


《中断学习(一) —— Linux中断流程以及处理机制》
1.触发中断后的基本流程
发生中断后,CPU跳转到异常向量表去执行相对应的指令。
执行 ldr pc, _irq这条指令。(以上都是由硬件直接触发,irq是我们写好的代码)
ldr pc, _irq这条指令主要流程分为:保护现场,判断中断源,调用中断处理函数,恢复现场。
异常向量表:
_start: b reset ldr pc, _undefined_instruction ldr pc, _software_interrupt ldr pc, _prefetch_abort ldr pc, _data_abort ldr pc, _not_used ldr pc, _irq //发生中断时, CPU 跳到这个地址执行该指令 **假设地址为 0x18** ldr pc, _fiq
异常向量表,每一条指令对应一种异常。
发生复位时, CPU 就去 执行第 1 条指令: b reset。
发生中断时, CPU 就去执行“ldr pc, _irq”这条指令。
这些指令存放的位置是固定的。比如对于 ARM9 芯片中断向量的地址是 0x18。 (这里指的是偏移位置)
当然,向量表的位置并不总是从 0 地址开始,很多芯片可以设置某个 vector base 寄存器,指定向量表在其他位置,比如设置 vector base 为 0x80000000,指定为 DDR 的某个地址。但是表中的各个异常向量的偏移地址,是固定的:复位向量偏移地址是 0,中断是 0x18。
2.Linux系统对中断的处理
2.1 ARM程序运行过程
首先需要明白一个概念:ARM芯片属于RISC。
RISC的特点是:对内存只有读、写指令。对于数据的运算是在cpu内部实现。
举例:a = a + b;这条算法,在ARM中分四步实现:
- 从内存a中读出a的值
- 从内存b中读出b的值
- 在cpu中计算a+b
- 将a+b的值写入到内存a中
在ARM中有不同的工作模式,不同的工作模式对应着不同寄存器组。因此从内存中读出的数据就是存放在寄存器中。(ARM寄存器及功能介绍)
因此实际的ARM中的操作是:
- 把内存a的值读取CPU寄存器R0
- 把内存b的值读入CPU寄存器R1
- 把R0、R1相加,存入R0
- 把R0的值写入内存a
2.2 进程、线程、中断的切换
进程、线程、中断的核心是栈。栈 (stack) 是一种串列形式的数据结构。这种数据结构的特点是后入先出。
那么程序被中断,怎么保存现场?
- 程序A正常运行中,突然中断触发。程序A被打断,这个时候会暂停程序A运行,将程序A中所有的寄存器保存下来。这也就保存现场。
- 这些寄存器会被保存在内存中,而这块内存就被称为栈。
- 然后ARM去执行中断程序。
- 等中断程序执行完了,从栈中恢复刚被保存的寄存器值。
进程和线程的切换也是大致如此。
3.Linux中断
Linux中有硬件中断和软件中断。但是对于硬件中断的处理有两个原则:不能嵌套,越快越好。(早起Linux版本是支持中断嵌套)
当ARM处理器收到中断的时候,它进入中断模式,同时ARM处理器的CPSR寄存器的IRQ位会被硬件设置为屏蔽IRQ。
Linux为什么不支持中断嵌套?
中断嵌套,可能导致栈溢出。因为要一直保存现场。
对于比较耗时的中断怎么办?
1.将中断分为上、下两个部分。上半部分简单的接收数据(中断触发会被屏蔽,硬件自动屏蔽),将耗时的处理放在下半部分(可以被其他硬件中断打断)。《tasklet机制和workqueue机制》
2.用内核线程用来处理线程。
3.1 硬件中断
对于按键中断等硬件产生的中断,称之为“硬件中断” (hard irq)。每个硬件中断都有对应的处理函数,比如按键中断、网卡中断的处理函数肯定不一样。
为方便理解,你可以先认为对硬件中断的处理是用数组来实现的,数组里存放的是函数指针:

当硬件触发中断后,会自动跳转到异常向量表的irq中,然后判断中断源,再跳转到对应的中断服务函数中。以上都是硬件自己做的。
实际的中断处理流程比这个复杂多了。以上只是简化了解。
3.2 软件中断:
比如发送异步通知机制,就是一种软件中断。
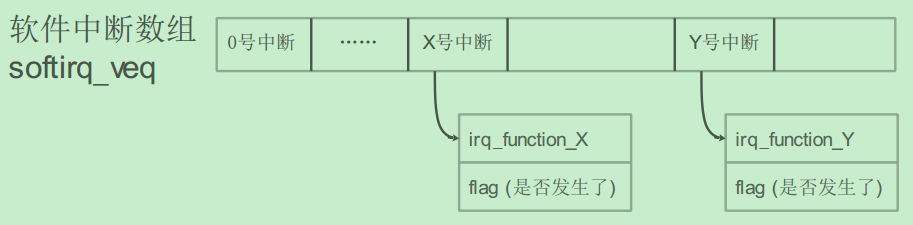
对于X号中断,只需要把它的flag设置为1就表示发生了该中断。
3.3 软件中断什么时候去执行?
Linux系统中,各种硬件中断发生的很频繁,至少定时器中断每10ms发生一次(心跳)。所以在处理完硬件中断后,再去处理软件中断。

硬件中断A处理过程中,没有其他中断发生:
- 中断A发生,count++等于1。
- 硬件屏蔽中断,中断A上半部运行处理。count--等于0。
- count++等于1,硬件开启接收硬件中断,执行软件中断也就是所谓的中断下半部。
- count--等于0。然后退出。
硬件中断A处理过程中,又再次发生了中断A:(以下两种情况的不同之处在于最后红字部分)
1.第一次中断A发生,执行到第⑥时,一开中断后,中断 A 又再次使得 CPU 跳到中断向量表。 这时 count 等于 1,并且中断A下半部的代码并未执行。
2.CPU 又从①开始再次执行中断 A 的上半部代码,在① 中count++等于2,到③后count--等于1。
3.在第④步发现 count 等于 1,所以直接结束当前第 2 次中断的处理。
4.重点来了,第 2 次中断发生后,打断了第一次中断的第⑦步处理。当第 2 次中断处理完毕, CPU会继续去执行第⑦步 。
可以看到,发生 2 次硬件中断 A 时,它的上半部代码执行了 2 次,但是下半部代码只执行了一次。
硬件中断 A 处理过程中,又再次发生了中断 B:
1.第一次中断A发生,执行到第⑥时,一开中断后,中断 B 又再次使得 CPU 跳到中断向量表。 这时 count 等于 1,并且中断下半部的代码并未执行。
2.CPU 又从①开始执行中断 B 的上半部代码,在① 中count++等于2,到③后count--等于1。
3.在第④步发现 count 等于 1,所以直接结束当前第 2 次中断的处理。
4.重点来了,第 2 次中断发生后,打断了第一次中断的第⑦步处理。当第 2 次中断处理完毕, CPU会继续去执行第⑦步 。
最后:在第⑦步里,它会去执行中断 A 的下半部,也会去执行中断 B 的下半部。 所以,多个中断的下半部,是汇集在一起处理的。
注意:
中断上半部、下半部的执行过程中,不能休眠。
3.4 为什么中断上下文不能休眠?(参考《为什么Linux不能在中断中睡眠》)
如果在中断上半部睡眠,会发生?
在中断上半部执行的时候,硬件是屏蔽了中断接收的。所以操作系统接收不到任何中断(包括时钟中断),系统就会瘫痪。(调度器依赖的时钟节拍也会没有)
中断下半部(软中断)不能睡眠:
不能睡眠的关键是因为上下文。
操作系统以进程调度为单位,进程的运行在进程的上下文中,以进程描述符作为管理的数据结构。进程可以睡眠的原因是操作系统可以切换不同进程的上下文,进行调度操作,这些操作都以进程描述符为支持。 中断运行在中断上下文,没有一个所谓的中断描述符来描述它,它不是操作系统调度的单位。一旦在中断上下文中睡眠,首先无法切换上下文(因为没有中断描述符,当前上下文的状态得不到保存),其次,没有人来唤醒它,因为它不是操作系统的调度单位。 此外,中断的发生是非常非常频繁的,在一个中断睡眠期间,其它中断发生并睡眠了,那很容易就造成中断栈溢出导致系统崩溃。
上下文错乱:
睡眠函数会调用schedule(),切换进程时,保存当前的进程上下文(CPU寄存器的值、进程的状态以及堆栈中的内容),以便以后恢复此进程运行。中断发生后,内核会先保存当前被中断的进程上下文(在调用中断处理程序后恢复);但在中断处理程序里,CPU寄存器的值肯定已经变化了吧(最重要的程序计数器PC、堆栈SP等),如果此时因为睡眠或阻塞操作调用了schedule(),则保存的进程上下文就不是当前的进程context了,所以不可以在中断处理程序中调用schedule()。
Linux是以进程为调度单位的,调度器只看到进程内核栈,而看不到中断栈。在独立中断栈的模式下,如果linux内核在中断路径内发生了调度(从技术上讲,睡眠和调度是一个意思),那么linux将无法找到“回家的路”,未执行完的中断处理代码将再也无法获得执行机会,因为没有人能够唤醒它。
还有一个其他人的总结:
Linux 设计中,中断处理时不能睡眠,这个内核中有很多保护措施,一旦检测到内核会异常。
当 一个进程A因为中断被打断时,中断处理程序会使用 A 的内核栈来保存上下文,因为是“抢”的 A 的CPU,而且用了 A 的内核栈,因此中断应该尽可能快的结束。如果 do_IRQ 时又被时钟中断打断,则继续在 A 的内核栈上保存中断上下文,如果发生调度,则 schedule 进 switch_to,又会在 A 的 task_struct->thread_struct 里保存此时时种中断的上下文。
假如其是在睡眠时被时钟中断打断,并 schedule 的话,假如选中了进程 A,并 switch_to 过去,时钟中断返回后则又是位于原中断睡眠时的状态,抛开其扰乱了与其无关的进程A的运行不说,这里的问题就是:该如何唤醒之呢??
另外,和该中断共享中断号的中断也会受到影响。
如果条件满足了(即:有中断描述符,并成为调度器的调度单位,栈也不溢出了,理论上是可以做到中断睡眠的),中断是可以睡眠的,但会引起很多问题:
例如,你在时钟中断中睡眠了,那操作系统的时钟就乱了,调度器也了失去依据;例如,你在一个IPI(处理器间中断)中,其它CPU都在死循环等你答复,你却睡眠了,那其它处理器也不工作了;
例如,你在一个DMA中断中睡眠了,上面的进程还在同步的等待I/O的完成,性能就大大降低了……还可以举出很多例子。
所以,中断是一种紧急事务,需要操作系统立即处理,不是不能做到睡眠,是它没有理由睡眠。
4.执行中断下半部的三种机制(具体可以查看《中断下半部处理tasklet机制、workqueue机制和threaded irq》)
4.1 tasklet机制
tasklet机制主要用在下半部要做的事耗时不是太长。
注意:使用tasklet机制的时候,不能使用睡眠或者会产生调度的函数。3.3的流程就是tasklet机制。
4.2 workqueue工作队列
workqueue主要用在事情很多,并且复杂。因此执行时间比较长。
tasklet机制是使用软件中断去实现的。但是如果下半部的运行时间很长,那么就会导致APP卡死。因为不能进行上下文切换。
所以可以用内核线程去实现。在中断上半部唤醒内核线程。内核线程和 APP 都一样竞争执行, APP 有机会执行,系统不会卡顿。
这个内核线程是系统帮我们创建的,一般是 kworker 线程,内核中有很多这样的线程:
kworker 线程要去“工作队列” (work queue)上取出一个一个“工作” (work),来执行它里面的函数。
4.3 threaded irq
work 来线程化地处理中断,一个 worker 线程只能由一个 CPU 执行,多个中断的 work 都由同一个 worker 线程来处理,在单 CPU 系统中也只能忍着了。但是在 SMP 系统中,明明有那么多 CPU 空着,你偏偏让多个中断挤在这个 CPU 上?
新技术 threaded irq,为每一个中断都创建一个内核线程;多个中断的内核线程可以分配到多个 CPU

