
目标检测《rv1109 部署yolov5模型(自己训练的模型)汇总》
3. rv1109平台部署yolov5环境,官方onnx模型转换rknn模型验证
以上文章是从0到1,一点点记录部署全部过程,包括出现的错误以及解决过程。
本文是做个总结,删除问题出现点,直接把解决方案给出。顺序总结出部署过程,因为是后期总结,可能会导致哪里遗落,具体可以查看对应上面对应文章。
环境以及相关软件版本:yolov5(v5.0)、Ubuntu18.04、rknn-toolkit 1.7.3、rv1109
一.yolov5环境安装(window)
1 conda安装
1.1 Anaconda 安装包:
在浏览器中打开 https://www.anaconda.com/products/individual 下载适合你的操作系统的 Anaconda 安装包(Python 版本根据需要选择)。建议选择 Python 3.x 版本,因为 Python 2.x 已经不再被支持。
1.2 环境变量配置:
安装完成后,配置一下系统环境变量,在PATH中新建(路径根据自己安装的路径配置),如下图:
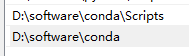
1.3 重启电脑
1.4 验证:
终端里面输入conda --version,如果可以显示出版本号,证明安装成功。
2.yolov5(v5.0)环境安装
2.1创建虚拟环境:
win+R输入cmd,打开终端,最好是在比如D盘新建个yolo的文件夹,切到这个文件夹中进行后续操作。(python根据自己的版本更换)
conda create -n yolo python=3.10
激活当创建的环境:
conda activate yolo
报错:
我这边激活失败提示:IMPORTANT: You may need to close and restart your shell after running 'conda init'。
解决:
我用的是命令提示符,也就是cmd.exe。(如果使用bash、powershell就自己替换)
以管理员身份运行cmd.exe
conda init cmd.exe
再次激活:

2.2 安装pytorch:
需要在上一个激活的环境下运行:
conda install pytorch torchvision cudatoolkit=11.3 -c pytorch
2.3 下载yolov5 (V5.0)的源码
yolov5不同版本训练得到的pt模型会决定rknn模型转换的成功与否。我之前使用yolov5 (v7.0)训练出来的pt转换rknn后,在板卡运行就一直报段错误,但是用yolov5(V5.0)就可以正常运行。
yolov5的节点id为:c5360f6e7009eb4d05f14d1cc9dae0963e949213
yolov5 git地址:https://github.com/ultralytics/yolov5
在右上角搜索这个commit id并进入“In this repository”,如图所示:
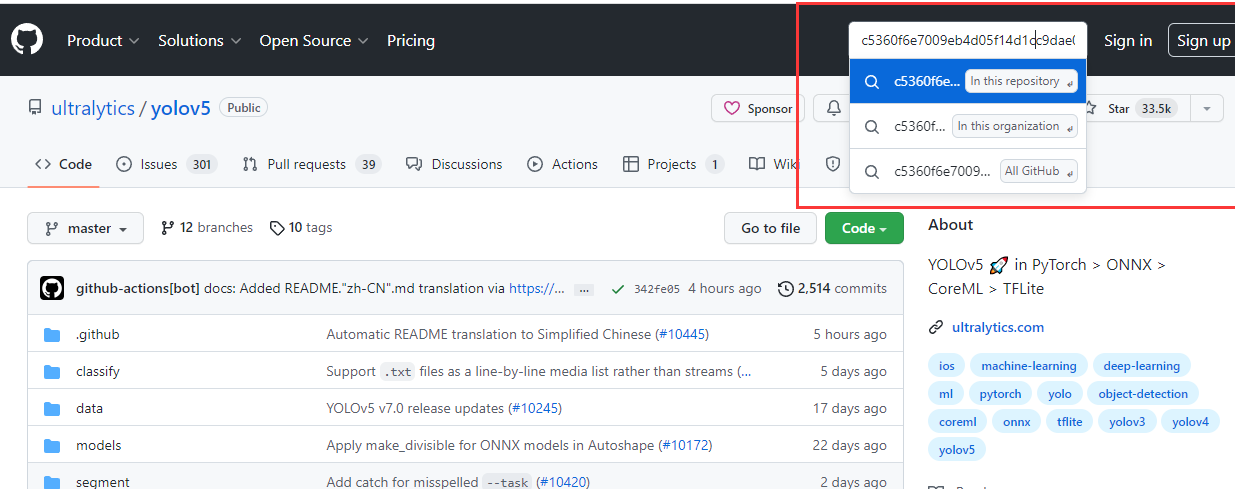
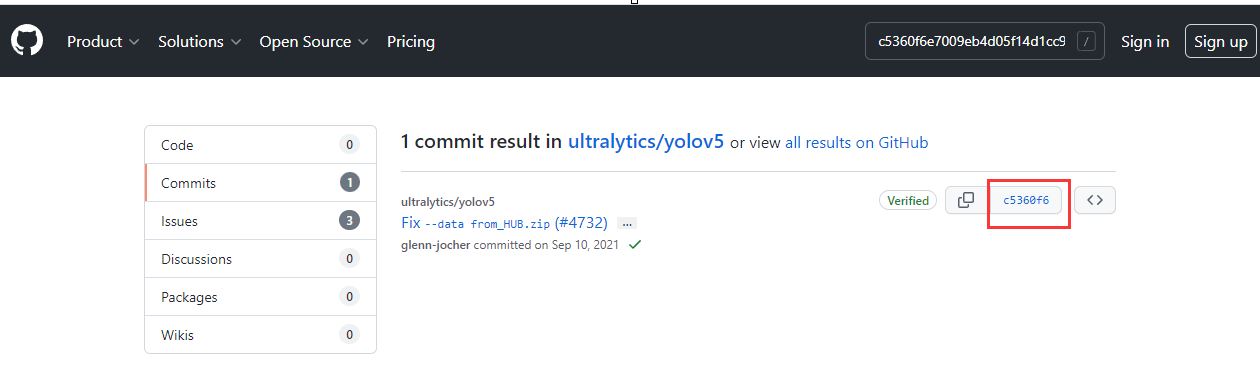
进入commits,点击右边的commit id,再次进入后点击Browse files,如下三图所示:
commit id:
Browse files:
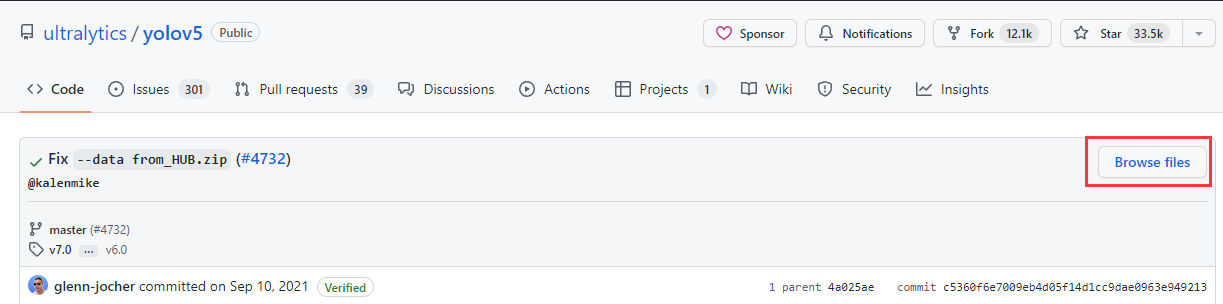
对应版本的源码:
以上,yolov5的源码下载完成。
2.4 下载yolov5(v5.0)预训练模型yolov5s.pt
由于yolov5 (v5.0)源码中未包含预训练模型,因此需要自己下载
下载地址:https://github.com/ultralytics/yolov5/releases
找到V5.0,然后点击 v5.0 release

在界面最下面下载yolov5s.pt

二、yolov5训练自己的数据集
1. labelimg安装及使用
参考:https://blog.csdn.net/qq_45828295/article/details/127227040
框好后,会生成对应的txt文件。
需要注意一下,在生成的classes.txt中,一开始是有默认的一些类目(下面有说明怎么删除这些默认类别,建议删除)
在label目录下面的data/predefined_classes.txt
删除默认的类别,添加自己的类目就好了。
需要注意一个报错:
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}' AssertionError: Label class 15 exceeds nc=1 in D:\software\yolo\yolov5\data\mask_data.yaml. Possible class labels are 0-0
这是因为一开始标注的时候,classes.txt里面有默认类目。但是在标注完成后,把里面的默认类目删掉,导致下标不对应。
其实就是要标注对应ID就行了。标注起始是0。如果不删除就不会出现这个问题。如果删掉就要手动改一下全部非classes.txt。
原本classex.txt里面的内容,我把file以上的全部删除。
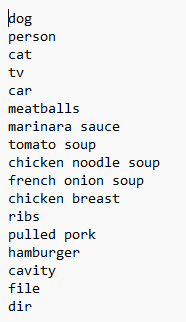
问题解决:
把生成的txt中修改如下,修改为自己对应的ID
其实就是把自己标注的: 15 0.450777 0.244275 0.088083 0.351145 修改成 0 0.450777 0.244275 0.088083 0.351145
2.模型训练
在yolov5的目录下创建如下文件
yolov5
└─ score
├─ images
│ ├─ test # 下面放测试集图片
│ ├─ train # 下面放训练集图片
│ └─ val # 下面放验证集图片
└─ labels
├─ test # 下面放测试集标签
├─ train # 下面放训练集标签
├─ val # 下面放验证集标签
将label中训练的标签以及图片放进去。我个人是test、train、val都放一样的(如果放一样会导致后续结果很差,需要放不一样的数据)
在机器学习中,通常将数据集划分为训练集(training set)、验证集(validation set)和测试集(test set),以评估模型的性能和泛化能力。
训练集用于训练模型,验证集用于调整模型的超参数和防止过拟合,测试集用于评估模型在未见过的数据上的性能和泛化能力。具体来说:
-
训练集:用于训练模型的数据集。通常,训练集应该包含足够的数据,以覆盖数据集的各种情况和变化,并且应该是代表性的、随机的和独立的。训练集的目的是让模型学习到数据的本质特征,并尽可能减少模型在训练集上的误差。
-
验证集:用于调整模型的超参数和防止过拟合的数据集。通常,验证集应该是独立的、随机的和代表性的,应该与训练集和测试集不同。验证集的目的是评估模型在未见过的数据上的性能,并根据性能指标调整模型的超参数和防止过拟合。
-
测试集:用于评估模型在未见过的数据上的性能和泛化能力的数据集。通常,测试集应该是独立的、随机的和代表性的,应该与训练集和验证集不同。测试集的目的是评估模型在未见过的数据上的性能和泛化能力,并验证模型的泛化能力是否足够好。
为了确保模型的性能评估具有客观性和准确性,训练集、验证集和测试集应该是独立的、随机的和代表性的,并且应该彼此不同。通常,建议将数据集划分为训练集、验证集和测试集,并采用交叉验证等方法进行性能评估,以提高模型的性能和泛化能力。
修改一下配置文件,我们需要在data目录下创建一个mask_data.yaml的文件:
train: D:/software/yolo/yolov5/score/images/train val: D:/software/yolo/yolov5/score/images/val # Classes nc: 2 # number of classes names: ['file', 'dir'] # class names
这个就根据自己的yolov5的路径,类目个数以及类别名称修改一下就行了,就是个配置文件。
在models下建立一个mask_yolov5s.yaml的模型配置文件,内容如下(就是把yolov5s.yaml文件复制一下,然后修改一下):
只要修改一下这个就行了。改成自己类目的个数
nc: 2 # number of classes
修改utils/loss.py文件中的两处内容:
for i in range(self.nl): anchors = self.anchors[i]
修改为:
for i in range(self.nl): anchors, shape = self.anchors[i], p[i].shape
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid
修改为:
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
开始模型训练:
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu
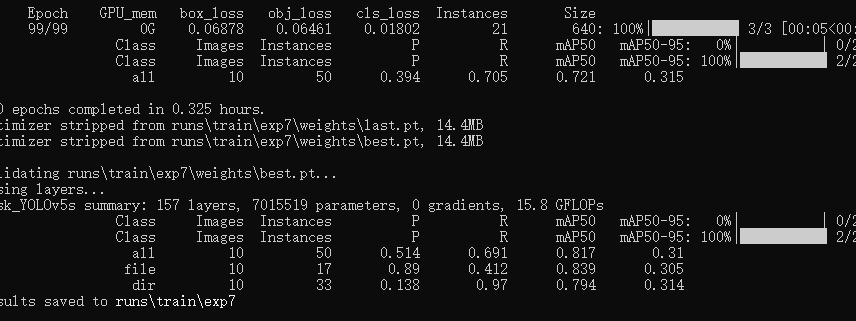
训练完后在runs/train/exp7生成对应结果。主要关注一下best.pt,这就是我们训练出来要使用的模型。
验证一下:
python detect.py --weights runs/train/exp7/weights/best.pt --source score/images/test

发现会对同一个目标反复框,查询了一下,增加 NMS 阈值可以减少重叠框的数量,从而提高检测的准确率。默认是0.25。
python detect.py --weights runs/train/exp7/weights/best.pt --source score/images/test --conf 0.8
这样就好多了。不过很多还是不能准确识别出来,应该还是数据训练的不够。可以增大训练样本。
三、运行rv1109 demo
1.Ubuntu安装rknn toolkit
Ubuntu版本是18.04,最好是这个版本,其他版本安静环境的时候会出现版本不匹配问题。
rv1109板卡rknn模型转换需要使能预编译,而pc环境不支持预编译。所以需要在ubuntu上安装toolkit将onxx转换成rknn。
SDK中的rknn toolkit版本比较旧,如果需要最新的,https://github.com/rockchip-linux/rknn-toolkit下载。各种版本环境安装可能有一点不一样,具体查看Rockchip_Quick_Start_RKNN_Toolkit_V1.7.3_CN.pdf手册。
1.1 下载安装anaconda:
wget https://mirrors.bfsu.edu.cn/anaconda/archive/Anaconda3-2022.05-Linux-x86_64.sh bash Anaconda3-2022.05-Linux-x86_64.sh
安装过程中,看到>>>就按回车,看到more就按空格,yes|no就输入yes。等待安装完成。
1.2 创建并激活虚拟环境:
conda create -n rknn python=3.6.8 conda activate rknn
可能会出现需要conda init bash的情况,然后重启一下就可以激活了。
1.3 安装python依赖
pip install tensorflow==1.14.0 pip install torch==1.6.0+cpu torchvision==0.7.0+cpu -f https://download.pytorch.org/whl/torch_stable.html --user pip install mxnet==1.5.0 pip install -i https://pypi.douban.com/simple/ pip install opencv-python==4.3.0.38 pip install gluoncv
1.4 下载rknn toolkit package
git地址:https://github.com/rockchip-linux/rknn-toolkit/releases
![]()
安装对应的轮子rknn_toolkit-1.7.3-cp36-cp36m-linux_x86_64.whl
pip install rknn_toolkit-1.7.3-cp36-cp36m-linux_x86_64.whl
验证是否安装成功:

没有报错就算成功。
2.利用官方的rknn模型在rv1109上运行
在SDK下rv1126_rv1109\external\rknpu\rknn\rknn_api\examples\rknn_yolov5_demo有对应的demo
在这个demo中已经有转换好的rknn,可以根据readme配置一下build.sh中的编译器路径就行了。
修改build.sh
GCC_COMPILER=略rv1126_rv1109/prebuilts/gcc/linux-x86/arm/gcc-arm-8.3-2019.03-x86_64-arm-linux-gnueabihf/bin/arm-linux-gnueabihf
根据自己交叉编译器路径配置一下。
./build.sh
执行成功,在当前目录生成一个install目录。
把目录通过adb放到板卡的/userdata下,并修改执行权限chmod 777 -R 文件夹。
./rknn_yolov5_demo model/rv1109_rv1126/yolov5s_relu_rv1109_rv1126_out_opt.rknn model/test1.bmp
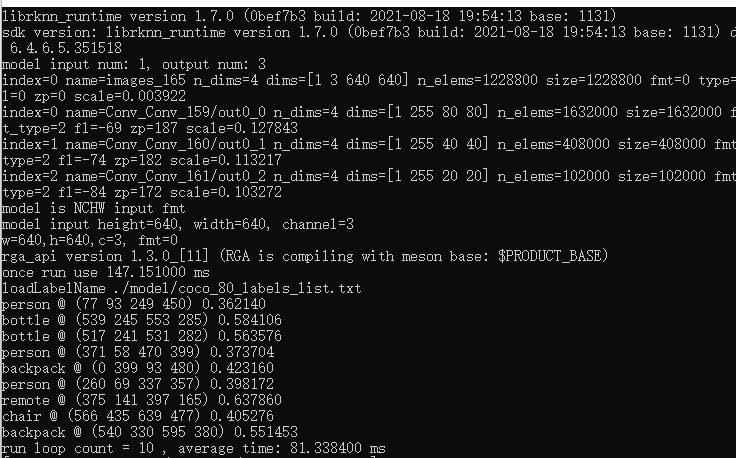
执行成功会在当前目录生成一个out.bmp。

以上是运行官方的rknn模型,在rv1109上运行。接下来运行用官方提供的onnx->rknn,看是否能成功。
3. 官方demo onnx -> rknn
这边先用官方的准备的onnx模型转换成rknn模型,然后在rv1109平台上运行。
通过https://github.com/rockchip-linux/rknn-toolkit下载最新的demo,因为我需要用的是yolov5,而SDK里面是yolov3。
rknn-toolkit-master\rknn-toolkit-master\examples\onnx\yolov5目录下修改test.py
默认的平台是rk1808,修改target_platform为rv1109和rv1126,如果只是写rv1109应该也可以。
rknn.config(reorder_channel='0 1 2', mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], optimization_level=3, target_platform =['rv1109'], output_optimize=1, quantize_input_node=QUANTIZE_ON)
修改rknn.init_runtime函数,设置平台为rv1109,device_id可以不填,那个是PC模拟挂载多个板卡才需要指定。
ret = rknn.init_runtime('rv1109')
修改rknn-toolkit-master/examples/onnx/yolov5下的test.py,打开预编译
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
修改成:
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET, pre_compile=True)
然后执行(需要在上面虚拟环境rknn中执行,因为我们环境是安装在这里面的)
python test.py
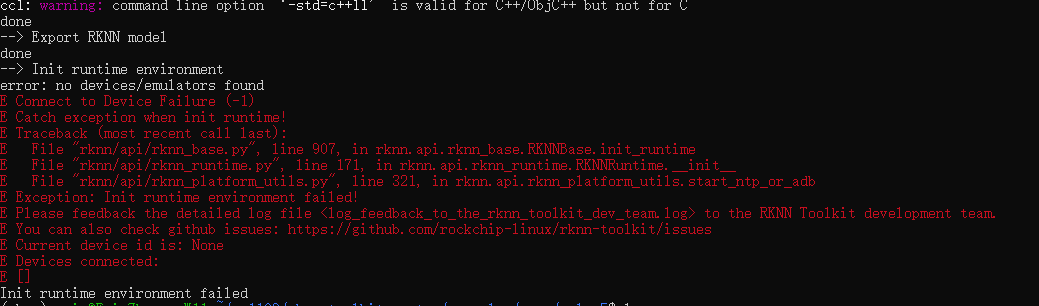
看到Export RKNN model就表示导出成功,后续报错是因为不支持在PC上模拟运行。不管它,我们是在rv1109上运行的。
把生成的rknn模型放到rv1109上,执行:
./rknn_yolov5_demo yolov5s.rknn bus.bmp
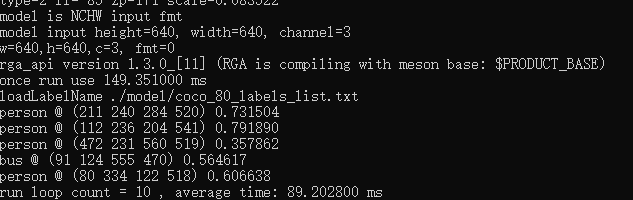

这样就没问题,表示环境都正常。
四、rv1109部署自己训练的数据集模型
1. 把best.pt转成onnx(windos)
这边的best.pt,是第二大点生成的best.pt。也就是我们自己训练的模型。
注意:在训练时不要修改yolo.py的这段代码,训练完成后使用export.py进行模型导出转换时一定要进行修改,不然会导致后面的rknn模型转换失败!
并且如果export.py后,再次用train.py训练模型,要修改回来。不然训练模型会报错。
models/yolo.py文件的后处理部分,将class Detect(nn.Module) 类的子函数forward由
def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() if not self.training: # inference if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic: self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i) y = x[i].sigmoid() if self.inplace: y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953 xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh y = torch.cat((xy, wh, y[..., 4:]), -1) z.append(y.view(bs, -1, self.no)) return x if self.training else (torch.cat(z, 1), x)
修改为:
def forward(self, x): z = [] # inference output for i in range(self.nl): x[i] = self.m[i](x[i]) # conv return x
修改export.py,把opset_version的值改为12:

执行:
python export.py --weights best.pt --img 640 --batch 1 --include onnx
就看可以看到生成best.onnx。
2. best.onnx转换成best.rknn
将生成的best.onnx放到toolkit的examples/onnx/yolov5目录下
修改test.py:

rknn.config(reorder_channel='0 1 2', mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], optimization_level=3, target_platform =['rv1109'], output_optimize=1, quantize_input_node=QUANTIZE_ON)
把target_platform 修改为自己对应的平台。
将(备注:这边是因为我用的是RV1109,驱动只支持预编译,使能了预编译后,不能在模拟器上运行。其他平台或者设备根据自身看是否需要使能预编译)
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
修改为:
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET, pre_compile=True)
修改dataset.txt,修改为自己要检测图片的名字。
执行:
python test.py
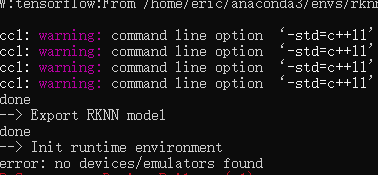
3. 部署在rv1109
在rv1109的SDK中rv1126_rv1109\external\rknpu\rknn\rknn_api\examples\rknn_yolov5_demo
修改include文件中的头文件postprocess.h
#define OBJ_CLASS_NUM 2 #这里的数字修改为数据集的类的个数
修改model目录下的coco_80_labels_list.txt文件, 改为自己的类并保存
file
dir
修改build.sh
GCC_COMPILER=自己设备的交叉编译器的路径/bin/arm-linux-gnueabihf
执行
./build.sh
执行成功会在当前目录生成install。
将install生成的文件放到设备中,然后将best.rknn以及需要检测图片放在一个目录中,执行
./rknn_yolov5_demo best.rknn test.bmp
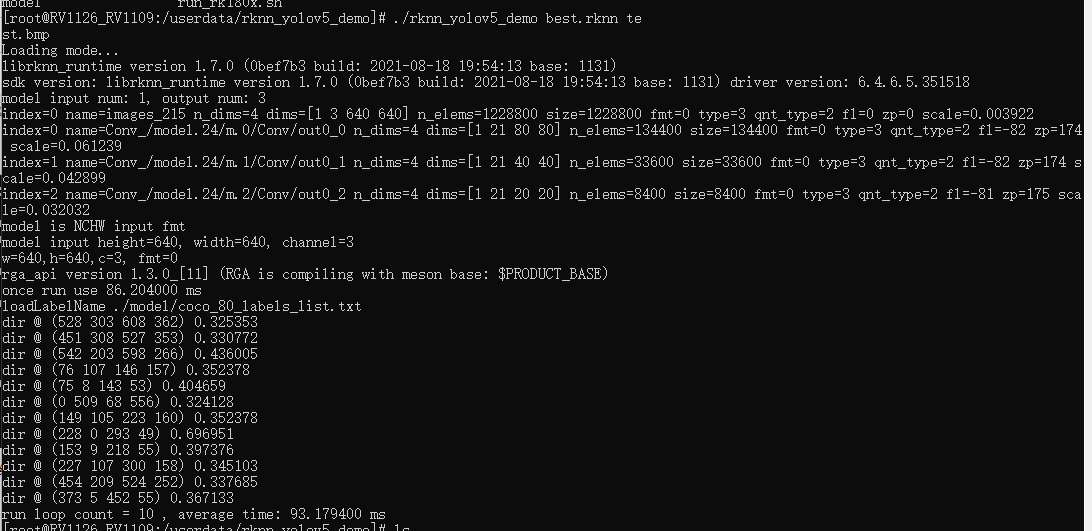

这样就成功了。可以在rv1109上面执行自己训练的数据集。

