

python 面对post分页爬虫

分享一则对于网抓中面对post请求访问的页面或者在分页过程中需要post请求才可以访问的内容!
面的post请求的网址是不可以零参访问网址的,所以我们在网抓的过程中需要给请求传表单数据,下面看一下网页中post请求的网址:

post请求状态码和get请求的状态码一致,但是在参数中我们可以看到表单数据有很多的参数:
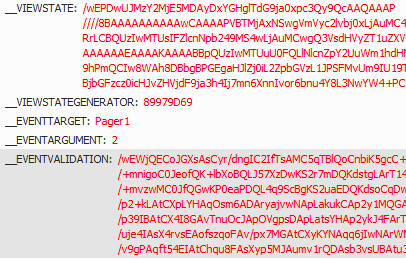
其中的__VIEWSTATE是必须要传的参数,而这个参数是在源码中能获取到的,这个__VIEWSTATE是asp.net中特有的,所以只有在访问asp.net的网站的时候这个参数是必须传的,其他的网站,只要有参数变化的表单数据就需要传到post请求中!
我们在转页的过程中会看到类似于这样的 表单,那后面的数字就是我们转页后的页码!所以我们的这个参数也要传,获取转页的页码的总数,同样可以在源码中获取,如果只显示了1234页,那就需要计算你需要的内容有多少个,每一页的内容个数,做一个取余算法就可以算出来了!
表单,那后面的数字就是我们转页后的页码!所以我们的这个参数也要传,获取转页的页码的总数,同样可以在源码中获取,如果只显示了1234页,那就需要计算你需要的内容有多少个,每一页的内容个数,做一个取余算法就可以算出来了!
现在定义一个post_data:
1 post_data={"__EVENTTARGET":"Pager1","__EVENTARGUMENT":page_num,"ddlManufacturer":"0","Pager1_input":str(page_num-1)}
这是我自定义的post参数,page_num代表着分页的页码。
__VIEWSTATE是在源码中,这里分享的是xpath方法:
1 a = doc.xpath('//input[@id="__VIEWSTATE"]') 2 if len(a) > 0: 3 post_data['__VIEWSTATE'] = a[0].get('value')
使用BeautifulSoup就是:
1 soup = BeautifulSoup(h,"html.parser") 2 a = soup.find('input',id='__VIEWSTATE') 3 if a: 4 post_data['__VIEWSTATE'] = a['value']
获取到重要的表单数据后,我们就只需要传参访问网页源码了!
1 r2 = requests.post(url,data=post_data,headers=headers,timeout=20) 2 ht2 = r2.content #这里就是访问的网页源码!
xpath的解析代码: doc2 = HTML.document_fromstring(网页源码)
网页的简单post请求就是这样来传递参数,访问的!我自己还有很多的学习资料分享在607021567qq群里面了!还有微信飞机大战的源代码分享!
Welcome to Python world! I have a contract in this world! How about you?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号