源码阅读笔记 BiLSTM+CRF做NER任务(一)
源码地址:https://github.com/ZhixiuYe/NER-pytorch
本篇主要介绍NER任务、Conll 2003(English)数据集及数据集相关统计
一、NER任务
NER(命名实体识别)是一项基础任务,通常是做知识图谱等任务的必要过程。一般是指给定一段文本,识别出里面的实体,实体主要包括人名、地名、机构名、时间、数量等等。如:
![]()
二、数据集
1.数据集说明
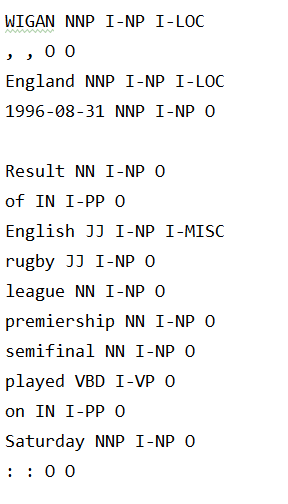
使用的是CoNLL 2003(English),数据的每行为一个单词,每个句子单位由空行隔开。
每行的第一项是单词,第二项是词性标记,第三项是句法块标记,第四项是命名实体标签。示例如下:
实体类型包含四类:人名(PER)、地名(LOC)、组织名(ORG)、其他实体名(MISC)
数据由三个文件组成:一个训练文件和两个测试文件testa和testb。testa作为测试集用于确定最佳的参数。testb作为测试集用于最终评估。
注意:命名实体标签的格式为I-type,这意味着单词位于类型为的短语中。只有当同一类型的两个短语紧跟在一起时,第二个短语的第一个单词才会有标记B-type来表示它开始一个新短语。
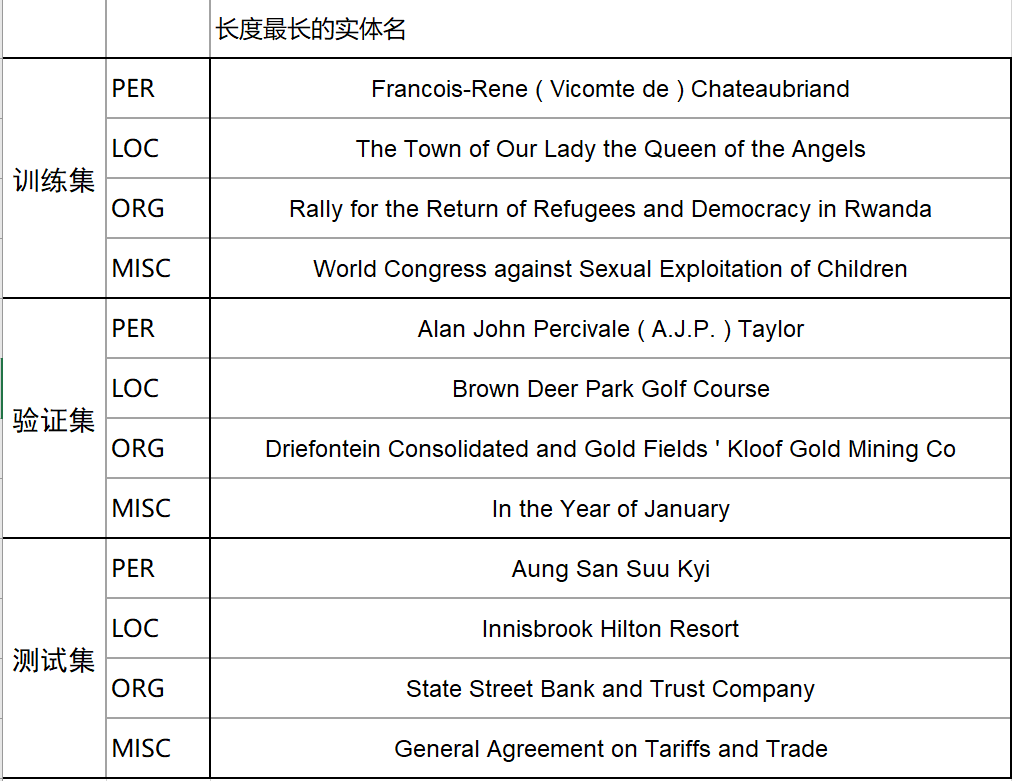
2.数据集相关统计
1)实体名数量统计

2)实体名长度统计

3)实体名长度最长的实体名统计