《Linux应用文件编程(一) — 文件IO》
1.文件IO的概念
linux文件IO操作有两套大类的操作方式:不带缓存的文件IO操作,带缓存的标准IO操作。不带缓存的属于直接调用系统调用(system call)的方式,高效完成文件输入输出。它以文件标识符(整型)作为文件唯一性的判断依据。这种操作不是ASCI标准的,与系统有关,移植有一定的问题。而带缓存的是在不带缓存的基础之上封装了一层,维护了一个输入输出缓冲区,使之能跨OS,成为ASCI标准,称为标准IO库。不带缓存的方式频繁进行用户态 和内核态的切换,高效但是需要程序员自己维护;带缓冲的方式因为有了缓冲区,不是非常高效,但是易于维护。由此,不带缓冲区的通常用于文件设备的操作(文件IO),而带缓冲区的通常用于普通文件的操作(标准IO)。
明确一个概念:不带缓冲是什么意思?
不带缓存,不是直接对磁盘文件进行读取操作,像read()和write()函数,都属于系统调用,只不过在用户层没有缓存,所以叫做无缓存IO,但对于内核来说,还是进行了缓存,叫做内核IO缓冲区。其中标准IO是在用户层维护一个IO缓冲区,可以称为用户空间IO缓冲区。
带不带缓存是相对来说的,如果要写数据到文件上(就是写入磁盘上),内核先将数据写入到内核中所设的缓冲储存器,假如这个缓冲储存器的长度是100个字节,调用系统函数:ssize_t write (int fd,const void * buf,size_t count);写操作时,假设每次写入长度count=10个字节,那么要调用10次这个函数才能把这个缓冲区写满,此时数据还是在缓冲区,并没有写入到磁盘,缓冲区满时才进行实际上的IO操作,把数据写入到磁盘上,所以上面说的“不带缓存不是没有缓存直接写进磁盘”就是这个意思。
2.文件描述符
文件描述符是一个非负整数,用来标识一个进程中打开或创建的文件。当打开一个现有文件或创建一个新文件时,内核向应用程序进程返回一个文件描述符。当读或写一个文件时,使用open或creat返回的文件描述符标识该文件,将其作为参数传递给read或write等操作函数。文件描述符的作用域限于当前应用程序的进程,文件关闭close后,文件描述符将被释放。在遵从POSIX的应用程序中,文件描述符0、1、2分别对应STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO,因此一个应用程序进程中文件描述符总是从3开始的。
3.常用文件IO函数
3.1 open函数
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
返回值:
成功返回打开或创建文件的文件描述符,如果失败返回-1。
参数:
pathname:文件路径
flags:
O_RDONLY //只读打开
O_WRONLY //只写打开
O_RDWR //读、写打开
O_CREAT //若此文件不存在,则创建它。使用时,需要第三个参数mode
O_EXCL //测试一个文件是否存在。如果同时指定了O_CREAT。如果文件不存在,则创建此文件。,而文件存在,则会出错返回-1。单独使用时,如果文件不存在返回-1,文件存在返回文件的描述符
O_APPEND //每次写时都追加到文件的尾端
O_TRUNC //如果此文件存在,那么打开文件时先删除文件中原有数据
O_NONBLOCK //如果pathname指的是一个FIFO、一个块特殊文件或一个字符特殊文件,则此选项为文件的本次操作和后续的I/O操作设置非阻塞模式。只用于设备文件。
O_SYNC //使每次write都等到物理I/O操作完成,包括write操作引起的文件数据更新所需的I/O。
mode:使用四个数字指定创建文件的权限,与linux的权限设置相同。如果0x0755
话说上面两个函数。有点像C++的函数重载。但是C语言不支持重载。那为什么open的系统调用可以有两个open原型呢?
实际上只提供一个系统调用,对应的是上述两个函数原型中的第二个。当我们调用open函数时,实际身上调用的是glibc封装的函数,然后由glibc通过自陷指令,进行真正的系统调用。
在fcntl.h中open函数的声明也确认
extern int open(_const char *_file, int _oflag, ...) _nonnull((1));
所以即使传入4个参数,open编译的时候也不会报错。
针对O_CREAT和O_EXCL做一个说明:
首先需要声明的是open(pathname, O_RDWR | O_CREAT | O_EXCL,0666)这种操作是原子操作。
经常可以看到有人是这样来测试文件是否存在的:
if( access(file, R_OK) == -1 ) /* 首先检查文件是否存在 */
open(file, O_RDWR | O_CREAT,0666); /* 如果不存在,那我创建一个这样的文件 */
... /* 继续执行任务 */
由于我们的系统是多进程的。那么上面这种方式就可能出现,当进程1中的access判断文件不存在,然后准备创建文件前。进程2中刚好也有一个access去判断这个文件也会判断出不存在。这样进程1和2都会创建文件。
创建进程1和进程2。进程1在检测到没有文件的时候延时15秒。进程2不做延时直接创建文件并且写入数据。
进程1:
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int fd;
char data[] = "456";
if(access("./1", R_OK) == -1)
{
sleep(15);
fd = open("./1", O_RDWR | O_CREAT, 0x666 );
printf("fd = %d \n", fd);
}
write(fd, data, 3);
close(fd);
return 0;
}
进程2:
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int fd;
char data[] = "123";
if(access("./1", R_OK) == -1)
{
fd = open("./1", O_RDWR | O_CREAT, 0x666 );
printf("process 2 fd = %d \n", fd);
}
write(fd, data, 3);
close(fd);
return 0;
}
先运行进程1,再运行进程2。最后可以发现文件1中的数据是456,也就是进程2写入的数据都没有了。
3.2 close函数
#include <unistd.h>
int close(fd);
参数:
fd:已打开文件的文件描述符
关闭文件描述符fd指向的动态文件,并存储文件和刷新缓存。
《进程未close文件导致文件资源泄露问题定位 —— lsof》 - 一个不知道干嘛的小萌新 - 博客园 (cnblogs.com)
3.3 read函数
#include <unistd.h> ssize_t read(int fd, void *buf, size_t count); 返回值:成功返回读取的字节数,失败返回-1;
注意:当返回0的时候表示已经到了“文件尾”。read还有可能读取比count小的字节数。
使用 read 进行数据读取时,要注意正确地处理错误,也是说 read 返回 -1 时,如果 errno 为 EAGAIN 、EWOULDBLOCK 或 EINTR ,一般情况下都不能将其视为错误。因为前两者是由于当前 fd 为非阻塞且没有可读数据时返回的,后者是由于 read 被信号中断所造成的。这两种情况基本上都可以视为正常情况。
为什么read可能读取比count小的字节数?
在socket文件系统中,UDP当报文的数据长度小于count时,就会只复制实际的数据长度。但是TCP就不一定了,有可能阻塞也会可能直接返回。TCP 是否阻塞,取决于当前缓存区可用数据多少,要读取的字节数,以及套接字设置的接收低水位大小。
read是阻塞还是非阻塞?
read函数只是一个通用的读文件设备的接口。是否阻塞需要由设备的属性和设定所决定。一般来说,读字符终端、网络的socket描述字,管道文件等,这些文件的缺省read都是阻塞的方式。如果是读磁盘上的文件,一般不会是阻塞方式的。但使用锁和fcntl设置取消文件O_NOBLOCK状态,也会产生阻塞的read效果。
可以使用select来判断当前文件描述符是否有数据可读?当可读的时候再调用read函数。
3.4 write函数
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
返回值:
成功返回写入的字节数,失败返回-1。
注意:write也有可能出现部分写入的情况。这种情况取决于设备端的具体实现。
当调用write()函数写出数据时,数据一旦写到该缓冲区(关键:只是写到缓冲区),函数便立即返回.此时写出的数据可以用read()读回,也可以被其他进程读到,但是并不意味着它们已经被写到了外部永久存储介质上,即使调用close()关闭文件后也可能如此. 因为缓冲区的数据可能还在等待输出。
拓展:
追加写的实现:
文件的读写操作都是从当前文件的偏移处开始的。这个文件偏移量保存在文件表中,而每个进程都有一个文件表。那么当多个进程同时写一个文件时,即使对 write 进行了锁保护,在进行串行写操作时,文件依然不可避免地会被写乱,因为每个进程各自维护一个文件表。
《同时读写文件 —— 偏移量》 - 一个不知道干嘛的小萌新 - 博客园 (cnblogs.com)
3.5 文件原子读写pread、pwrite
#include <unistd.h> ssize_t pread(int fd, void *buf, size_t count, off_t offset); ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
对比传统的read和write:
- pread和pwrite是线程安全的,而传统方式不是。
- 功能一样,但是系统调用更少,性能更高。传统方式还需要使用seek或者lseek进行偏移
- pread和pwrite是原子操作,而传统方式不是。
- pread和pwrite不会更改文件的偏移量,而传统方式会。(在多线程中这点很有用处)
pread相当于调用了下面:
off_t orig; orig = lseek(fd,0,SEEK_CUR); lseek(fd,offset,SEEK_SET); s = read(fd,buf,len); lseek(fd,orig,SEEK_SET);
因此会从pread是从文件头开始做offset。之后会把文件本身的offset保持不变。
3.6 sync、fsync、fdatasync函数
void sync(void);
sync负责将系统缓冲区的数据(不是对某一个指定文件进行数据更新,而是刷新所有文件I/O内核缓冲区)“写入”磁盘,以确保数据的一致性和同步性.
注意:sync函数只是将所有修改过的块缓冲区排入写队列,然后就返回,他并不等待实际I/O操作结束.所以不要认为调用了sync函数,就觉得数据已安全的送到磁盘文件上,有可能会出现问题,但是sync函数是无法得知的.
系统守候进程一般每隔一段时间调用一次sync函数,确保定期刷新内核的块缓存.UNIX系统中,系统守候进程update会周期性地(一般每个30秒)调用sync函数。命令sync(1)也调用sync函数.
sync 特点:因为不等队列写后端完成即返回,性能好。但掉电有丢数据风险;
int fsync(int fd); 返回值:若成功则返回0,若出错则返回-1,同时设置errno以指明错误.
与sync函数不同,fsync函数只对由文件描符fd指定的单一文件起作用,强制与描述字fd相连文件的所有修改过的数据(包括核内I/O缓冲区中的数据)传送到外部永久介质,即刷新fd给出的文件的所有信息,并且等待写磁盘操作结束,然后返回。调用 fsync()的进程将阻塞直到设备报告传送已经完成。这个fsync就安全点了。
一个程序在写出数据之后,如果继续进行后续处理之前要求确保所写数据已写到磁盘,则应当调用fsync()。例如,数据库应用通常会在调用write()保存关键交易数据的同时也调用fsync().这样更能保证数据的安全可靠。
fsync 特点:修复掉电丢数据风险,即刷新fd给出的文件的所有信息,并且等待写磁盘操作结束,然后返回。但性能差;
int fdatasync(int filedes); 返回值:若成功则返回0,若出错则返回-1,同时设置errno以指明错误.
fdatasync函数类似于fsync函数,但它只影响文件数据部分,强制传送用户已写出的数据至物理存储设备,不包括文件本身的特征数据.这样可以适当减少文件刷新时的数据传送量.而除数据外,fdatasync还会同步更新文件的属性.
fdatasync 特点:修复掉电丢数据风险,只刷新data部分,不包含文件特征的部分。性能较fsync好,比sync差;我们一般用这个特性;
fdatasync()的目的是减少不需要与磁盘同步所有元数据的应用程序的磁盘活动。
fflush()与fsync()的联系:
内核I/O缓冲区是由操作系统管理的空间,而流缓冲区是由标准I/O库管理的用户空间.fflush()只刷新位于用户空间中的流缓冲区.fflush()返回后,只保证数据已不在流缓冲区中,并不保证它们一定被写到了磁盘.此时,从流缓冲区刷新的数据可能已被写至磁盘,也可能还待在内核I/O缓冲区中.要确保流I/O写出的数据已写至磁盘,那么在调用fflush()后还应当调用fsync()。
(34条消息) 关于Linux执行文件操作,断电后数据丢失问题_屁股大象的博客-CSDN博客_linux掉电数据丢失
【Linux编程】如何保证数据存文件不丢失 - 墨天轮 (modb.pro)
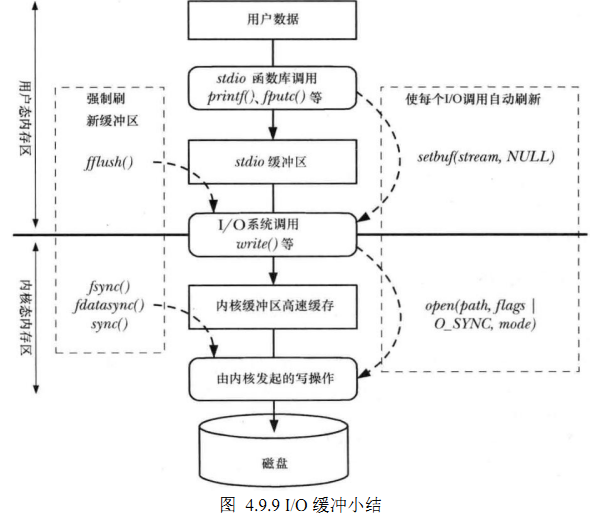
3.7 lseek函数
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
返回值:
成功,返回当前的位置,即当前位置距离文件开头的字节数,失败返回-1
参数:
Offset:偏移量
Whence:偏移基址
SEEK_SET:将读写位置指向文件头后再增加offset个位移量
SEEK_CUR:以目前的读写位置往后增加offset个位移量
SEEK_END:将读写位置指向文件尾后再增加offset个位移量
A、欲将读写位置移到文件开头时
lseek(int fd,0,SEEK_SET); 返回0
B、欲将读写位置移到文件尾时
lseek(int fd,0,SEEK_END); 返回文件长度
C、想要取得目前文件位置时
lseek(int fd,0,SEEK_CUR); 返回当前文件指针相对于文件开头的偏移量
D、计算文件长度
int get_file_length(const char *filename)
{
unsigned int n = 0;
unsigned int fd = open(filename, O_RDONLY);
if(fd < 0)
{
fprintf(stderr, "error:%s PID: %d\n", strerror(errno), getpid());
return -1;
}
n = lseek(fd, 0, SEEK_END);
close(fd);
return n;
}
注意:当调用完lseek(fd, 0, SEEK_END)后,此时fd这个文件的读写位置就在文件的最后一个,此时调用read的话,读取到的是0。
3.8 dup函数
int dup(int oldfd); int dup2(int oldfd, int newfd); int dup3(int oldfd, int newfd, int flags);
dup函数创建一个新的文件描述符,该新文件描述符和原文件描述符指向相同的文件、管道、或网络连接。
dup 会使用一个最小的未用文件描述符作为复制后的文件描述符。
dup2 是使用用户指定的文件描述符 newfd 来复制 oldfd 的。如果 newfd 已经是打开的文件描述符, Linux 会先关闭 newfd ,然后再复制 oldfd。可以用来做重定向,保证原子性。(否则需要先close newfd,这个newfd之前被打开过,然后把需要重定向的oldfd dup到newfd)
dup3 ,只有定义了 feature 宏 “_GNU_SOURCE” 才可以使用,它比 dup2 多了一个参数,可以指定标志 —— 不过目前仅仅支持 O_CLOEXEC 标志,可在 newfd 上设置 O_CLOEXEC 标志。定义 dup3 的原因与open 类似,可以在进行 dup 操作的同时原子地将 fd 设置为 O_CLOEXEC ,从而避免将文件内容暴露给子进程。
O_CLOEXEC标志的作用后续再讨论?
#include<stdio.h> #include<unistd.h> #include<fcntl.h> #include<string.h> int main() { int oldfd = open("wyg.txt",O_RDWR | O_CREAT,664); if(oldfd < 0) { perror("open"); } printf("oldfd is : %d\n",oldfd); int newfd = dup2(oldfd , 1); if(newfd < 0) { perror("dup"); } printf("this is new data,newfd:%d\n",newfd); return 0; }
在该程序中,dup2函数创建新的指向xyg.txt文件的文件描述符为1,即wyg.txt文件的描述符为标准输出描述符,此时本来打印到终端的字符串就打印到了wyg.txt文件中了。这也是Linux操作系统的重定向实现方法。
E、创建空洞文件
int create_null_file(const char *filename, unsigned int len)
{
unsigned int fd = open(filename, O_RDWR | O_CREAT | O_TRUNC, 0666);
if(fd < 0)
{
fprintf(stderr, "error:%s PID: %d", strerror(errno), getpid());
return -1;
}
lseek(fd, len, SEEK_SET);
write(fd, "\0",1);
close(fd);
return 0;
}
4. 错误信息
linux下错误的捕获:errno、strerror和perror的使用
经常在调用linux 系统api 的时候会出现一些错误,比方说使用open() write() creat()之类的函数有些时候会返回-1,也就是调用失败,这个时候往往需要知道失败的原因。这个时候使用errno这个全局变量就相当有用了。
#include <string.h> char *strerror(int errnum); fprintf(stderr, "error : %s, PID: %d", strerror(errno), getpid()); 根据errnum错误码返回一个指向描述errnum错误码信息的字符串指针。 #include <stdio.h> void perror(const char *s); perror()用来将上一个函数发生错误的原因输出到标准错误(stderr) 参数s所指的字符串会先打印出,后面在加上错误原因字符串
errno就是error number。
如果程序代码中包含 #include <errno.h>,函数调用失败的时候,系统会自动用用错误代码填充errno这个全局变量,取读errno全局变量可以获得失败原因。函数调用失败是否会设置errno全局变量由函数决定,并不是所有函数调用失败都会设置errno变量。
errno.h中定义的错误代码值如下:
查看错误代码errno是调试程序的一个重要方法。当linuc C api函数发生异常时,一般会将errno变量(需include errno.h)赋一个整数值,不同的值表示不同的含义,可以通过查看该值推测出错的原因。在实际编程中用这一招解决了不少原本看来莫名其妙的问题。比较 麻烦的是每次都要去linux源代码里面查找错误代码的含义,现在把它贴出来,以后需要查时就来这里看了。
以下来自linux 2.4.20-18的内核代码中的/usr/include/asm/errno.h
#ifndef _I386_ERRNO_H #define _I386_ERRNO_H #define EPERM 1 /* Operation not permitted */ #define ENOENT 2 /* No such file or directory */ #define ESRCH 3 /* No such process */ #define EINTR 4 /* Interrupted system call */ #define EIO 5 /* I/O error */ #define ENXIO 6 /* No such device or address */ #define E2BIG 7 /* Arg list too long */ #define ENOEXEC 8 /* Exec format error */ #define EBADF 9 /* Bad file number */ #define ECHILD 10 /* No child processes */ #define EAGAIN 11 /* Try again */ #define ENOMEM 12 /* Out of memory */ #define EACCES 13 /* Permission denied */ #define EFAULT 14 /* Bad address */ #define ENOTBLK 15 /* Block device required */ #define EBUSY 16 /* Device or resource busy */ #define EEXIST 17 /* File exists */ #define EXDEV 18 /* Cross-device link */ #define ENODEV 19 /* No such device */ #define ENOTDIR 20 /* Not a directory */ #define EISDIR 21 /* Is a directory */ #define EINVAL 22 /* Invalid argument */ #define ENFILE 23 /* File table overflow */ #define EMFILE 24 /* Too many open files */ #define ENOTTY 25 /* Not a typewriter */ #define ETXTBSY 26 /* Text file busy */ #define EFBIG 27 /* File too large */ #define ENOSPC 28 /* No space left on device */ #define ESPIPE 29 /* Illegal seek */ #define EROFS 30 /* Read-only file system */ #define EMLINK 31 /* Too many links */ #define EPIPE 32 /* Broken pipe */ #define EDOM 33 /* Math argument out of domain of func */ #define ERANGE 34 /* Math result not representable */ #define EDEADLK 35 /* Resource deadlock would occur */ #define ENAMETOOLONG 36 /* File name too long */ #define ENOLCK 37 /* No record locks available */ #define ENOSYS 38 /* Function not implemented */ #define ENOTEMPTY 39 /* Directory not empty */ #define ELOOP 40 /* Too many symbolic links encountered */ #define EWOULDBLOCK EAGAIN /* Operation would block */ #define ENOMSG 42 /* No message of desired type */ #define EIDRM 43 /* Identifier removed */ #define ECHRNG 44 /* Channel number out of range */ #define EL2NSYNC 45 /* Level 2 not synchronized */ #define EL3HLT 46 /* Level 3 halted */ #define EL3RST 47 /* Level 3 reset */ #define ELNRNG 48 /* Link number out of range */ #define EUNATCH 49 /* Protocol driver not attached */ #define ENOCSI 50 /* No CSI structure available */ #define EL2HLT 51 /* Level 2 halted */ #define EBADE 52 /* Invalid exchange */ #define EBADR 53 /* Invalid request descriptor */ #define EXFULL 54 /* Exchange full */ #define ENOANO 55 /* No anode */ #define EBADRQC 56 /* Invalid request code */ #define EBADSLT 57 /* Invalid slot */ #define EDEADLOCK EDEADLK #define EBFONT 59 /* Bad font file format */ #define ENOSTR 60 /* Device not a stream */ #define ENODATA 61 /* No data available */ #define ETIME 62 /* Timer expired */ #define ENOSR 63 /* Out of streams resources */ #define ENONET 64 /* Machine is not on the network */ #define ENOPKG 65 /* Package not installed */ #define EREMOTE 66 /* Object is remote */ #define ENOLINK 67 /* Link has been severed */ #define EADV 68 /* Advertise error */ #define ESRMNT 69 /* Srmount error */ #define ECOMM 70 /* Communication error on send */ #define EPROTO 71 /* Protocol error */ #define EMULTIHOP 72 /* Multihop attempted */ #define EDOTDOT 73 /* RFS specific error */ #define EBADMSG 74 /* Not a data message */ #define EOVERFLOW 75 /* Value too large for defined data type */ #define ENOTUNIQ 76 /* Name not unique on network */ #define EBADFD 77 /* File descriptor in bad state */ #define EREMCHG 78 /* Remote address changed */ #define ELIBACC 79 /* Can not access a needed shared library */ #define ELIBBAD 80 /* Accessing a corrupted shared library */ #define ELIBSCN 81 /* .lib section in a.out corrupted */ #define ELIBMAX 82 /* Attempting to link in too many shared libraries */ #define ELIBEXEC 83 /* Cannot exec a shared library directly */ #define EILSEQ 84 /* Illegal byte sequence */ #define ERESTART 85 /* Interrupted system call should be restarted */ #define ESTRPIPE 86 /* Streams pipe error */ #define EUSERS 87 /* Too many users */ #define ENOTSOCK 88 /* Socket operation on non-socket */ #define EDESTADDRREQ 89 /* Destination address required */ #define EMSGSIZE 90 /* Message too long */ #define EPROTOTYPE 91 /* Protocol wrong type for socket */ #define ENOPROTOOPT 92 /* Protocol not available */ #define EPROTONOSUPPORT 93 /* Protocol not supported */ #define ESOCKTNOSUPPORT 94 /* Socket type not supported */ #define EOPNOTSUPP 95 /* Operation not supported on transport endpoint */ #define EPFNOSUPPORT 96 /* Protocol family not supported */ #define EAFNOSUPPORT 97 /* Address family not supported by protocol */ #define EADDRINUSE 98 /* Address already in use */ #define EADDRNOTAVAIL 99 /* Cannot assign requested address */ #define ENETDOWN 100 /* Network is down */ #define ENETUNREACH 101 /* Network is unreachable */ #define ENETRESET 102 /* Network dropped connection because of reset */ #define ECONNABORTED 103 /* Software caused connection abort */ #define ECONNRESET 104 /* Connection reset by peer */ #define ENOBUFS 105 /* No buffer space available */ #define EISCONN 106 /* Transport endpoint is already connected */ #define ENOTCONN 107 /* Transport endpoint is not connected */ #define ESHUTDOWN 108 /* Cannot send after transport endpoint shutdown */ #define ETOOMANYREFS 109 /* Too many references: cannot splice */ #define ETIMEDOUT 110 /* Connection timed out */ #define ECONNREFUSED 111 /* Connection refused */ #define EHOSTDOWN 112 /* Host is down */ #define EHOSTUNREACH 113 /* No route to host */ #define EALREADY 114 /* Operation already in progress */ #define EINPROGRESS 115 /* Operation now in progress */ #define ESTALE 116 /* Stale NFS file handle */ #define EUCLEAN 117 /* Structure needs cleaning */ #define ENOTNAM 118 /* Not a XENIX named type file */ #define ENAVAIL 119 /* No XENIX semaphores available */ #define EISNAM 120 /* Is a named type file */ #define EREMOTEIO 121 /* Remote I/O error */ #define EDQUOT 122 /* Quota exceeded */ #define ENOMEDIUM 123 /* No medium found */ #define EMEDIUMTYPE 124 /* Wrong medium type */ #endif
errno和strerror实例:
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main(void)
{
int fd;
extern int errno;
if((fd =open("/dev/dsp",O_WRONLY)) < 0)
{
printf("errno=%d\n",errno);
}
exit(0);
}
如果dsp设备忙的话errno值将是16。
同时也可以使用strerror()来自己翻译:
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main(void)
{
int fd;
extern int errno;
if((fd = open("/dev/dsp", O_WRONLY)) < 0)
{
printf("errno=%d\n",errno);
char *mesg=strerror(error);
printf("Mesg:%s\n", mesg);
}
exit(0);
}
dsp设备忙的话将输出如下:
errno=16
Mesg:Device or resource busy
perror实例:
#include <stdio.h>
int main(void)
{
FILE *fp ;
fp = fopen( "/root/noexitfile", "r+" );
if ( NULL == fp ) ?
{
perror("/root/noexitfile");
}
return 0;
运行结果:
[root@localhost io]# gcc perror.c
[root@localhost io]# ./a.out
/root/noexitfile: No such file or directory
5. 文件共享
#include <unistd.h>
int dup(int oldfd);
返回值:
成功返回新分配的文件描述符,失败返回-1
int dup2(int oldfd, int newfd);
返回值:
成功返回新分配的文件描述符,失败返回-1
参数:
newfd为指定的新的文件描述符
文件共享的是三种实现方式:
1、同一个进程中多次打开同一个文件。
2、不同进程中多次打开同一个文件。
3、Dup和dup2让进程复制文件描述符。
同一个进程中多次打开同一个文件,返回的文件描述符不同,同时对这个文件进行写操作时,分别写入内容,后边写入的内容将覆盖前边写入的内容,此时不同的文件描述符拥有自己的文件指针。当open创建、打开文件时采用O_APPEND,则不同的文件描述符的不同文件指针会实现同步。O_APPEND是原子操作的。所谓原子操作,就是该操作绝不会在执行完毕前被任何其他任务或事件打断。
dup函数复制的文件描述符不同,但文件指针相同,所以对文件的操作是原子操作的。
6. 文件IO与标准IO的区别
文件IO与标准IO库的区别:文件IO是linux系统的API,标准IO库是C语言库函数,标准IO库函数由linux API封装而来,函数内部通过调用linux API完成。API在不同的操作系统之间不能通用,C语言库函数可以在不同操作系统之间移植。文件IO函数不带缓存,标准IO库函数带缓存。
7 实例
7.1 用read读取整个文件的大小
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(int argc, char *argv[])
{
char read_buf[100];
ssize_t rd_count;
int fd1;
fd1 = open("./1", O_RDWR);
rd_count = read(fd1, read_buf, 100);
printf("the file count is %d\n", rd_count);
close(fd1);
return 0;
}
再创建一个名字为1的文件。

运行上面程序的结果得到是6。因为还有个“\0”表示结束。
注意:read读出来的整个文件的大小是比实际要多1的。这个是读取整个文件的时候。
7.2 用read和write读写文件位置的问题
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main(int argc, char *argv[])
{
char read_buf[100], write_buf[10] = "123456789";
ssize_t rd_count, wr_count;
int fd1;
fd1 = open("./1", O_RDWR);
rd_count = read(fd1, read_buf, 5);
printf("read count is %d \n", rd_count);
wr_count = write(fd1, write_buf, 8);
printf("wr_count = %d \n", wr_count);
rd_count = read(fd1, read_buf, 100);
printf("read count is %d \n", rd_count);
close(fd1);
return 0;
}
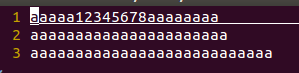
再创建一个名字为1的文件,里面内容为
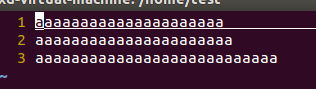
运行上面程序得到的结果:
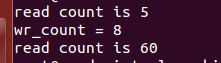
可以看出读写位置会一直跟随着read和write在改变。除非close这个文件再重新open,读写位置才会回到起始点。