

ACL2021 事件抽取相关论文阅读
任务:
1 event detection(ED), 输入是文本序列,输出是触发的事件类型,以及触发词。
2 event causality identification (ECI),输入是文本序列+文本中出现的一对事件,识别事件之间是否有因果关系。
3 event argument extraction (EAE),输入是文本序列+事件触发词+实体,识别出事件各个argument是哪个实体。衍生出来的Implicit Event Argument Extraction (IEAE),是指要在多个句子中进行EAE。
应用场景:问答,逻辑推理
论文:
OntoED: Low-resource Event Detection with Ontology Embedding,提出一种方法解决事件抽取任务中的low-resource问题,通过事件-事件之间的关系构建事件本体及其embedding,将原本的分类问题(一个事件对应一个类别标签,各个事件之间没有关系)转换成相似度问题(一个事件对应一个embedding),事件embedding可以通过事件之间的关系来学习,采用的形式是映射矩阵,即一个事件embedding可以通过关系矩映射到和它相关的另一个事件embedding,每种关系对应一个映射矩阵。从事件本体的角度看,low-resource事件的问题被规避掉了,转而变成事件之间的关系是否足够丰富,只要事件之间的关系足够丰富,就可以学到质量不错的embedding,即使是low-resource事件,他们的embedding也能包含足够的信息。值得一提的是一个事件的embedding初始化,是由数据集中对应该事件的所有instance的编码信息完成的,一般是instance的句子输入到BERT得到的CLS token representation,再对取平均,即事件embedding中的信息本质上还是来自文本。换句话说,low-resource事件相关的语料很少,但是和它相关的其他事件的语料很多,通过事件之间的关系,把部分信息转移给low-resource事件。
Unleash GPT-2 Power for Event Detection,从数据增强角度出发,解决事件抽取任务的low-resoueces问题;使用gpt-2生成新的事件抽取语料及其事件标签,S=[BOS, w1,...,TRGs,wt,TRGe,...,wn, EOS],BOS和EOS表示句子的起始和结束tag,TRGe/s包裹着事件触发词(包含位置信息,但没有类别信息);这里的问题是原始GPT-2预训练任务的输出形式并不是这样的,所以需要对gpt-2上做fine-tune,这篇论文选择在已有事件抽取数据集上对gpt-2做fine-tune。但即使这样做fine-tune,gpt-2生成的语料也会包含噪声,生成一些质量不好的instance(17%的句子至少包含语法、语义、事件触发词相关的问题其中一种),无法像常规有监督的方式直接作为训练数据,以前的方法是用一些启发式规则过滤,但准确性不够好;这篇论文的方法是使用teacher-student多任务学习来解决这个问题。teacher model只在原始训练数据上训练,获得anchor knowledge,任务:EI(event identification)+ED,EI只关注是否触发了事件,不关注事件的类型。同样,student model也要做EI+ED任务,不同的是student model是在gpt-2生成的数据+原始数据上训练。gpt-2生成的那部分数据只有触发词位置信息,没有类别信息,所以就只能做EI任务,这也是为啥在ED任务上引入一个新的EI任务做多任务,不然新的数据没办法用了。另外,gpt-2生成的数据有噪声,所以student model需要和teacher model做Knowledge Consistency,具体地,在ED任务上,最小化student 和teacher 预测结果之间的KL散度,在EI任务上,student需要具备和teacher一样的区分原始数据和gpt-2生成数据之间的区别。那么问题变成了如何衡量数据之间的区别,这篇论文使用Optimal Transport方法来衡量,这个方法的作用大概是从一个概率分布转移到另外一个概率分布需要的代价。最后构建loss最小化student和teacher的optimal transport cost之差。使用student model作为最终ED inference的model。
LearnDA: Learnable Knowledge-Guided Data Augmentation for Event Causality Identification,任务是事件因果关系识别(event causality identification, ECI),解决的问题是ECI训练数据少 DL算法无法发挥优势,解决方法是使用task-related 数据增强,以往的数据增强方法是任务无关的,生成的instance质量不高,这篇论文的task-related 数据增强要求生成的instance满足 事件之间的causality以及标准的语法、事件相关的实体、能够表达causality的单词,后三者叫well-formedness。引入KB帮助完成causality条件,数据生成和ECI构成dual learning帮助完成well-formedness条件。从wordnet,verbnet和frameNet等知识库或数据集中抽取具有causal/non-causal关系的事件对。数据生成和ECI的模型对应generator 和identifier,generator根据输入的事件对以及causality,生成对应的句子,并生成一个semantic alignment reward(生成每个token的概率平均值,越大置信度越高),identifier根据输入的句子和事件对,判定事件是否有因果关系,并生成一个causality reward(identifier的分类结果,一个概率)。generator 和identifier交互优化,最大化各自reward。generator和identifier都是基于BERT的网络结构。generator的输入是事件对触发词以及事件涉及的实体,并在其中插入一定数目的mask token,BERT对mask token做预测。
Trigger is Not Sufficient: Exploiting Frame-aware Knowledge for Implicit Event Argument Extraction, 隐式事件参数抽取(Implicit event argument extraction, IEAE),通过构建intra-event argument interaction提升IEAE性能,IEAE任务的argument分布在多个句子中,同一事件argument之间的关联信息是重要的。该论文把IEAE任务构造成问答问题,输出是argument的text span起始和结束位置(同SQuAD任务),输入是context和问题,问题是由 事件类型、事件触发词、目标argument的role,以及当前事件除目标agrument以外的其他arguement信息构成,问题模板如下:

Event_Type是事件类型,Arg_Type是目标arguement在事件中的roles,argx和rolex是除目标argument以外的其他argument以及他们在事件中的roles。可以看到问题中包含了同一事件的其他argument信息,论文期望这种intra-event agrument interaction可以带来精度的提升。这里的问题是,inference阶段argx和rolex是不知道的,所以论文接着提出teacher-student蒸馏训练架构来解决。具体地,teacher model正常按照上述形式进行训练。student采用和teacher一样的模型结构,但是没有其他argument信息,通过构建loss,使得teacher和student的hidden state(只有context部分,因为问题部分的输入不一样)和预测概率分布尽可能的近似,进而让student在没有其他argument信息的情况下,也可以模拟teacher model的行为。蒸馏过程借鉴了课程理论(curriculum theory)的思想,训练的开始阶段,student可以和teacher一样,输入包含所有的其他argument信息,随着训练的进行逐渐减少输入到student的arguement信息数量(几个argument的信息),直到完全去掉其他argument的信息,学习难度从简单到容易,可以获得更好的蒸馏效果。teacher是显示的利用其他argument信息,student虽然没有这部分信息,但是通过蒸馏被迫从context中学习到了如何构建这些信息。另外还提出了使用多个teacher,每个teacher训练时输入的argument信息数量不同(全部、全部-1、没有其他argument信息),可以让studnet学习到不同角度的argument interaction方式,类似把一个复杂的interaction拆分开,逐个学习,会更容易。
Capturing Event Argument Interaction via A Bi-Directional Entity-Level Recurrent Decoder, EAE task 常见的两种提升精度的角度:inter-event/intra-event argument interaction,这篇论文就是从intra-event角度进行算法改进,将EAE任务做成Seq2Seq学习问题,输出是每个实体的roles/no role,这样做的好处是当前位置的预测结果依赖于已经预测出来的argument信息,引入了argument interaction信息,而且文中还加入了right-to-left解码过程,使得每个位置的前后argument 信息都可以利用起来。
Verb Knowledge Injection for Multilingual Event Processing, 引入动词知识,verbnet/framenet知识库中包含两个动词是否是同一类的信息(句法/语义相似程度),根据这个信息构建了一个非常简答的任务:输入是两个verb,输出是是否是同一类。模型的选择是BERT,但是在每个layer最后新加一个sublayer(MLP),称为verb knowledge adapter,在实际任务中的使用有两种形式:full fine-tuning / task adapter fine-tuning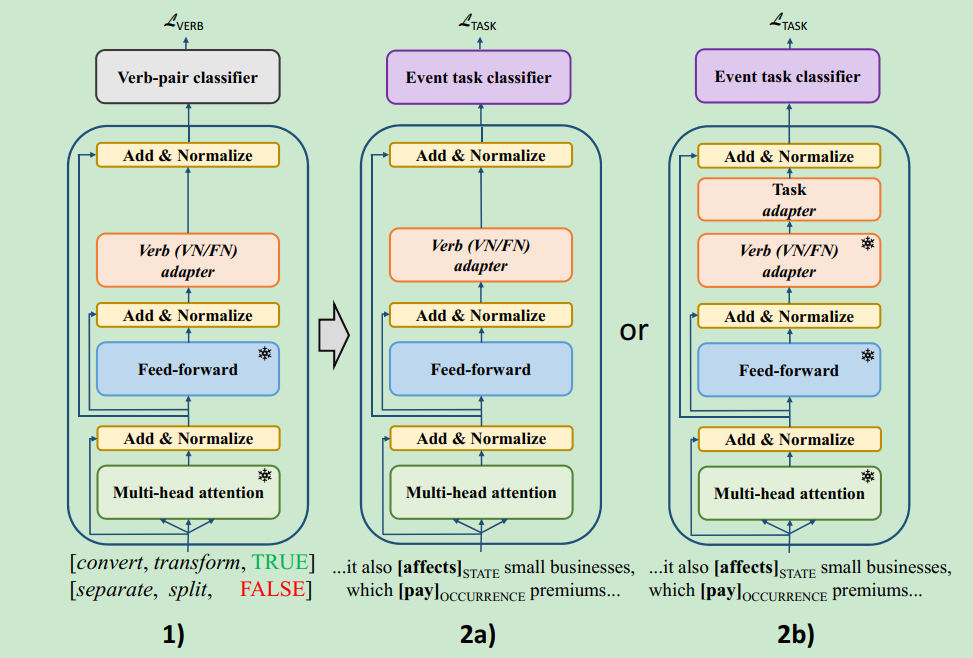
TEXT2EVENT Controllable Sequence-to-Structure Generation for end to end event extraction, 使用encoder-decoder网络结构end-to-end的做event extraction,输入时raw text,输出是结构化的事件,由于encoder-decoder结构一般是用来生成text而非结构化事件,所以要对事件进行线性化,即把结构化的信息铺开成token sequence:
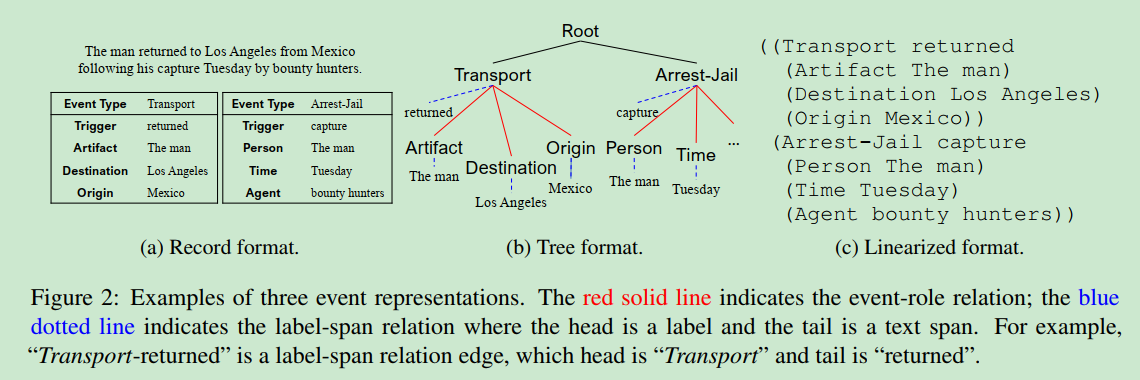
每个事件一个子树,根是事件类型,分支包括触发词以及事件的各种argument role,每个role一个节点,每个role节点分成对应的实体text span。上图中有两个事件,则有两个事件树,再引入一个root作为所有事件的根节点。对树进行深度优先遍历,并且插入()表示semantic,这样原始的结构化的事件,被线性化成了token sequence,event extraction转化成了text-2-text问题。这里的问题是输出的token sequence并没有语义,而且某些位置的解空间很小,比如事件类型和argument role,在event schema的标签集里预测就好。于是这篇论文对decode做了限制,引入了trie:
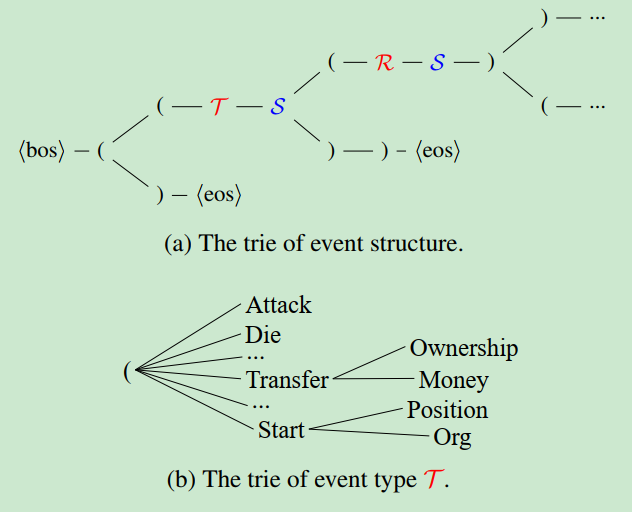
(a)是deocder预测模式的trie,最开始是"<bos> (",接下来要么是没有事件,生成“)”,要么开始生成第一个事件“(”, 于是这里可以构建词表{"(", ")"},二选一。假设预测结果是"(",表示接下来要开始生成事件了,也就是要预测事件类型T,event schema中的事件类型标签会构成一个sub trie(b),也有对应的每次预测的词表,event sub trie走完事件类型生成结束,开始生成触发词,触发词是输入raw text的span,也有对应的一个sub trie,直到sub trie走完,或者生成了“)",证明事件触发词预测结束。之后开始预测这个事件的argument,也是类似的过程。该论文用T5-large作为预训练模模型,借鉴课程学习理论,fine-tune的开始阶段,从sub structure开始训练:输入是raw text,输出是(label,text span),即(event type,trigger words)或者(argument role,argument words),这个阶段训练完,再开始完整的task训练。
