golang 加载并运行tensorflow模型
-
流程
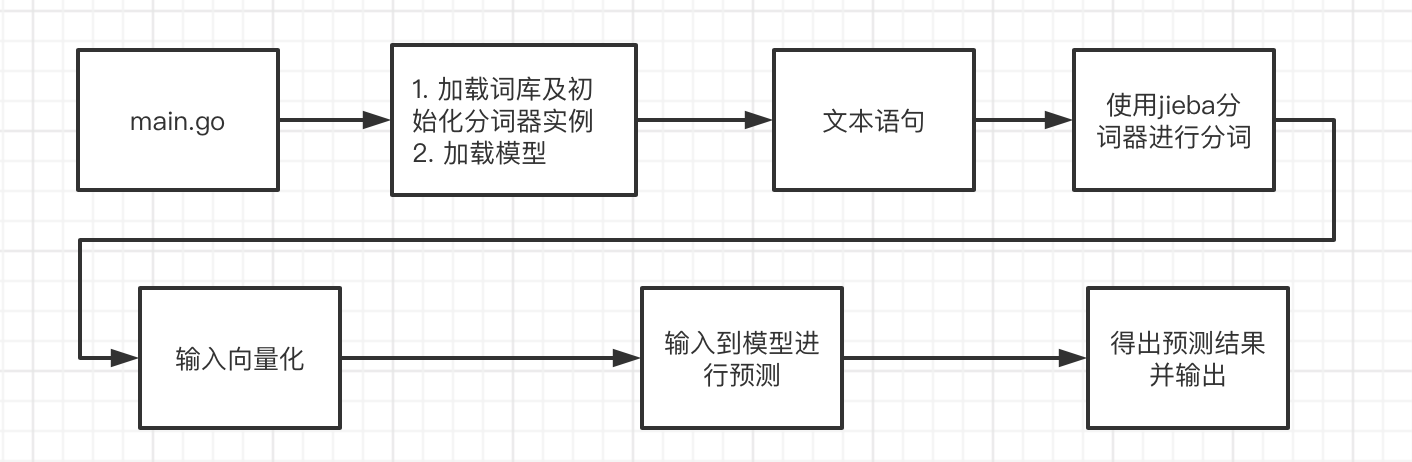
-
环境搭建
1. 参考链接 官方文档:
https://tensorflow.google.cn/install/lang_go
2. 注意配置其环境变量
3. 拉取golang tensorflow api代码包```shell go get github.com/tensorflow/tensorflow/tensorflow/go ``` 1. 在安装过程中遇到问题及解决 1. 问题: ```shell running into this error for TF v2.3.1. is there a way to generate this package? └─ $ ▶ go test github.com/tensorflow/tensorflow/tensorflow/go saved_model.go:25:2: cannot find package "github.com/tensorflow/tensorflow/tensorflow/go/core/protobuf/for_core_protos_go_proto" in any of: /home/sdeoras/go/src/github.com/tensorflow/tensorflow/tensorflow/go/vendor/github.com/tensorflow/tensorflow/tensorflow/go/core/protobuf/for_core_protos_go_proto (vendor tree) /usr/local/go/src/github.com/tensorflow/tensorflow/tensorflow/go/core/protobuf/for_core_protos_go_proto (from $GOROOT) /home/sdeoras/go/src/github.com/tensorflow/tensorflow/tensorflow/go/core/protobuf/for_core_protos_go_proto (from $GOPATH) ``` 2. 解决方案: 1. 在github上找到的解决方案:将加载的tensorflow 的go api包版本回退到1.15,将2.2步骤中配置的C的环境也回退到1.15版本 ```shell Reverted to TF v1.15.0 and things are working fine: downloaded c-lib from https://storage.googleapis.com/tensorflow/libtensorflow/libtensorflow-cpu-linux-x86_64-1.15.0.tar.gz ``` 2. 偶然间发现 tensorflow/tensorflow/go/genop/generate.sh 位置有个脚本,打开文件查看其内容,里面用到了protobuf生成代码的命令,其实就是将tensorflow项目中的几个地方的 .proto 文件转为需要的go文件,然后再看 3.1.1中的问题,就是有一些文件没找到,刚好可以对应上。 执行这个脚本的过程中可能会遇到一些错误(需要安装protobuf的环境,可以把报的错误直接google或者百度即可),将生成代码后的文件夹复制到3.1.1中报错的路径下即可解决该问题 -
示例
package main /** * User: zhuchenglin */ import ( "bufio" "fmt" "github.com/wangbin/jiebago" "io" "os" "strings" tf "github.com/tensorflow/tensorflow/tensorflow/go" ) var rootPath ,_= os.Getwd() var seg jiebago.Segmenter func main() { // 将句子分词 dictPath := rootPath + "/models/词库.txt" err := seg.LoadDictionary(dictPath) if err != nil { fmt.Println(err.Error(), "========") return } myDictPath := rootPath + "/models/不分词的词库.txt" err = seg.LoadUserDictionary(myDictPath) if err != nil { fmt.Println(err.Error(), "========") return } content := "文字信息" content = strings.Trim(content, " \n \r ") ch := seg.Cut(content, true) words := make([]string, 0) for word:= range ch{ words = append(words, word) } // fmt.Println(words) // 加载词库 //对于python中有些数据处理的库不存在,暂时采取了使用python按照对应的规则将模型词库结果输出到txt文件中,然后用go通过读取文件的方式读取 数据格式化的规则 filePath := rootPath + "/models/模型词库.txt" startLine := 1 allWords, err := ReadRecvFromTxt(filePath, startLine) if err != nil { fmt.Println(err.Error(), "===========") return } // 格式化输入数据 // 这个需要跟模型定义者去对格式化数据输入的过程,要跟python数据格式化数据过程保持一致 // 定义输入矩阵的最大长度 maxLength := x inputArr := make([]float32, len(words)) for k, word := range words { index, ok := allWords[word] // fmt.Println(word, ok) if ok { inputArr[k] = float32(index.(int)) } else { inputArr[k] = 0 } } inputData := [1][]float32{} inputData[0] = inputArr // 输入数据矩阵 fmt.Println(inputData) // 加载模型 modelPath := rootPath + "model/path/dir" // 如果在python导出模型的文件时候没有指定tag,默认就是serve tags := []string{"serve"} model, err := tf.LoadSavedModel(modelPath, tags, nil) // 载入模型 if err != nil { fmt.Println(err.Error(),"-------------") return } // 获取模型里面的operations //for _, op := range model.Graph.Operations() { //log.Printf("Op name: %v, on device: %v", op.Name(), op.Device()) //log.Printf("opInputNum: %d, opOutputNum: %d, opType: %v, op name:%v, device: %v",op.NumInputs(),op.NumOutputs(),op.Type(), op.Name(), op.Device()) //log.Printf("Op name: %v", op.Name()) //} // 将数据输入到模型并得到结果 tensor, err := tf.NewTensor(inputData) if err != nil{ fmt.Println(err.Error(),"==========---------=====") return } // 当python 定义模型的时候,没有指定对应输入输出操作层名称时,下面的是默认的名称 result, err := model.Session.Run( map[tf.Output]*tf.Tensor{ model.Graph.Operation("serving_default_embedding_input").Output(0): tensor, }, []tf.Output{ model.Graph.Operation("StatefulPartitionedCall").Output(0), }, nil, ) if err != nil { fmt.Println(err.Error(),"=======================") return } // 最后输出的结果跟算法模型的定义有关 fmt.Println(result) } // 从文件加载词库 可以根据文件的实际格式进行调整 func ReadWordsFromTxt(filePath string) (map[string] interface{}, error) { f, err := os.Open(filePath) if err != nil { fmt.Println(err.Error()) return nil, err } defer f.Close() allWords := make(map[string] interface{}) rd := bufio.NewReader(f) for { word , err := rd.ReadString('\n') if err != nil || io.EOF == err { break } word = strings.Trim(word, " \r\n ") allWords[word] = true } return allWords , nil } // 从词库的txt文件中获取词库 这个可以根据文件的实际格式进行调整 func ReadRecvFromTxt(filePath string, startLine int) (map[string]interface{}, error) { f, err := os.Open(filePath) if err != nil { fmt.Println(err.Error()) return nil, err } defer f.Close() allWords := make(map[string]interface{}) rd := bufio.NewReader(f) lineNum := 1 for { line , err := rd.ReadString('\n') if err != nil || io.EOF == err { break } if lineNum >= startLine { wordArr := strings.Split(line, " ") word := strings.Trim(wordArr[0]," \n ") allWords[word] = lineNum } lineNum ++ } return allWords , nil } -
优化
-
问题:在运行过程中cpu占用率过高(其过程是大量运算的过程)
-
解决(三方面):
-
更新所用tensorflow go api 及 tensorflow C库 为最新版本,其C库含有一些新的指令集(AVX AVX2、FMA等),可以加速运算
-
借助 go.uber.org/automaxprocs 库 在docker+k8s的环境下优化 golang 的 runtime.gomaxprocs 参数,防止并行的任务过多,会造成频繁系统调用创建大量系统线程,大概原理如下:
在这个里面 cat /proc/self/mountinfo 可以查找到 资源的挂载信息 cd /sys/fs/cgroup/cpu/ cfs.cpu_period_us 文件记录了调度周期,单位是 us;默认值一般是 100'000,即 100 ms cfs.cpu_quota_us 记录了每个调度周期进程允许使用 cpu 的量,单位也是 us。 值为 -1 表示无限制;对于 4C 的容器,这个值一般是 400'000 -
将模型运算任务放在GPU上去运行
- 需要安装gpu驱动 (https://tensorflow.google.cn/install/gpu)
- 需要更换 tensorflow C库 gpu版本
-
-
注:如需转载请注明出处:https://www.cnblogs.com/zhuchenglin/p/15089360.html

