex CHAR(1), class VARCHAR(6) ); INSERT INTO student VALUES('S0001','王军',20,1,'c101'); INSERT INTO student VALUES('S0002','张宇',21,1,'c101'); INSERT INTO student VALUES('S0003','刘飞',22,1,'c102'); INSERT INTO student VALUES('S0004','赵燕',18,0,'c103'); INSERT INTO student VALUES('S0005','曾婷',19,0,'c103'); INSERT INTO student VALUES('S0006','周慧',21,0,'c104'); INSERT INTO student VALUES('S0007','小红',23,0,'c104'); INSERT INTO student VALUES('S0008','杨晓',18,0,'c104'); INSERT INTO student VALUES('S0009','李杰',20,1,'c105'); INSERT INTO student VALUES('S0010','张良',22,1,'c105'); //建立课程表 CREATE TABLE course( id VARCHAR(10) PRIMARY KEY, sname VARCHAR(12), credit NUMERIC(2,1), teacher VARCHAR(12) ); INSERT INTO course VALUES('C001','Java',3.5,'李老师'); INSERT INTO course VALUES('C002','高等数学',5.0,'赵老师'); INSERT INTO course VALUES('C003','JavaScript',3.5,'王老师'); INSERT INTO course VALUES('C004','离散数学',3.5,'卜老师'); INSERT INTO course VALUES('C005','数据库',3.5,'廖老师'); INSERT INTO course VALUES('C006','操作系统',3.5,'张老师'); //建立选修表 CREATE TABLE sc( sid VARCHAR(10), cid VARCHAR(10) ); ALTER TABLE sc ADD CONSTRAINT pk_sc PRIMARY KEY(sid,cid); ALTER TABLE sc ADD CONSTRAINT fk_student FOREIGN KEY(sid) REFERENCES student(id); ALTER TABLE sc ADD CONSTRAINT fk_course FOREIGN KEY(cid) REFERENCES course(id); INSERT INTO sc VALUES('S0001','C001'); INSERT INTO sc VALUES('S0001','C002'); INSERT INTO sc VALUES('S0001','C003'); INSERT INTO sc VALUES('S0002','C001'); INSERT INTO sc VALUES('S0002','C004'); INSERT INTO sc VALUES('S0003','C002'); INSERT INTO sc VALUES('S0003','C005'); INSERT INTO sc VALUES('S0004','C003'); INSERT INTO sc VALUES('S0005','C001'); INSERT INTO sc VALUES('S0006','C004'); INSERT INTO sc VALUES('S0007','C002'); INSERT INTO sc VALUES('S0008','C003'); INSERT INTO sc VALUES('S0009','C001'); INSERT INTO sc VALUES('S0009','C005');sql代码对应的学生表:
sql代码对应的课程表:
sql代码对应的选课表:
4.分表
在数据库表使用过程中,为了减小数据库服务器的负担、缩短查询时间,常常会考虑做分表设计。
分表分两种,一种是纵向分表(将本来可以在同一个表的内容,人为划分存储在为多个不同结构的表)和横向分表(把大的表结构,横向切割为同样结构的不同表)。
其中,纵向分表常见的方式有根据活跃度分表、根据重要性分表等。其主要解决问题如下:
表与表之间资源争用问题;
锁争用机率小;
实现核心与非核心的分级存储,如UDB登陆库拆分成一级二级三级库;
解决了数据库同步压力问题。
横向分表是指根据某些特定的规则来划分大数据量表,如根据时间分表。其主要解决问题如下:
单表过大造成的性能问题;
单表过大造成的单服务器空间问题。

