
目标检测《二、 yolov5训练自己的数据集》
3. rv1109平台部署yolov5环境,官方onnx模型转换rknn模型验证
以上文章是从0到1,一点点记录部署全部过程,包括出现的错误以及解决过程。
第五篇是汇总前4篇,做一个归纳总理,顺序总结出部署过程,因为是后期总结,可能会导致哪里遗落,具体可以查看对应上面对应文章。
-------------------------------------------------------------------------------------------------------------------------------------------------------------
1.labelimg安装以及使用
安装和使用参考:https://blog.csdn.net/qq_45828295/article/details/127227040
框好后,会生成对应的txt文件。
需要注意一下,在生成的classes.txt中,一开始是有默认的一些类目(下面有说明怎么删除这些默认类别,建议删除)
这边的类目和其他图片的txt中比如15 0.104412 0.099678 0.114706 0.154341最前面的标号,就是对应的类目。因为只有file和dir是我自己标注的,其他都是默认的。如果把其他删除,在训练的时候会报错。
报错:
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}' AssertionError: Label class 15 exceeds nc=1 in D:\software\yolo\yolov5\data\mask_data.yaml. Possible class labels are 0-0
问题解决:
参考:https://www.jb51.cc/faq/2848565.html 其实就是把自己标注的: 15 0.450777 0.244275 0.088083 0.351145 修改成 0 0.450777 0.244275 0.088083 0.351145 修改最前面的ID,根据自己的类多少。
其实就是要标注对应ID对应就行了。标注起始是0。上面这个报错是因为我把其他不是我设置的类别全删掉导致的。如果不删除就不会出现这个问题。如果删掉就要手动改一下全部非classes.txt,比较麻烦。应该label哪里可以设置导入classes.txt的。以后有空再看看吧。
---------------------------------------------------------------------------------------------
这边说明怎么通过修改label中预设的classes.txt。
在label目录下面的data/predefined_classes.txt。
删除默认的类别,添加自己的类目就好了。建议采取这种做法。后续我这个笔记中的模型训练是用的这部分标注出来的数据训练的。
2.模型训练
在yolov5的目录下创建如下文件
yolov5
└─ score
├─ images
│ ├─ test # 下面放测试集图片
│ ├─ train # 下面放训练集图片
│ └─ val # 下面放验证集图片
└─ labels
├─ test # 下面放测试集标签
├─ train # 下面放训练集标签
├─ val # 下面放验证集标签
将label中训练的标签以及图片放进去。我个人是test、train、val都放一样的(如果放一样会导致后续结果很差,需要放不一样的数据)
在机器学习中,通常将数据集划分为训练集(training set)、验证集(validation set)和测试集(test set),以评估模型的性能和泛化能力。
训练集用于训练模型,验证集用于调整模型的超参数和防止过拟合,测试集用于评估模型在未见过的数据上的性能和泛化能力。具体来说:
-
训练集:用于训练模型的数据集。通常,训练集应该包含足够的数据,以覆盖数据集的各种情况和变化,并且应该是代表性的、随机的和独立的。训练集的目的是让模型学习到数据的本质特征,并尽可能减少模型在训练集上的误差。
-
验证集:用于调整模型的超参数和防止过拟合的数据集。通常,验证集应该是独立的、随机的和代表性的,应该与训练集和测试集不同。验证集的目的是评估模型在未见过的数据上的性能,并根据性能指标调整模型的超参数和防止过拟合。
-
测试集:用于评估模型在未见过的数据上的性能和泛化能力的数据集。通常,测试集应该是独立的、随机的和代表性的,应该与训练集和验证集不同。测试集的目的是评估模型在未见过的数据上的性能和泛化能力,并验证模型的泛化能力是否足够好。
为了确保模型的性能评估具有客观性和准确性,训练集、验证集和测试集应该是独立的、随机的和代表性的,并且应该彼此不同。通常,建议将数据集划分为训练集、验证集和测试集,并采用交叉验证等方法进行性能评估,以提高模型的性能和泛化能力。
训练集:用于训练模型以及确定参数。相当于老师教学生知识的过程。
验证集:用于确定网络结构以及调整模型的超参数。相当于月考等小测验,用于学生对学习的查漏补缺。
测试集:用于检验模型的泛化能力。相当于大考,上战场一样,真正的去检验学生的学习效果。
所以我感觉正是测试测试集的过程中,才出来的精确率、召回率等参数。
修改一下配置文件,我们需要在data目录下创建一个mask_data.yaml的文件:
train: D:/software/yolo/yolov5/score/images/train val: D:/software/yolo/yolov5/score/images/val # Classes nc: 2 # number of classes names: ['file', 'dir'] # class names
这个就根据自己的yolov5的路径,类目个数以及类别名称修改一下就行了,就是个配置文件。
在models下建立一个mask_yolov5s.yaml的模型配置文件,内容如下(就是把yolov5s.yaml文件复制一下,然后修改一下):
nc: 2 # number of classes
只要修改一下这个就行了。改成自己类目的个数。
开始模型训练:
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu
其中yolov5s.pt如果源码中没有,可以去git上下。在上一章节有说怎么获取。这边就不在重复了。其实yolov5s.pt的路径是yolov5目录下的models,然后自己创建一个pretrained目录。
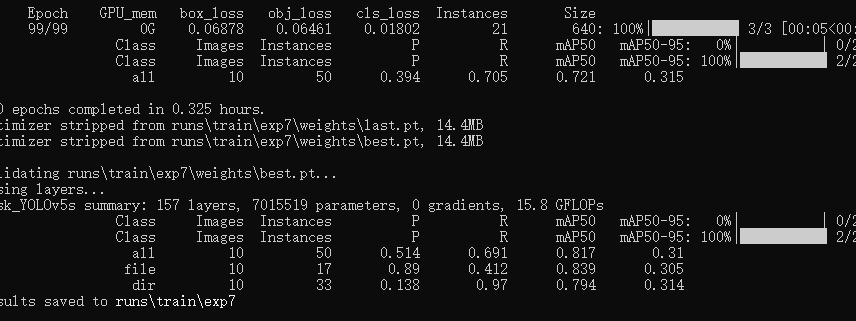
训练完后在runs/train/exp7生成对应结果。主要关注一下best.pt,这就是我们训练出来要使用的模型。
验证一下:
python detect.py --weights runs/train/exp7/weights/best.pt --source score/images/test

发现会对同一个目标反复框,查询了一下,增加 NMS 阈值可以减少重叠框的数量,从而提高检测的准确率。默认是0.25。
python detect.py --weights runs/train/exp7/weights/best.pt --source score/images/test --conf 0.8
这样就好多了。不过很多还是不能准确识别出来,应该还是数据训练的不够。后续再多点样本试一试。

