
十六、Kubernetes之网络组件
OS: root@harbor:~# cat /etc/issue Ubuntu 20.04.2 LTS \n \l root@harbor:~# uname -r 5.4.0-81-generic IP分配: 192.168.1.101 k8s-master etcd 192.168.1.102 k8s-node1 192.168.1.103 k8s-node2
1、容器网络通信模式
Host模式:
各容器共享宿主机的根网络名称空间,它们与所在宿主机使用同一个网络接口设备和网络协议栈,共享宿主机的网络,用户必须精心管理共享同一网络端口空间容器的应用与宿主机应用,以避免端口冲突。
Bridge模式:
Bridge模式对host模式进行了一定程度的改进,在该模式中,容器从一个或多个专用网络(地址池)中获取IP地址,并将该IP地址配置在自己的网络名称空间中的网络端口设备上。拥有独立、隔离的网络名称空间的各容器有自己独占的端口空间,而不必再担心各容器及宿主机间的端口冲突。
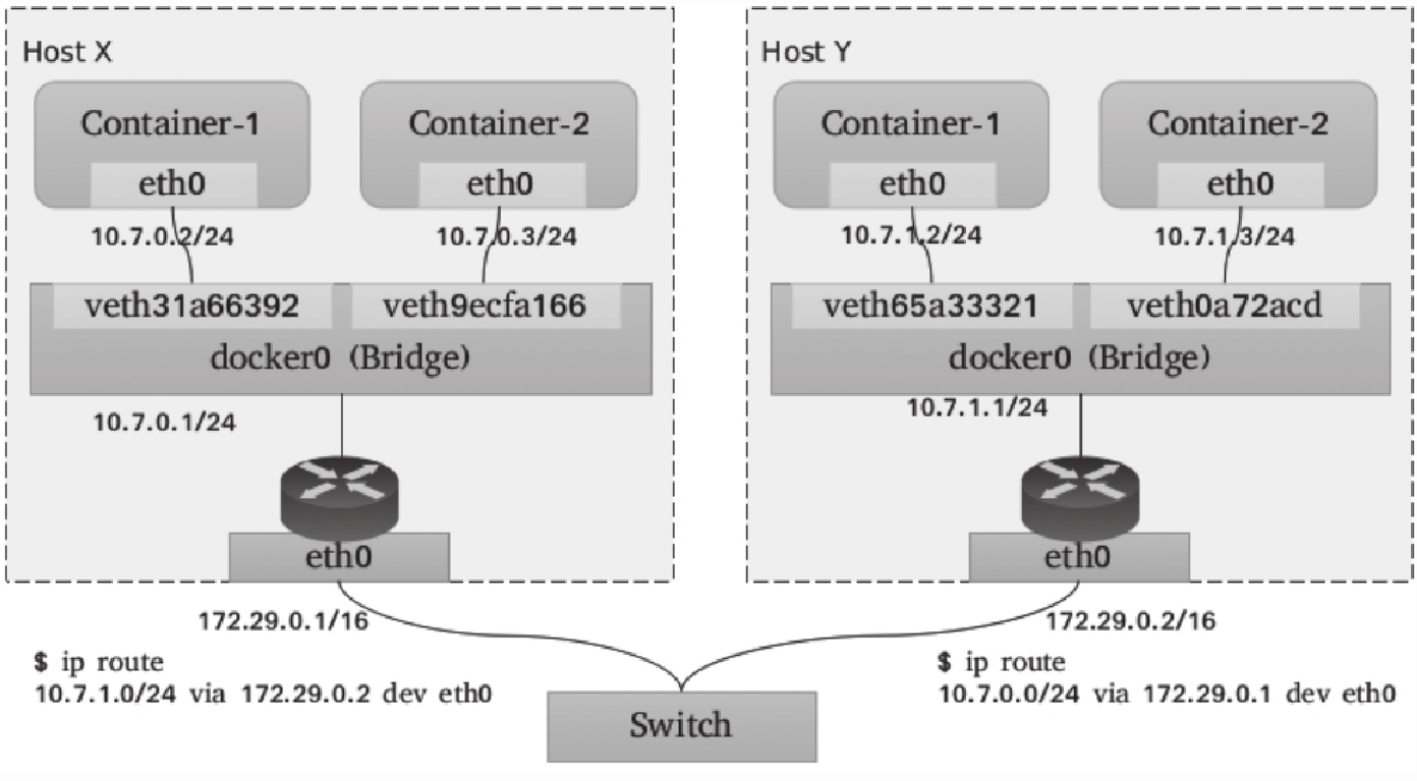
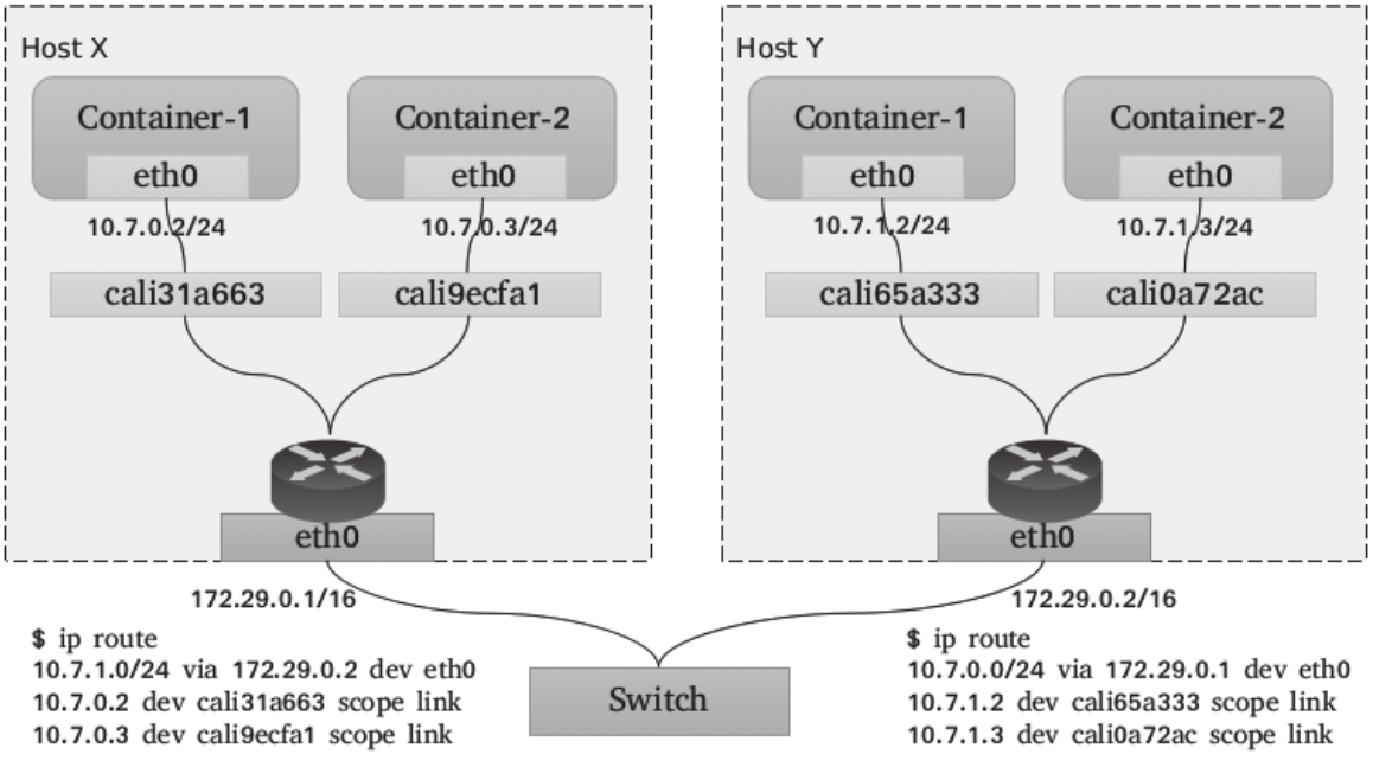
Bridge是指Linux内核支持的虚拟网桥设备,它模拟的是物理网桥设备,工作于数据链路层,根据习得的MAC地址表向设备端口转发数据帧。虚拟以太网接口设备对(veth pair)是连接虚拟网桥和容器的网络媒介:一端插入到容器的网络栈中,表现为通信接口(例如eth0等),另一端则于宿主机上关联虚拟网桥(docker0)并被降级为当前网桥的“从设备”,失去调用网络协议栈处理数据包的资格,从而表现为桥设备的一个端口。

Linux网桥提供的是宿主机内部的网络,同一主机上的各容器可基于网桥和ARP协议完成本地通信。而在宿主机上,网桥表现为一个网络接口并可拥有IP地址如上图中的docker0会在docker daemon进程启动后被自动配置172.17.0.1/16(为容器的默认网关)的地址。于是,由宿主机发出的网络包可通过此桥接口送往连接至同一个桥上的其他容器,如上图的Container-1或Container-2,这些容器通常需要由某种地址分配组件(IPAM)自动配置一个相关网络(例如72.17.0.0/16)中的IP地址。
容器跨宿主机的访问:
但此私有网络中的容器却无法直接与宿主机之外的其他主机或容器进行通信,通常作为请求方,这些容器需要由宿主机上的iptables借助SNAT机制实现报文转发,而作为服务方时,它们的服务需要宿主机借助于iptables的DNAT规则进行服务暴露。因而,总结起来,配置容器使用Bridge网络的步骤大体有如下几个:
1)若不存在,则需要先在宿主机上添加一个虚拟网桥;
2)为每个容器配置一个独占的网络名称空间;
3)生成一对虚拟以太网接口(如veth pair),将一端插入容器网络名称空间,一端关联至宿主机上的网桥;
4)为容器分配IP地址,并按需生成必要的NAT规则。
尽管Bridge模型下各容器使用独立且隔离的网络名称空间,且彼此间能够互连互通,但跨主机的容器间通信时,请求报文会首先由源宿主机进行一次SNAT(源地址转换)处理,而后由目标宿主机进行一次DNAT(目标地址转换)处理方可送到目标容器,如下图所示。这种复杂的NAT机制将会使得网络通信管理的复杂度随容器规模增呈成几何倍数上升,而且基于ipables实现的NAT规则,也限制了解决方案的规模和性能。

Docker Bridge创建过程总结:
1) 首先宿主机上创建一对虚拟网卡veth pair设备,veth设备总是成对出现的,组成了一个数据的通道,数据从一个设备进入,就会从另一个设备出来,veth设备常用来连接两个网络设备。 2) Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0,然后将另一端放在宿主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中,可以通过brctl show命令查看。 3) 从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。 4) 此时容器IP与宿主机能够通信,宿主机也可以访问容器中的IP地址,在Bridge模式下,连在同一网桥上的容器之间可以相互通信,同时容器也可以访问外网,但是其他物理机不能访问docker容器IP,需要通过NAT将容器IP的port映射为宿主机的IP和port。
1、实现同一个Pod内的不同容器的通信(localhost,同一个pod内的容器共用一个网络) 2、实现pod与pod同主机与跨主机的容器的容器通信 3、pod和服务之间的通信(nginx调用tomcat,通过service来实现) 4、pod与k8s之外的网络通信(pod内的容器调用外部的mysql,通过service来现实) 外部到pod(客户端的请求) pod到外部(相应报文)
pod中容器的通信
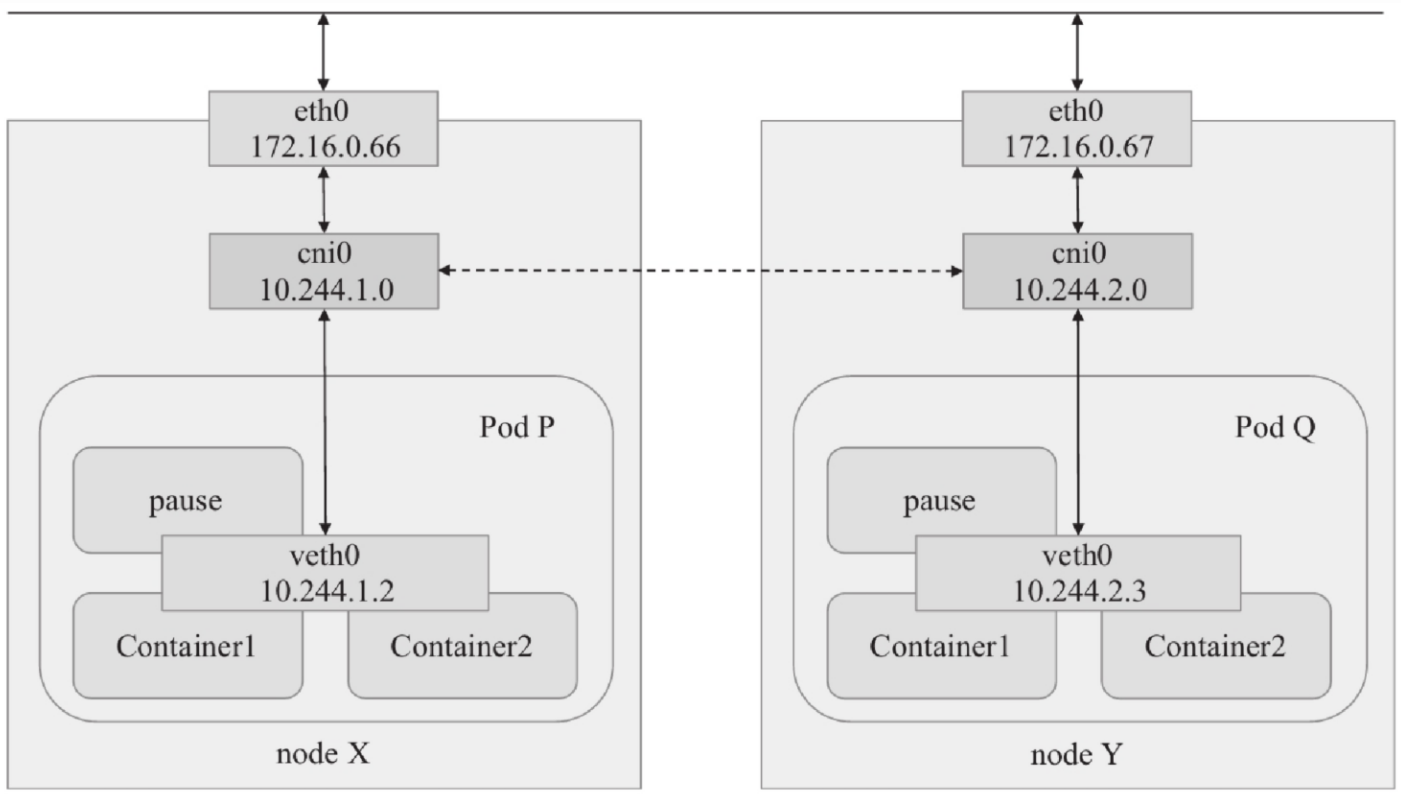
Pod是Kubernetes调度的原子单元,其内部的各容器必须运行在同一节点之上。一个Pod资源内的各容器共享同一网络名称空间,它通常由构建Pod对象的基础架构容器pause所提供。因而,同一个Pod内运行的多个容器通过lo接口即可在本地内核协议栈上完成交互,如上图(pod中容器的通信)中的Pod P内的Container1和Container2之间的通信,这类似于同一主机上的多个进程间的本地通信。
2.2 分布式pod间的通信
各Pod对象需要运行在同一个平面网络中,每个Pod对象拥有一个虚拟网络接口和集群全局唯一的地址,该IP地址可用于直接与其他Pod进行通信。另外,运行Pod的各节点也会通过桥接设备等持有此平面网络中的一个IP地址,如上图(pod中容器的通信)中的cni0接口,这意味着Node到Pod间的通信也可直接在此网络进行。因此,Pod间的通信或Pod到Node间的通信类似于同一IP网络中的主机间进行的通信。
2.3 Service与Pod间的通信
Service资源的专用网络也称为集群网络,需要在启动kube-apiserver时由--service-cluster-ip-range选项进行指定,例如默认的10.96.0.0/12,每个Service对象在此网络中拥有一个称为Cluster-IP的固定地址。管理员或用户对Service对象的创建或更改操作,会由API Server存储完成后触发各节点上的kube-proxy,并根据代理模式的不同将该Service对象定义为相应节点上的iptables规则或ipvs规则,Pod或节点客户端对Service对象的IP地址的访问请求将由这些iptables或ipvs规则进行调度和转发,从而完成Pod与Service之间的通信。
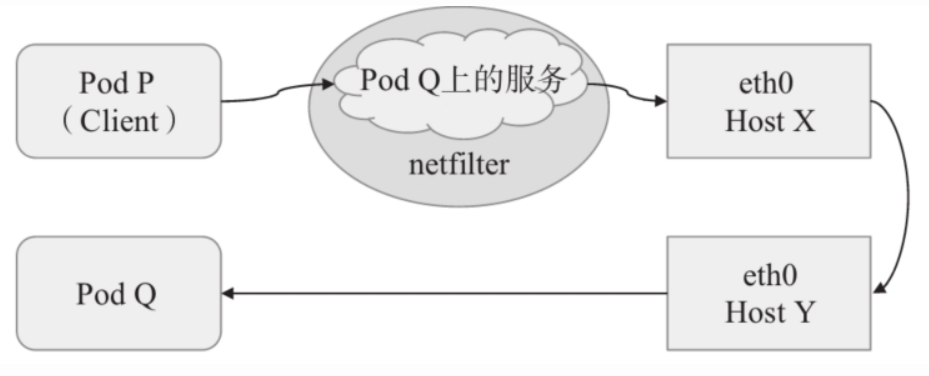
2.4 集群外部客户端与Pod对象的通信
入集群外部流量到达Pod对象有4种方式,有两种是基于本地节点的端口(nodePort)或根网络名称空间(hostNetwork),另外两种则是基于工作在集群级别的NodePort或LoadBalancer类型的Service对象。不过,即便是四层代理的模式也要经由两级转发才能到达目标Pod资源:请求流量首先到达外部负载均衡器,由其调度至某个工作节点之上,而后再由工作节点的netfilter(kube-proxy)组件上的规则(iptables或ipvs)调度至某个目标Pod对象。
3、CNI网络插件基础
集群内的Pod间通信,即便通过Service进行“代理”和“调度”,但绝大部分都无须使用NAT,而是Pod间的直接通信。由此可见,上面的4种通信模型中,仅“分布式Pod间通信”是负责解决跨节点间容器通信的核心所在,但Kubernetes从v1.0之前的版本起就把这个问题通过kubenet插件API开放给了社区,把网络栈的管理从容器运行时中分离出来,这种抽象有助于将容器管理和网络管理分开,也为不同的组织独立解决容器编排和容器网络编排的问题提供了空间。任何遵循该API开发的容器网络编排插件都可以同Kubernetes系统一起协同工作,这其中以CoreOS维护的Flannel项目为最具代表性。 kubenet是一个非常基础、简单的网络插件,它本身并未实现任何跨节点网络和网络策略一类更高级的功能,且仅适用于Linux系统,于是,Kubernetes试图寻求一个更开放的网络插件接口标准来替代它。分别由Docker与CoreOS设计的CNM(Container Network Model)和CNI是两个主流的竞争模型,但CNM在设计上做了很多与Kubernetes不兼容的假设,而CNI却有着与Kubernetes非常一致的设计哲学,它远比CNM简单,不需要守护进程,并且能够跨多个容器运行时平台。于是,CNM因“专为Docker容器引擎设计且很难分离”而落选,而CNI就成了目前Kubernetes系统上标准的网络插件接口规范。目前,绝大多数为Kubernetes解决Pod网络通信问题的插件都是遵循CNI规范的实现。
CNI是容器引擎与遵循该规范网络插件的中间层,专用于为容器配置网络子系统,目前由RKT、Docker、Kubernetes、OpenShift和Mesos等相关的容器运行时环境所运行。 通常,遵循CNI规范的网络插件是一个可执行程序文件,它们可由容器编排系统(例如Kubernetes等)调用,负责向容器的网络名称空间插入一个网络接口并在宿主机上执行必要的任务以完成虚拟网络配置,因而通常被称为网络管理插件,即NetPlugin。随后,NetPlugin还需要借助IPAM插件为容器的网络接口分配IP地址,这意味着CNI允许将核心网络管理功能与IP地址分配等功能相分离,并通过插件组合的方式堆叠出一个完整的解决方案。简单来说,目前的CNI规范主要由NetPlugin和IPAM两个插件API组成。
CNI插件API

为Pod配置网络接口是NetPlugin的核心功能之一,但不同的容器虚拟化网络解决方案中,为Pod的网络名称空间创建虚拟接口设备的方式也会有所不同,目前,较为注流的实现方式有veth(虚拟以太网)设备、多路复用及硬件交换3种.

基于VXLAN Overlay网络的虚拟容器网络中,NetPlugin会使用虚拟以太网内核模块为每个Pod创建一对虚拟网卡;基于MAC VLAN/IP VLAN Underlay网络的虚拟容器网络中,NetPlugin会基于多路复用模式中的MAC VLAN/IP VLAN内核模块为每个Pod创建虚拟网络接口设备;而基于IP报文路由技术的Underlay网络中,各Pod接口设备通常也是借助veth设备完成。 相比较来说,IPAM插件的功能则要简单得多,目前可用的实现方案中,host-local从本地主机可用的地址空间范围中分配IP地址,它没有地址租约,属于静态分配机制;而dhcp插件则需要一个特殊的客户端守护进程(通常是dhcp插件的子组件)运行在宿主机之上,它充当本地主机上各容器中的DHCP客户端与网络中的DHCP服务器之间的代理,并适当地续定租约。 Kubernetes借助CNI插件体系来组合需要的网络插件完成容器网络编排功能。每次初始倾化或删除Pod对象时,kubelet都会调用默认的CNI插件创建一个虚拟设备接口附加到相关的底层网络,为其设置IP地址、路由信息并将其映射到Pod对象的网络名称空间。具体过程是,kubelet首先在默认的/etc/cni/net.d/目录中查找JSON格式的CNI配置文件,接着基于该配置文件中各插件的type属性到/opt/cni/bin/中查找相关的插件二进制文件,由该二进制程序基于提供的配置信息完成相应的操作。 kubelet基于包含命令参数CNI_ARGS、CNI_COMMAND、CNI_IFNAME、CNI_NETNS、CNI_CONTAINERID、CNI_PATH的环境变量调用CNI插件,而被调用的插件同样使用JSON格式的文本信息进行响应,描述操作结果和状态。Pod对象的名称和名称空间将作为CNI_ARGS变量的一部分进行传递(例如K8S_POD_NAMESPACE=default; K8S_POD_NAME=myapp-6d9f48c5d9-n77qp;)。它可以定义每个Pod对象或Pod网络名称空间的网络配置(例如,将每个网络名称空间放在不同的子网中)。
4、Overlay网络模型
叠加网络或覆盖网络,在物理网络基础上叠加实现新的虚拟网络,即可使网络中的容器可以相互通信

Vxlan:Vxlan全称是Visual eXtensible Local Area Network(虚拟扩展本地局域网),主要有cisco推出,vxlan是一个VLAN扩展协议,是由IEEE定义的NVO3(network virtualization over 3)标准技术之一,VXLAN的特点是将L2的以太网帧封装到UDP报文(即L2 Over L4)中,并在L3网络中传输,即使用MAC in UDP的方法对报文进行重新封装,VXLAN本质上是一种overlay的隧道封装技术,它将L2的以太网帧封装成L4的UDP数据报,然后在L3的网络中传输,效果就像L2的以太网帧在一个广播域中传输一样,实际上L2的以太网帧跨越了L3网络传输,但是却不受L3的网络限制,vxlan采用24位表示vlan ID号,因此可以支持2^24=16777216个vlan,其可扩展性比vlan强大很多,可以支持大规模数据中心的网络需求

VTEP(VXLAN Tunnel Endpoint vxlan 隧道端点),VTEP是VXLAN网络的边缘设备,是VXLAN隧道的起点和终点,VXLAN对用户原始数据帧的封装和解封装均在VTEP上进行,用于VXLAN报文的封装和解封装,VTEP与物理网络相连,分配的地址为物理网IP地址,VXLAN报文中源IP地址为本节点的VTEP地址,VXLAN报文中目的IP地址为对端节点的VTEP地址,一对VTEP地址对应着一个VXLAN隧道,服务器上的虚拟交换机(隧道 flannel.1 就是VTEP),比如一个虚拟机网络中的多个vxlan就需要多个VTEP对不同网络的报文进行封装与解封装。
VNI(VXLAN Netowrk Identifier):VXLAN网络标识VNI类似于VLAN ID,用于区分VXLAN段,不同VXLAN段的虚拟机不能直接连接二层相互通信,一个VNI表示一个租户,即多个终端用户属于同一个VNI,也表示一个租户
5、Underlay网络模型
Underlay网络就是传统IT基础设施网络,由交换机和路由器等设备组成,借助以太网协议、路由协议和VLAN协议等驱动,它还是Overlay网络的底层网络,为Overlay网络提供数据通信服务。容器网络中的Underlay网络是指借助驱动程序将宿主机的底层网络接口直接暴露给容器使用的一种网络构建技术,较为常见的解决方案有MAC VLAN、IP VLAN和直接路由等。
5.1 MAC VLAN
基于目标mac 地址通信,不可夸局域网通信,通常是由交换机实现报文转发。
MAC VLAN支持在同一个以太网接口上虚拟出多个网络接口,每个虚拟接口都拥有唯一的MAC地址,并可按需配置IP地址。通常这类虚拟接口被称作子接口,但在MAC VLAN中更常用上层或下层接口来表述。与Bridge模式相比,MAC VLAN不再依赖虚拟网桥、NAT和端口映射,它允许容器以虚拟接口方式直接连接物理接口。下图给出了Bridge与MAC VLAN网络对比示意图。
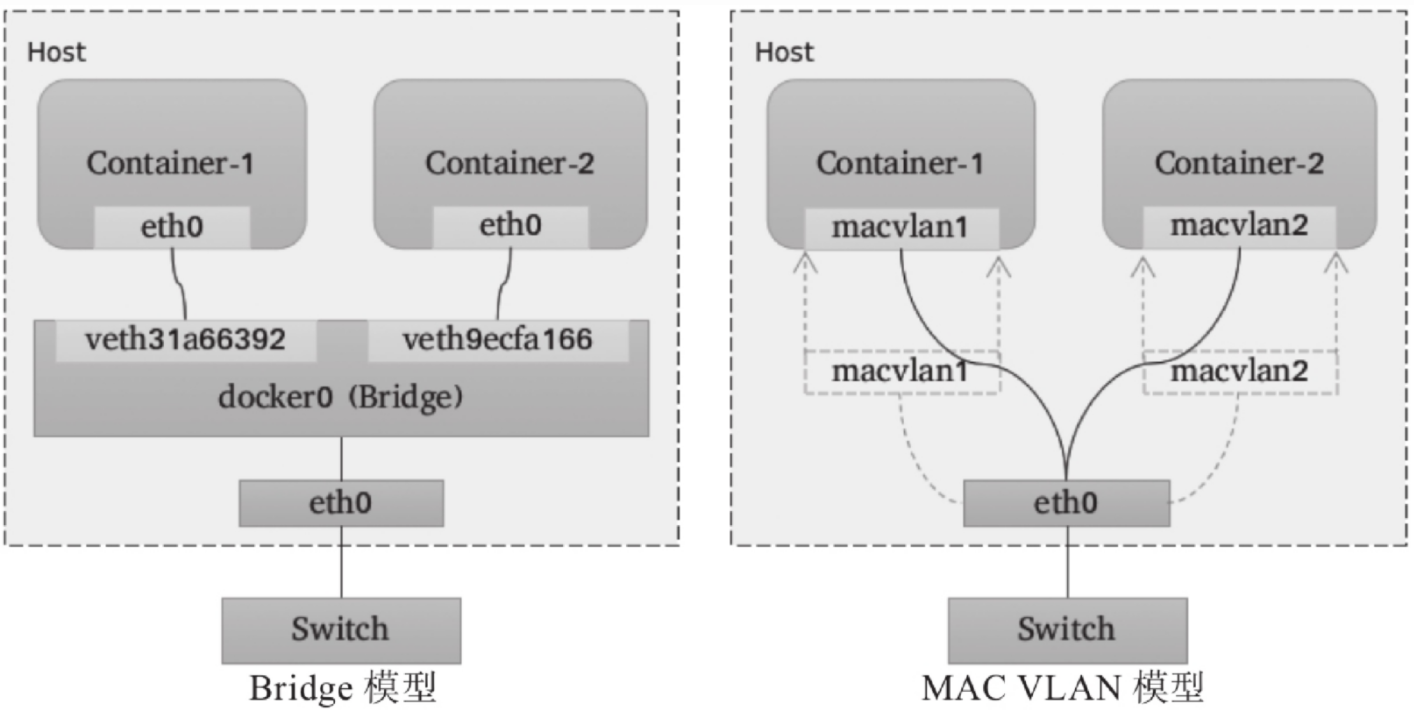
简单来说:同一父接口下的子接口之间彼此隔离,不能通信,及时通过外部交换机转发也不行
▪VPEA:允许构建在同一物理接口上的多个MAC VLAN实例(容器接口)彼此间的通信,但需要外部交换机启用发夹模式,或者存在报文转发功能的路由器设备
简单来说:vepa 模式下,子接口之间的通信流量需要导到外部支持802.1Qbg/VPEA 功能的交换机上(可以是物理的或者虚拟的), 经由外部交换机转发,再绕回来
▪Bridge:将物理接口配置为网桥,从而允许同一物理接口上的多个MAC VLAN实例基于此网桥直接通信,而无须依赖外部的物理交换机来交换报文;此为最常用的模式,甚至还是Docker容器唯一支持的模式
简单来说:bridge 模式下,模拟的是Linux bridge 的功能,但比bridge 要好的一点是每个接口的MAC 地址是已知的,不用学习,所以这种模式下,子接口之间就是直接可以通信的
▪Passthru:允许其中一个MAC VLAN实例直接连接物理接口
简单来说:passthru 模式,只允许单个子接口连接父接口
▪source mode: 这种模式,只接收源mac 为指定的mac 地址的报文
由上述工作模式可知,除了Passthru模式外的容器流量将被MAC VLAN过滤而无法与底层主机通信,从而将主机与其运行的容器完全隔离,其隔离级别甚至高于网桥式网络模型,这对于有多租户需求的场景尤为有用。由于各实例都有专用的MAC地址,因此MAC VLAN允许传输广播和多播流量,但它要求物理接口工作于混杂模式,考虑到很多公有云环境中并不允许使用混杂模式,这意味着MAC VLAN更适用于本地网络环境。 需要注意的是,MAC VLAN为每个容器使用一个唯一的MAC地址,这可能会导致具有安全策略以防止MAC欺骗的交换机出现问题,因为这类交换机的每个接口只允许连接一个MAC地址。另外,有些物理网卡存在可支撑的MAC地址数量上限
5.2 IP VLAN
IP VLAN类似于MAC VLAN,它同样创建新的虚拟网络接口并为每个接口分配唯一的IP地址,不同之处在于,每个虚拟接口将共享使用物理接口的MAC地址,从而不再违反防止MAC欺骗的交换机的安全策略,且不要求在物理接口上启用混杂模式,如下图:

IP VLAN有L2和L3两种模型,其中IP VLAN L2的工作模式类似于MAC VLAN Bridge模式,上层接口(物理接口)被用作网桥或交换机,负责为下层接口交换报文;而IP VLAN L3模式中,上层接口扮演路由器的角色,负责为各下层接口路由报文,如下图所示。
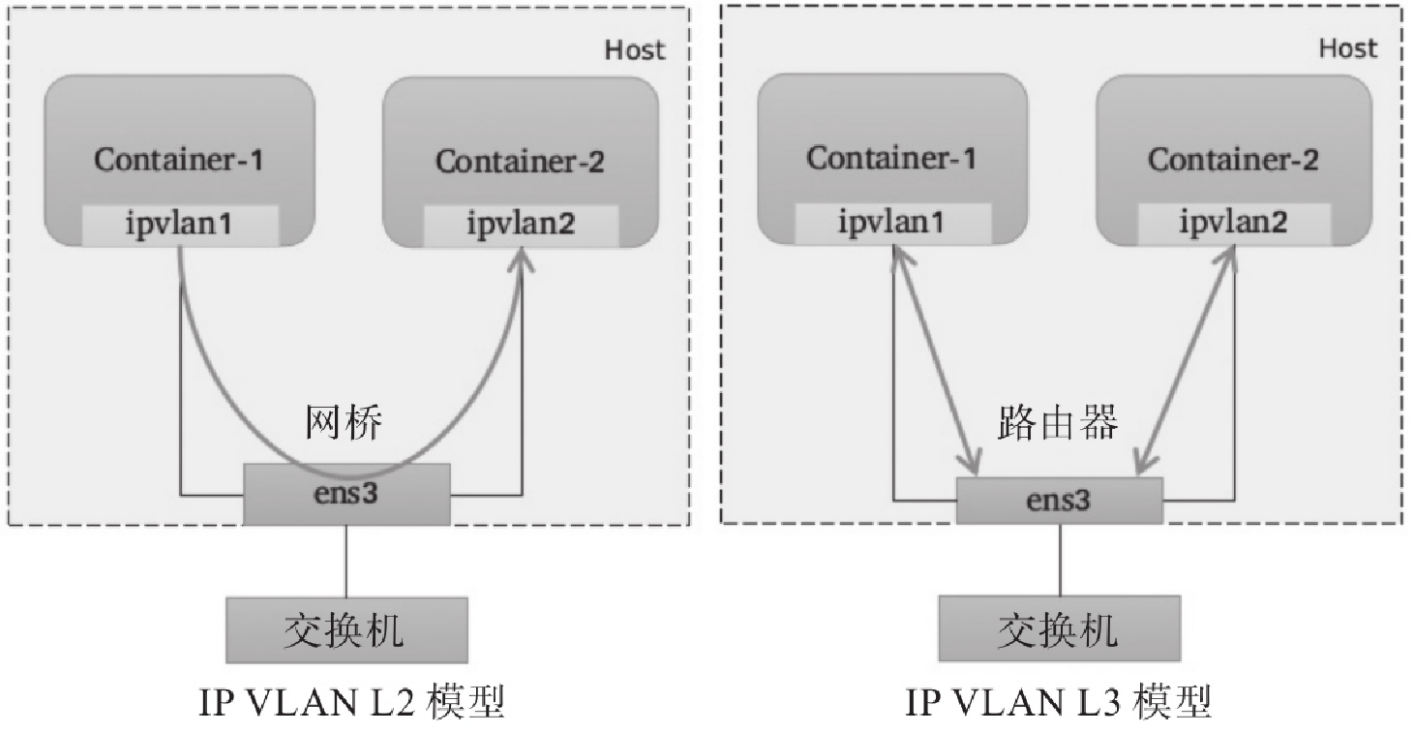
IP VLAN L2模型与MAC VLAN Bridge模型都支持ARP协议和广播流量,它们拥有直接接入网桥设备的网络接口,能够通过802.1d数据包进行泛洪和MAC地址学习。但IP VLAN L3模式下,网络栈在容器内处理,不支持多播或广播流量,从这个意义上讲,它的运行模式与路由器的报文处理机制相同。 虽然支持多种网络模型,但MAC VLAN和IP VLAN不能同时在同一物理接口上使用。Linux内核文档中强调,MAC VLAN和IP VLAN具有较高的相似度,因此,通常仅在必须使用IP VLAN的场景中才不使用MAC VLAN。一般说来,强依赖于IP VLAN的场景有如下几个: ▪Linux主机连接到的外部交换机或路由器启用了防止MAC地址欺骗的安全策略; ▪虚拟接口的需求数量超出物理接口能够支撑的容量上限,并且将接口置于混杂模式会给性能带来较大的负面影响; ▪将虚拟接口放入不受信任的网络名称空间中可能会导致恶意的滥用。 需要注意的是,Linux内核自4.2版本后才支持IP VLAN网络驱动,且在Linux主机上使用ip link命令创建的802.1q配置接口不具有持久性,因此需依赖管理员通过网络启动脚本保持配置。
5.3 直接路由
“直接路由”模型放弃了跨主机容器在L2的连通性,而专注于通过路由协议提供容器在L3的通信方案。这种解决方案因为更易于集成到现在的数据中心的基础设施之上,便捷地连接容器和主机,并在报文过滤和隔离方面有着更好的扩展能力及更精细的控制模型,因而成为容器化网络较为流行的解决方案之一。 一个常用的直接路由解决方案如下图所示,每个主机上的各容器在二层通过网桥连通,网关指向当前主机上的网桥接口地址。跨主机的容器间通信,需要依据主机上的路由表指示完成报文路由,因此每个主机的物理接口地址都有可能成为另一个主机路由报文中的“下一跳”,这就要求各主机的物理接口必须位于同一个L2网络中。
在较大规模的主机集群中,问题的关键是如何更好地为每个主机维护路由表信息。常见的解决方案有:
①Flannel host-gw使用存储总线etcd和工作在每个节点上的flanneld进程动态维护路由;
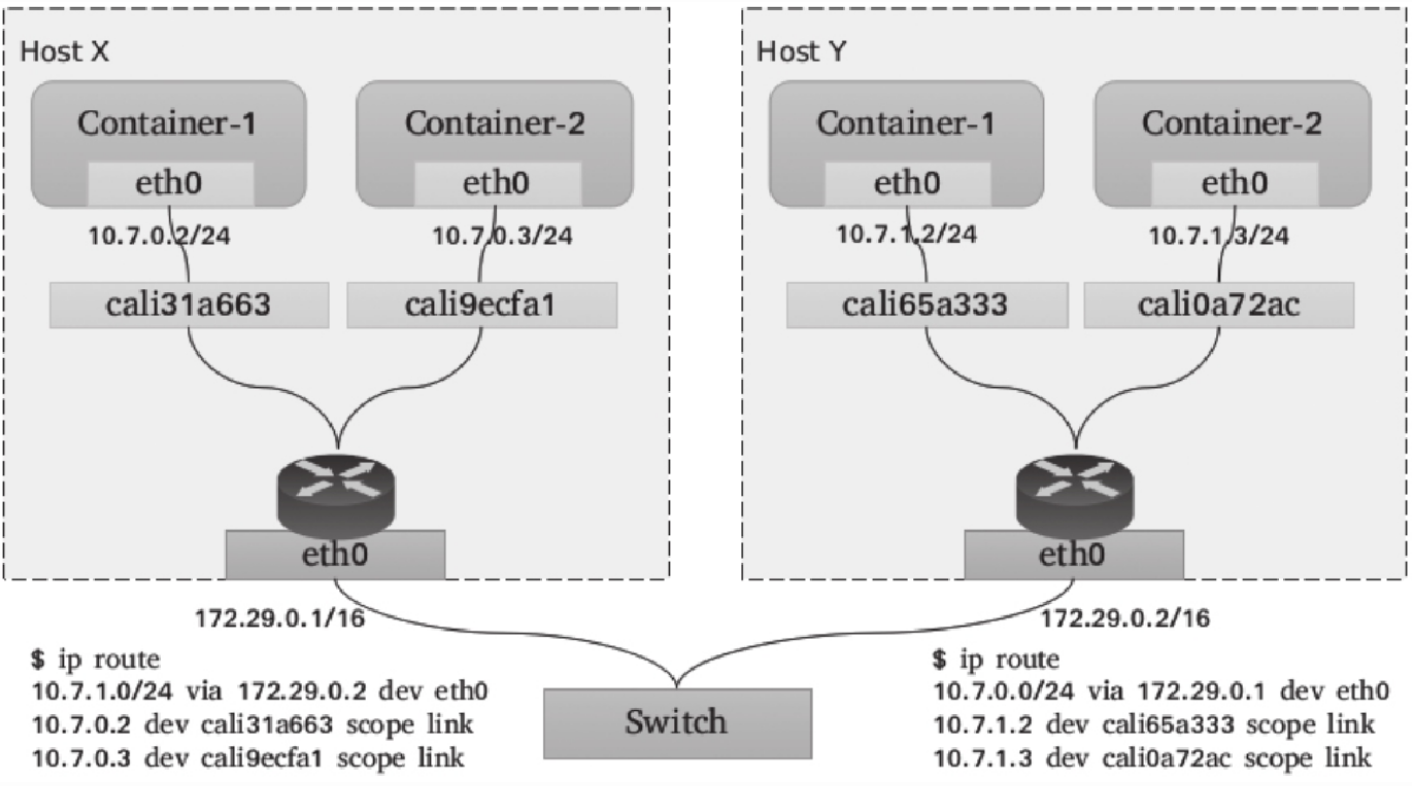
②Calico使用BGP(Border Gateway Protocol)协议在主机集群中自动分发和学习路由信息。与Flannel不同的是,Calico并不会为容器在主机上使用网桥,而是仅为每个容器生成一对veth设备,留在主机上的那一端会在主机上生成目标地址,作为当前容器的路由条目,如下图所示。
显然,较Overlay来说,无论是MAC VLAN、IP VLAN还是直接路由机制的Underlay网络模型的实现,它们因无须额外的报文开销而通常有着更好的性能表现,但对底层网络有着更多的限制条件。
6、CNI插件与选型
CNI规范负责连接容器管理系统和网络插件两类组件,它们之间通过JSON格式的文件进行通信,以完成容器网络管理。具体的管理操作均由插件来实现,包括创建容器netns(网络名称空间)、关联网络接口到对应的netns,以及给网络接口分配IP等。CNI的基本思想是为容器运行时环境在创建容器时,先创建好netns,然后调用CNI插件为这个netns配置网络,而后启动容器内的进程。 CNI本身只是规范,付诸生产还需要有特定的实现。如前所述,目前CNI提供的插件分为main、ipam和meta,各类别中都有不少内置实现。另外,可用的第三方实现的CNI插件也有数十种之多,它们多数都是用于提供NetPlugin功能,隶属main插件类型,主要用于配置容器接口和容器网络,这其中,也有不少实现能够支持Kubernetes的网络策略。下面是较为流行的部分网络插件项目。
▪Flannel:由CoreOS提供的CNI网络插件,也是最简单、最受欢迎的网络插件;它使用VXLAN或UDP协议封装IP报文来创建Overlay网络,并借助etcd维护网络的分配信息,同一节点上的Pod间通信可基于本地虚拟网桥(cni0)进行,而跨节点的Pod间通信则要由flanneld守护进程封装隧道协议报文后,通过查询etcd路由到目的地;Flannel也支持host-gw路由模型。
▪Calico:同Flannel一样广为流行的CNI网络插件,以灵活、良好的性能和网络策略所著称。Calico是路由型CNI网络插件,它在每台机器上运行一个vRouter,并基于BGP路由协议在节点之间路由数据包。Calico支持网络策略,它借助iptables实现访问控制功能。另外,Calico也支持IPIP型的Overlay网络。
▪Canal:由Flannel和Calico联合发布的一款统一网络插件,它试图将二者的功能集成在一起,由前者提供CNI网络插件,由后者提供网络策略。
▪WeaveNet:由Weaveworks提供的CNI网络插件,支持网络策略。WeaveNet需要在每个节点上部署vRouter路由组件以构建起一个网格化的TCP连接,并通过Gossip协议来同步控制信息。在数据平面上,WeaveNet通过UDP封装实现L2隧道报文,报文封装支持两种模式:一种是运行在用户空间的sleeve(套筒)模式,另一种是运行在内核空间的fastpath(快速路径)模式,当网络拓扑不适合fastpath模式时,Weave将自动切换至sleeve模式。
▪Multus CNI:多CNI插件,实现了CNI规范的所有参考类插件(例如Flannel、MAC VLAN、IPVLAN和DHCP等)和第三方插件(例如Calico、Weave和Contiv等),也支持Kubernetes中的SR-IOV、DPDK、OVS-DPDK和VPP工作负载,以及Kubernetes中的云原生应用程序和基于NFV的应用程序,是需要为Pod创建多网络接口时的常用选择。
▪Antrea:一款致力于成为Kubernetes原生网络解决方案的CNI网络插件,它使用OpenvSwitch构建数据平面,基于Overlay网络模型完成Pod间的报文交换,支持网络策略,支持使用IPSec ESP加密GRE隧道流量。
▪DAMM:由诺基亚发布的电信级的CNI网络插件,支持具有高级功能的IP VLAN模式,内置IPAM模块,可管理多个集群范围内的不连续三层网络;支持通过CNI meta插件将网络管理功能委派给任何其他网络插件。
▪kube-router:kube-router是Kubernetes网络的一体化解决方案,它可取代kube-proxy实现基于ipvs的Service,能为Pod提供网络,支持网络策略以及拥有完美兼容BGP协议的高级特性。
尽管人们倾向于把Overlay网络作为解决跨主机容器网络的主要解决方案,但可用的容器网络插件在功能和类型上差别巨大:某些解决方案与容器引擎无关,而也有些解决方案作用后,容易被特定的供应商或引擎锁定;有些专注于简单易用,而另一些的主要目标则是更丰富的功能特性等,至于哪一个解决方案更适用,通常取决于应用程序自身的需求,例如性能需求、负载位置编排机制等。通常来说,选择网络插件时应该基于底层系统环境限制、容器网络的功能需求和性能需求3个重要的评估标准来衡量插件的适用性。
▪底层系统环境限制:公有云环境多有自己专有的实现,例如Google GCE、Azure CNI、AWS VPC CNI和Aliyun Terway等,它们通常是相应环境上较佳的选择。若虚拟化环境限制较多,除Overlay网络模型别无选择,则可用的方案有Flannel VXLAN、Calico IPIP、Weave和Antrea等。物理机环境几乎支持任何类型的网络插件,此时一般应该选择性能较好的Calico BGP、Flannel host-gw或DAMM IP VLAN等。
▪容器网络功能需求:支持NetworkPolicy的解决方案以Calico、WeaveNet和Antrea为代表,而且后两个支持节点到节点间的通信加密。而大量Pod需要与集群外部资源互联互通时,应该选择Underlay网络模型一类的解决方案。
▪容器网络性能需求:Overlay网络中的协议报文有隧道开销,性能略差,而Underlay网络则几乎不存这方面的问题,但Overlay或Underlay路由模型的网络插件支持较快的Pod创建速度,而Underlay模型中的IP VLAN或MAC VLAN模式则较慢。
7、VXLAN通信过程
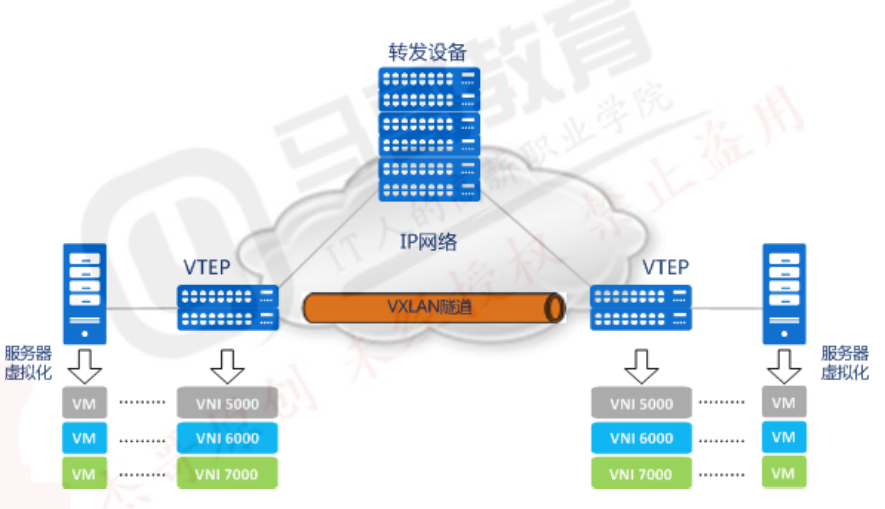
1.VM A发送L2帧与VM 请求与 VM B通信 2.源宿主机VTEP添加或者封装VXLAN、UDP及IP头部报文 3.网络层设备将封装后的报文通过标准的报文在三层网络进行转发到目标主机 4.目标宿主机VTEP删除或解封装VXLAN、UDP及IP头部 5.将原始L2帧发送到目标VM
二、Flannel网络插件
官网:https://cores.com/flannel/docs/latest
文档:https://coreos.com/flannel/docs/latest/kubernetes.html
Flannel是用于解决容器跨节点通信问题的解决方案,兼容CNI插件API,支持Kubernetes、OpenShift、Cloud Foundry、Mesos、Amazon ECS、Singularity和OpenSVC等平台。它使用“虚拟网桥和veth设备”的方式为Pod创建虚拟网络接口,通过可配置的“后端”定义Pod间的通信网络,支持基于VXLAN和VXLAN+DirectRouting的Overlay网络(UDP模式现已不再支持),以及基于三层路由的Underlay网络。在IP地址分配方面,它将预留的一个专用网络(默认为10.244.0.0/16,自定义为172.20.0.0/16)切分成多个子网后作为每个节点的Pod CIDR,而后由节点以IPAM插件的host-local形式进行地址分配,并将子网分配信息保存于etcd之中。
可以在/run/flannel/subnet.env中查看子网的分配
#k8s-master1 root@k8s-master:~# cat /run/flannel/subnet.env FLANNEL_NETWORK=172.20.0.0/16 #所在网段 FLANNEL_SUBNET=172.20.0.1/24 #分配给容器的IP网段 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true #k8s-node1(分配的172.20.2.0/24网段) root@k8s-node1:~# cat /run/flannel/subnet.env FLANNEL_NETWORK=172.20.0.0/16 #所在网段 FLANNEL_SUBNET=172.20.2.1/24 #分配给容器的IP网段 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true #k8s-node2(分配的172.20.1.0/24网段) root@k8s-node2:~# cat /run/flannel/subnet.env FLANNEL_NETWORK=172.20.0.0/16 FLANNEL_SUBNET=172.20.1.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true
Flannel在每个主机上运行一个名为flanneld的二进制代理程序,它负责从预留的网络中按照指定或默认的掩码长度为当前节点申请分配一个子网,并将网络配置、已分配的子网和辅助数据(例如主机的公网IP等)存储在Kubernetes API或etcd之中。
root@k8s-deploy:~# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-7659f568f5-fz6t2 1/1 Running 2 2d6h 172.20.2.4 192.168.1.102 <none> <none>
kube-flannel-ds-amd64-498cr 1/1 Running 2 2d6h 192.168.1.103 192.168.1.103 <none> <none>
kube-flannel-ds-amd64-78kw5 1/1 Running 1 2d6h 192.168.1.101 192.168.1.101 <none> <none>
kube-flannel-ds-amd64-cvqr7 1/1 Running 2 2d6h 192.168.1.102 192.168.1.102 <none> <none>
Flannel使用称为后端的容器网络机制转发跨节点的Pod报文
▪vxlan:使用Linux内核中的vxlan模块封装隧道报文,以Overlay网络模型支持跨节点的Pod间互联互通;同时,该后端类型支持直接路由模式,在该模式下,位于同一二层网络内节点之上的Pod间通信可通过路由模式直接发送,而跨网络的节点之上的Pod间通信仍要使用VXLAN隧道协议转发;因而,VXLAN隶属于Overlay网络模型,或混合网络模型;vxlan后端模式中,flanneld监听UDP的8472端口发送的封装数据包。 ▪host-gw:即Host GateWay,它类似于VXLAN中的直接路由模式,但不支持跨网络的节点,因此这种方式强制要求各节点本身必须在同一个二层网络中,不太适用于较大的网络规模;host-gw有着较好的转发性能,且易于设定,推荐对报文转发性能要求较高的场景使用。 ▪udp:使用常规UDP报文封装完成隧道转发,性能较前两种方式低很多,它仅在不支持前两种后端的环境中使用;UDP后端模式中,flanneld监听UDP的8285端口发送的封装报文,现在已不再支持udp模式。
kubernetes中会定义一个名为kube-flannel-cfg的configmaps,它的值是一个JSON格式的字典数据结构,它可以使用的键包含以下几个。
root@k8s-deploy:~# kubectl get configmaps kube-flannel-cfg -n kube-system NAME DATA AGE kube-flannel-cfg 2 2d6h root@k8s-deploy:~# kubectl describe configmaps kube-flannel-cfg -n kube-system Name: kube-flannel-cfg Namespace: kube-system Labels: app=flannel tier=node Annotations: <none> Data ==== cni-conf.json: ---- { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: ---- { "Network": "172.20.0.0/16", "Backend": { "Type": "vxlan" } } Events: <none> #1)Network:Flannel在全局使用CIDR格式的IPv4网络,字符串格式,此为必选键,余下的均为可选。 #2)SubnetLen:为全局使用的IPv4网络基于多少位的掩码切割供各节点使用的子网,在全局网络的掩码小于24(例如16)时默认为24位。 #3)SubnetMin:分配给节点使用的起始子网,默认为切分完成后的第一个子网;字符串格式。 #4)SubnetMax:分配给节点使用的最大子网,默认为切分完成后的最大一个子网;字符串格式。 #5)Backend:Flannel要使用的后端类型,以及后端相关的配置,字典格式;不同的后端通常会有专用的配置参数。
Flannel预留使用的网络为默认的10.244.0.0/16,我们自定义的172.20.0.0/16,默认使用24位长度的子网掩码为各节点分配切分的子网,因而,它将有172.20.0.0/24~ 172.20.255.0/24范围内的256个子网可用,每个节点最多支持为254个Pod对象各分配一个IP地址。它使用的后端是VXLAN类型,flanneld将监听UDP的8472端口。
root@k8s-master0:~# netstat -tunlp|grep 8472 udp 0 0 0.0.0.0:8472 0.0.0.0:* - root@k8s-node1:~# netstat -tunlp|grep 8472 udp 0 0 0.0.0.0:8472 0.0.0.0:*
1、vxlan
Flannel会在集群中每个运行flanneld的节点之上创建一个名为flannel.1的虚拟网桥作为本节点隧道出入口的VTEP设备,其中的1表示VNI,因而所有节点上的VTEP均属于同一VXLAN,或者属于同一个大二层域(Bridge-Daemon),它们依赖于二层网关进行通信。Flannel采用了分布式的网关模型,它把每个节点都视为到达该节点Pod子网的二层网关,相应的路由信息由flanneld自动生成。
root@k8s-node1:~# brctl show bridge name bridge id STP enabled interfaces cni0 8000.6a27d0d1f4d3 no veth1ebbd6d3 docker0 8000.0242c905c787 no root@k8s-node1:~# ip route show default via 192.168.1.1 dev eth0 proto static 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown 172.20.0.0/24 via 172.20.0.0 dev flannel.1 onlink 172.20.1.0/24 via 172.20.1.0 dev flannel.1 onlink 172.20.2.0/24 dev cni0 proto kernel scope link src 172.20.2.1 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.102
在VXLAN模式下,flanneld从etcd获取子网并配置了后端之后会生成一个环境变量文件(默认为/run/flannel/subnet.env),其中包含本节点使用的子网,以及为了承载隧道报文而设置的MTU的定义等,如下面的配置示例所示。随后,flanneld还将持续监视etcd中相应配置租约信息的变动,并实时反映到本地路由信息之上。
root@k8s-node1:~# cat /run/flannel/subnet.env FLANNEL_NETWORK=172.20.0.0/16 FLANNEL_SUBNET=172.20.2.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true
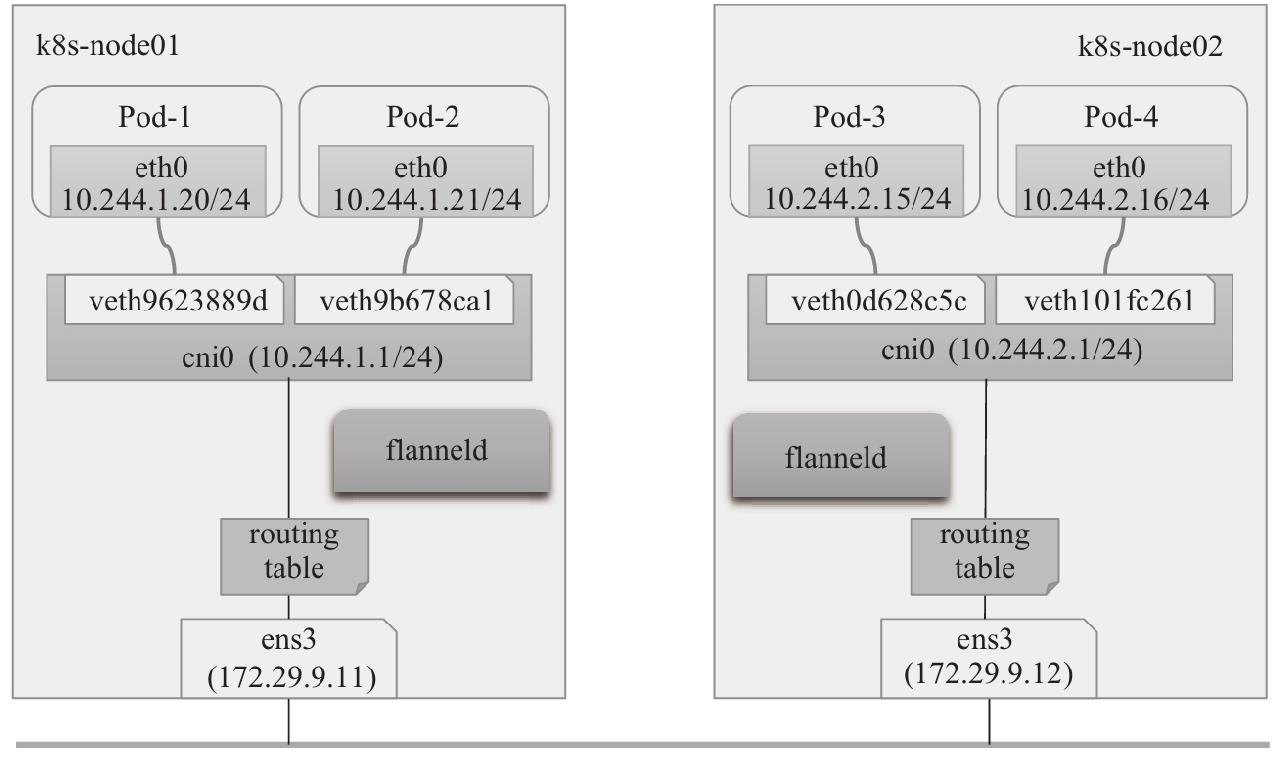
基于Flannel项目的在线配置清单部署了默认VXLAN后端的Flannel网络插件,跨节点Pod间均是通过Overlay网络进行通信,如下图中的Pod-1和Pod-4,而同节点的Pod对象关联在同一个虚拟网桥cni0之上,彼此间可无须隧道而直接进行通信,如下图中的Pod-1和Pod-2。
vxlan后端(图)
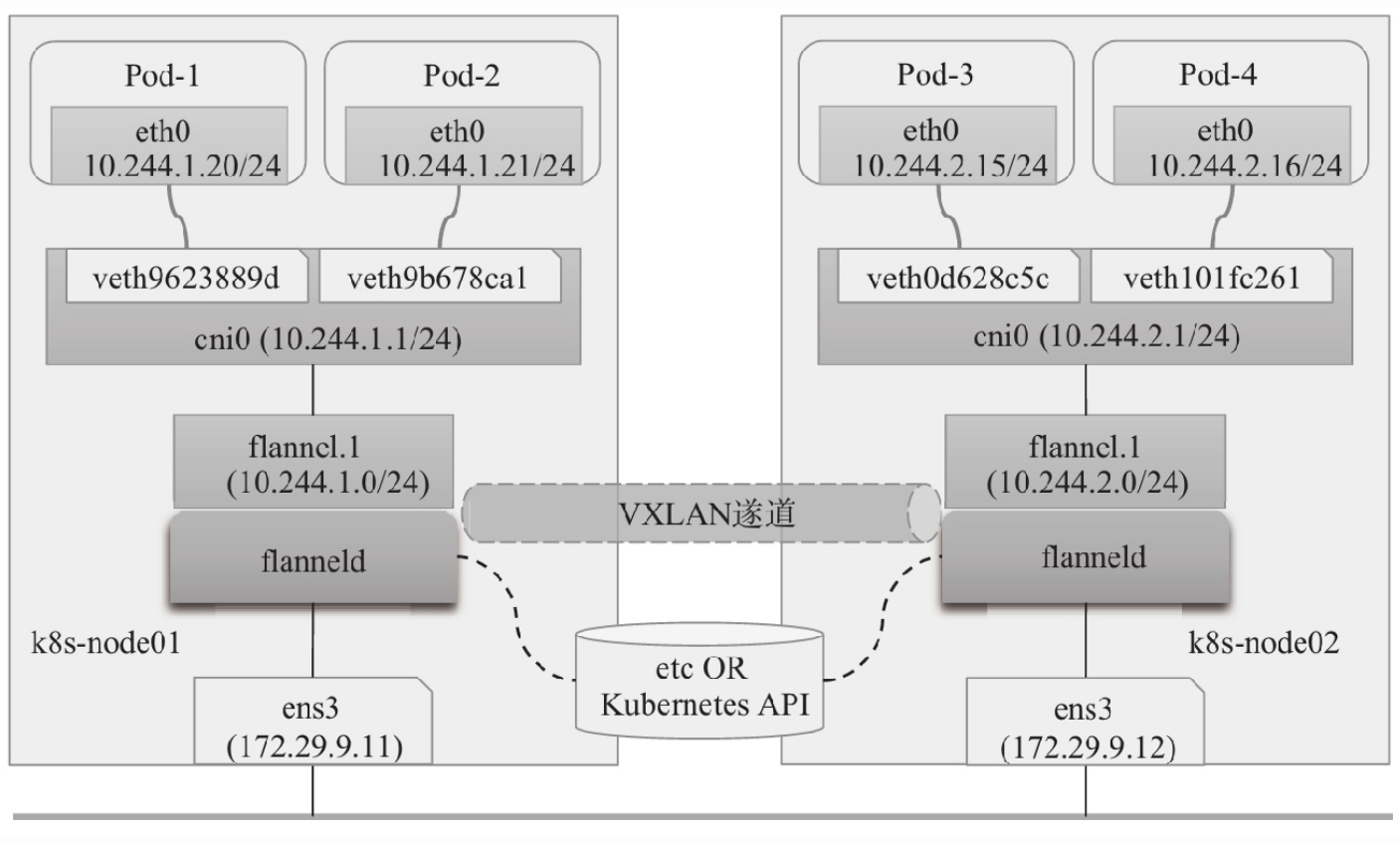
下面的路由信息取自k8s-node0节点,它由该节点上的flanneld根据集群中各节点获得的子网信息生成。
root@k8s-node1:~# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 172.20.0.0 172.20.0.0 255.255.255.0 UG 0 0 0 flannel.1 172.20.1.0 172.20.1.0 255.255.255.0 UG 0 0 0 flannel.1 172.20.2.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0 192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
其中,172.20.0.0/24由k8s-master1使用,172.20.1.0/24由k8s-node2节点使用,172.20.2.0/24由k8s-node1节点使用
#k8s-master root@k8s-master:~# cat /run/flannel/subnet.env FLANNEL_NETWORK=172.20.0.0/16 FLANNEL_SUBNET=172.20.0.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true #k8s-node1 root@k8s-node1:~# cat /run/flannel/subnet.env FLANNEL_NETWORK=172.20.0.0/16 FLANNEL_SUBNET=172.20.2.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true #k8s-node2 root@k8s-node2:~# cat /run/flannel/subnet.env FLANNEL_NETWORK=172.20.0.0/16 FLANNEL_SUBNET=172.20.1.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true
这些路由条目恰恰反映了同节点Pod间通信时经由cni0虚拟网桥转发,而跨节点Pod间通信时,报文将经由当前节点(k8s-node01)的flannel.1隧道入口(VTEP设备)外发,隧道出口由“下一跳”信息指定,例如到达172.20.5.0/24网络的报文隧道出口是172.20.5.0指向的接口,它配置在k8s-node03的flannel.1接口之上,该接口正是k8s-node03上的隧道出入口(VTEP设备)。
root@k8s-node1:~# ip neigh show | awk '$3 == "flannel.1"{print $0}' 172.20.0.0 dev flannel.1 lladdr fa:40:5f:2d:8e:40 PERMANENT 172.20.1.0 dev flannel.1 lladdr 5e:b1:10:42:f7:bd PERMANENT
VXLAN协议使用UDP报文封装隧道内层数据帧,Pod发出的报文经隧道入口flannel.1封装成数据帧,再由flanneld进程(客户端)封装成UDP报文,之后发往目标Pod对象所在节点的flanneld进程(服务端)。该UDP报文就是所谓的VXLAN隧道,它会在已经生成的帧报文之外再封装一组协议头部,如图10-15所示为VXLAN头部、外层UDP头部、外层IP头部和外层帧头部。
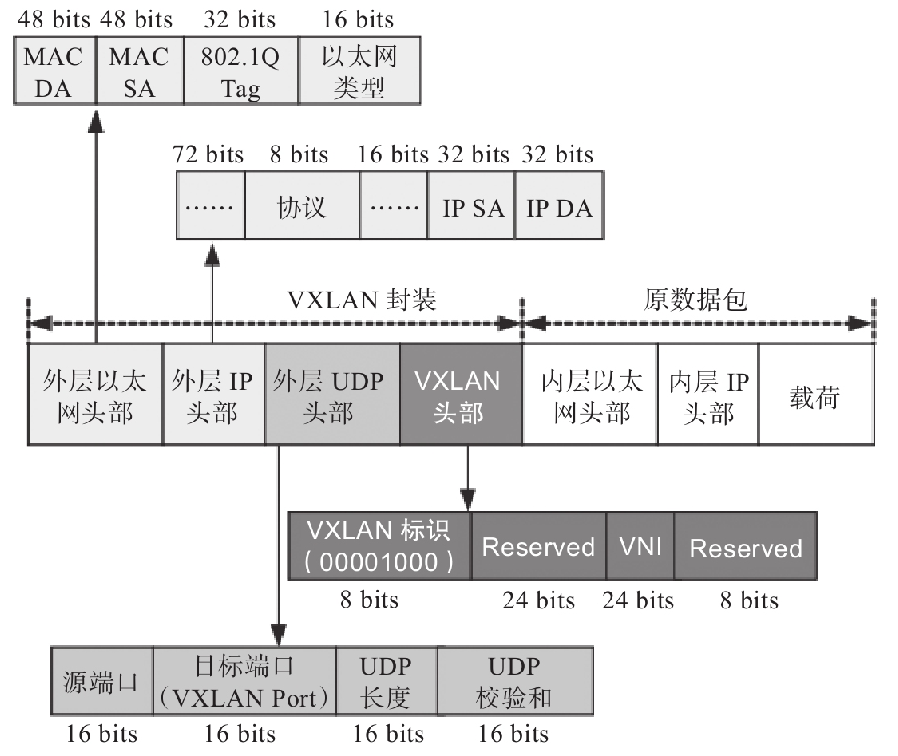
vxlan的数据流量

1) 源容器veth0向目标容器发送数据,根据容器内的默认路由,数据首先发送给宿主机的docker0网桥
2)宿主机docker0网桥接受到数据后,宿主机查询路由表,pod相关的路由都是交由flannel.1网卡,因此,将其转发给flannel.1虚拟网卡处理
3)flannel.1接受到数据后,查询etcd数据库,获取目标pod网段对应的目标宿主机地址、目标宿主机的flannel网卡的mac地址、vxlan vnid等信息。然后对数据进行udp封装如下:
udp头封装:
source port >1024,target port 8472
udp内部封装:
vxlan封装:vxlan vnid等信息
original layer 2 frame封装:source {源 flannel.1网卡mac地址} target{目标flannel.1网卡的mac地址}
完成以上udp封装后,将数据转发给物理机的eth0网卡
4)宿主机eth0接收到来自flannel.1的udp包,还需要将其封装成正常的通信用的数据包,为它加上通用的ip头、二层头,这项工作在由linux内核来完成。
Ethernet Header的信息:
source:{源宿主机机网卡的MAC地址}
target:{目标宿主机网卡的MAC地址}
IP Header的信息:
source:{源宿主机网卡的IP地址}
target:{目标宿主机网卡的IP地址}
通过此次封装,一个真正可用的数据包就封装完成,可以通过物理网络传输了。
5)目标宿主机的eth0接收到数据后,对数据包进行拆封,拆到udp层后,将其转发给8472端口的flannel进程
6)目标宿主机端flannel拆除udp头、vxlan头,获取到内部的原始数据帧,在原始数据帧内部,解析出源容器ip、目标容器ip,重新封装成通用的数据包,查询路由表,转发给docker0网桥;
7)最后,docker0网桥将数据送达目标容器内的veth0网卡,完成容器之间的数据通信
2、DirectRouting
Flannel的VXLAN后端还支持DirectRouting模式,即在集群中的各节点上添加必要的路由信息,让Pod间的IP报文通过节点的二层网络直接传送,如下图所示。仅在通信双方的Pod对象所在的节点跨IP网络时,才启用传统的VXLAN隧道方式转发通信流量。若Kubernetes集群节点全部位于单个二层网络中,则DirectRouting模式下的Pod间通信流量基本接近于直接使用二层网络。
在Kubernetes上的Flannel来说,修改kube-system名称空间下的configmaps/kube-flannel-cfg资源,为VXLAN后端添加DirectRouting子键,并设置其值为true即可。
本k8s集群是使用kubeasz部署的,因此需要修改kubeasz中关于集群网路的配置并重新部署k8s集群
root@k8s-deploy:~# vim /etc/kubeasz/clusters/k8s-test/config.yml ...... FLANNEL_BACKEND: "vxlan" #DIRECT_ROUTING: false DIRECT_ROUTING: true ......
节点上的路由规则也会相应发生变动,到达与本地节点位于同一二层网络中的其他节点,Pod子网的下一跳地址由对端flannel.1接口地址变为了宿主机物理接口的地址,本地用于发出报文的接口从flannel.1变成了本地的物理接口。仍然以k8s-node1节点为例,修改VXLAN后端支持DirectRouting模式,则该节点上的路由信息变动为如下结果:
root@k8s-node1:~# ip route show default via 192.168.1.1 dev eth0 proto static 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown 172.20.0.0/24 via 172.20.0.0 dev flannel.1 onlink 172.20.1.0/24 via 172.20.1.0 dev flannel.1 onlink 172.20.2.0/24 dev cni0 proto kernel scope link src 172.20.2.1 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.102
Pod与节点通常不在同一网络。Pod间的通信报文需要经由宿主机的物理接口发出,必然会经过iptables/netfilter的forward钩子,为了避免该类报文被防火墙拦截,Flannel必须为其设定必要的放行规则。本集群中的每个节点上iptables filter表的FORWARD链上都会生成如下两条转发规则,以确保由物理接口接收或发送的目标地址或源地址为172.20.0/16网络的所有报文能够正常通过。
root@k8s-master1:~# iptables -nL ...... ACCEPT all -- 172.20.0.0/16 anywhere ACCEPT all -- anywhere 172.20.0.0/16 ......
root@k8s-deploy:/etc/kubeasz# kubectl run testpod-1 --image=ikubernetes/demoapp:v1.0 pod/testpod-1 created root@k8s-deploy:/etc/kubeasz# kubectl run testpod-2 --image=ikubernetes/demoapp:v1.0 pod/testpod-2 created root@k8s-deploy:/etc/kubeasz# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES testpod-1 1/1 Running 0 40s 172.20.1.6 192.168.1.103 <none> <none> testpod-2 1/1 Running 0 31s 172.20.2.10 192.168.1.102 <none> <none>
进入testpod-1
root@k8s-deploy:/etc/kubeasz# kubectl exec -it testpod-1 -- sh [root@testpod-1 /]# traceroute 172.20.2.10 traceroute to 172.20.2.10 (172.20.2.10), 30 hops max, 46 byte packets 1 172.20.1.1 (172.20.1.1) 0.004 ms 0.002 ms 0.001 ms 2 192.168.1.102 (192.168.1.102) 0.336 ms 0.121 ms 0.095 ms 3 172.20.2.10 (172.20.2.10) 0.140 ms 0.239 ms 0.123 ms #testpod-1访问testpod-2时,不在转发非flannel,而是直接转发给testpod-2所在的node节点
以k8s-node1为例子
root@k8s-node1:~# ip a | grep flannel.1 5: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default inet 172.20.2.0/32 brd 172.20.2.0 scope global flannel.1
Flannel的host-gw后端通过添加必要的路由信息,并使用节点的二层网络直接发送Pod间的通信报文,其工作方式类似于VXLAN后端中的直接路由功能,但不包括该后端支持的隧道转发能力,这意味着host-gw后端要求各节点必须位于同一个二层网络中。其工作模型示意图如下图所示。因完全不会用到VXLAN隧道,所以使用了host-gw后端的Flannel网络也就无须用到VTEP设备flannel.1。
注意:
直接路由仅node节点在同一网段,不能跨网段。
host-gw后端没有多余的配置参数,直接设定配置文件中的Backend.Type键的值为host-gw关键字即可。同样,直接修改kube-system名称空间中的configmaps/kube-flannel.cfg配置文件,类似下面配置示例中的内容即可。
net-conf.json: | { "Network": "172.20.0.0/16", "Backend": { "Type": "host-gw" } }
配置完成后,集群中的各节点会生成类似VXLAN后端的DirectRouting路由及iptables规则,以转发Pod网络的通信报文,它完全省去了隧道转发模式的额外开销。代价是,对于非同一个二层网络的报文转发,host-gw完全无能为力。相对而言,VXLAN的DirectRouting后端转发模式兼具VXLAN后端和host-gw后端的优势,既保证了传输性能,又具备跨二层网络转发报文的能力。
Flannel自身并不具备为Pod网络实施网络策略以实现其网络通信控制的能力,它只能借助Calico这类支持网络策略的插件实现该功能,独立的项目Calico正为此目的而设立。
root@k8s-deploy:~# vim /etc/kubeasz/clusters/k8s-test/config.yml ...... #FLANNEL_BACKEND: "vxlan" FLANNEL_BACKEND: "host-gw" #DIRECT_ROUTING: false #DIRECT_ROUTING: true ......
以k8s-node1为例
root@k8s-node1:~# ip route default via 192.168.1.1 dev eth0 proto static 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown 172.20.0.0/24 via 192.168.1.101 dev eth0 172.20.1.0/24 via 192.168.1.103 dev eth0 172.20.2.0/24 dev cni0 proto kernel scope link src 172.20.2.1 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.102 root@k8s-node1:~# ip a | grep flannel root@k8s-node1:~# #无flannel设备
三、Calico网络插件
官网:https://www.projectcalico.org
Calico网络提供的在线部署清单中默认使用的是IPIP隧道网络,而非BGP或者混合模型,因为它假设节点的底层网络不支持BGP协议。明确需要使用BGP或混合模型时,需要事先修改calico的yaml清单文件,按需修改后方可部署在Kubernetes集群之上。
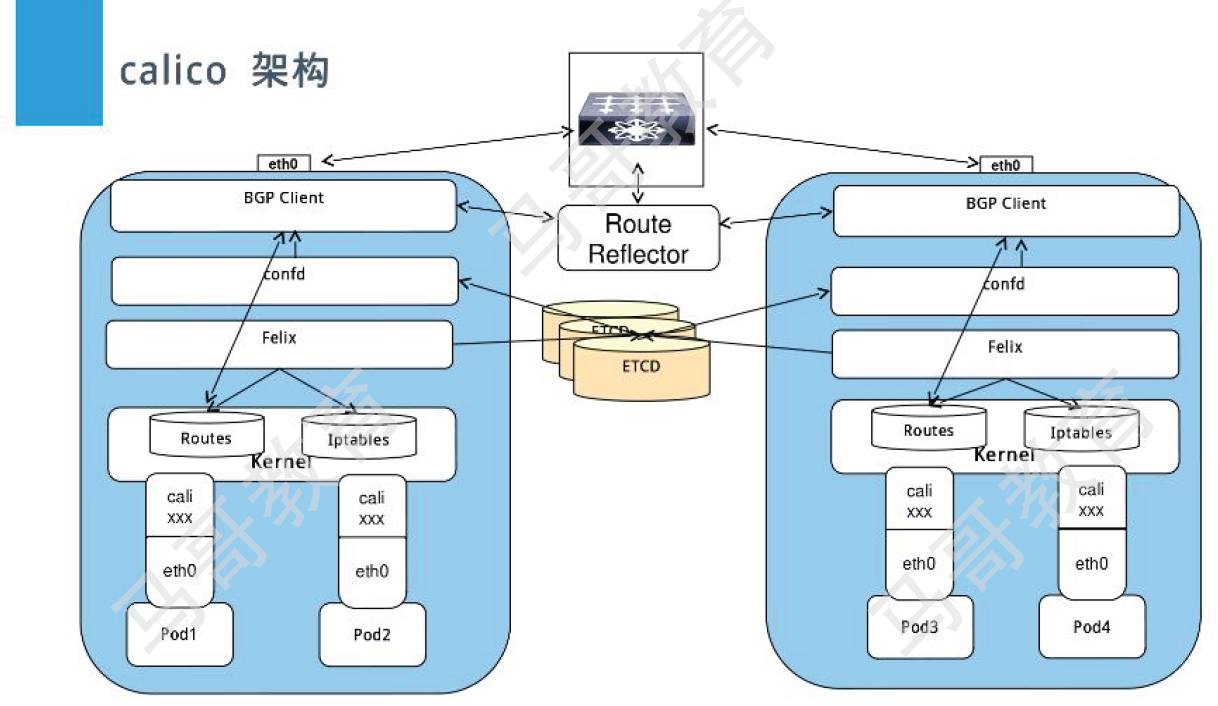

Calico的系统组件主要有Felix、BGP路由反射器、编排系统插件、BIRD和etcd存储系统等。
(1)Felix Felix是运行于各节点上守护进程,它主要负责完成接口管理、路由规划、ACL规划和状态报告几个核心任务,从而为各端点(VM或Container)生成连接机制。 1)接口管理,负责创建网络接口、生成必要信息并送往内核,以确保内核能正确处理各端点的流量,尤其是要确保目标节点MAC能响应当前节点上各工作负载的MAC地址的ARP请求,以及为Felix管理的接口打开转发功能。另外,接口管理还要监控各接口的变动以确保规则能得到正确应用。 2)路由规划,负责为当前节点上运行的各端点在内核FIB(Forwarding Information Base)中生成路由信息,以保证到达当前节点的报文可正确转发给端点。 3)ACL规划,负责在Linux内核中生成ACL,实现仅放行端点间的合规流量,并确保流量不能绕过Calico等安全措施。 4)状态报告,负责提供网络健康状态的相关数据,尤其是报告由Felix管理的节点上的错误和问题。这些报告数据会存储在etcd,供其他组件或网络管理员使用。
简单理解为:运行在每一台node节点上,主要功能是维护路由规则、汇报当前节点状态以确保pod的跨主机通信。
(2)编排系统插件 编排系统插件的主要功能是将Calico整合进所在的编排系统中,例如Kubernetes或OpenStack等。它主要负责完成API转换,从而让管理员和用户能够无差别地使用Calico的网络功能。换句话说,编排系统通常有自己的网络管理API,相应的插件要负责将对这些API的调用转换为Calico的数据模型,并存储到Calico的存储系统中。因而,编排插件的具体实现依赖于底层编排系统,不同的编排系统有各自专用的插件。
(3)etcd存储系统 利用etcd,Calico网络可实现为有明确状态(正常或故障)的系统,且易于通过扩展应对访问压力的提升,避免自身成为系统瓶颈。另外,etcd也是Calico各组件的通信总线。
(4)BGP客户端 Calico要求在每个运行着Felix的节点上同时运行一个称为BIRD的守护进程,它是BGP协议的客户端,负责将Felix生成的路由信息载入内核并通告给整个网络中。
BGP Client运行在每一台node节点,负责监听node节点上由felix生成的路由信息,然后通过BGP协议广播至其他剩余的node节点,从而相互学习路由实现pod通信。
(5)BGP路由反射器 Calico在每一个计算节点利用Linux内核实现了一个高效的vRouter(虚拟路由器)进行报文转发。每个vRouter通过BGP协议将自身所属节点运行的Pod资源的IP地址信息,基于节点上的专用代理程序(Felix)生成路由规则向整个Calico网络内传播。尽管小规模部署能够直接使用BGP网格模型,但随着节点数量(假设为N)的增加,这些连接的数量就会以N2的规模快速增长,从而给集群网络带来巨大的压力。因此,一般建议大规模的节点网络使用BGP路由反射器进行路由学习,BGP的点到点通信也就转为与中心点的单路通信模型。另外,出于冗余考虑,生产实践中应该部署多个BGP路由反射器。而对于Calico来说,BGP客户端程序除了作为客户端使用外,也可以配置为路由反射器。
Route Reflector:集中式的路由反射器,calico v3.3开始支持,当calico BGP客户端将路由从其FIB(Forward Information DataBase,转发信息库)通告到Route Reflector时,Route Reflector会将这些路由通告给部署集群中的其他节点,Route Reflector专门用于管理BGP网络路由规则,不会产生pod数据通信。
注意:
calico默认工作模式为BGP的node-to-node mesh,如果需要使用Route Reflector需要进行相关配置。
https://docs.projectcalico.org/v3.4/usage/routereflector
https://docs.projectcalico.org/v3.2/usage/routereflector/calico-routerreflector
2、Calico 工作原理
Calico把每个操作系统的协议栈认为是一个路由器,然后把所有的容器认为是连在这个路由器上的网络终端,在路由器之间跑标准的路由协议——BGP的协议,然后让它们自己去学习这个网络拓扑该如何转发。所以Calico方案其实是一个纯三层的方案,也就是说让每台机器的协议栈的三层去确保两个容器,跨主机容器之间的三层连通性。
对于控制平面,它每个节点上会运行两个主要的程序,一个是Felix,它会监听ECTD中心的存储,从它获取事件,比如说用户在这台机器上加了一个IP,或者是分配了一个容器等。接着会在这台机器上创建出一个容器,并将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。绿色部分是一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,你们路由的时候得到这里来。
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
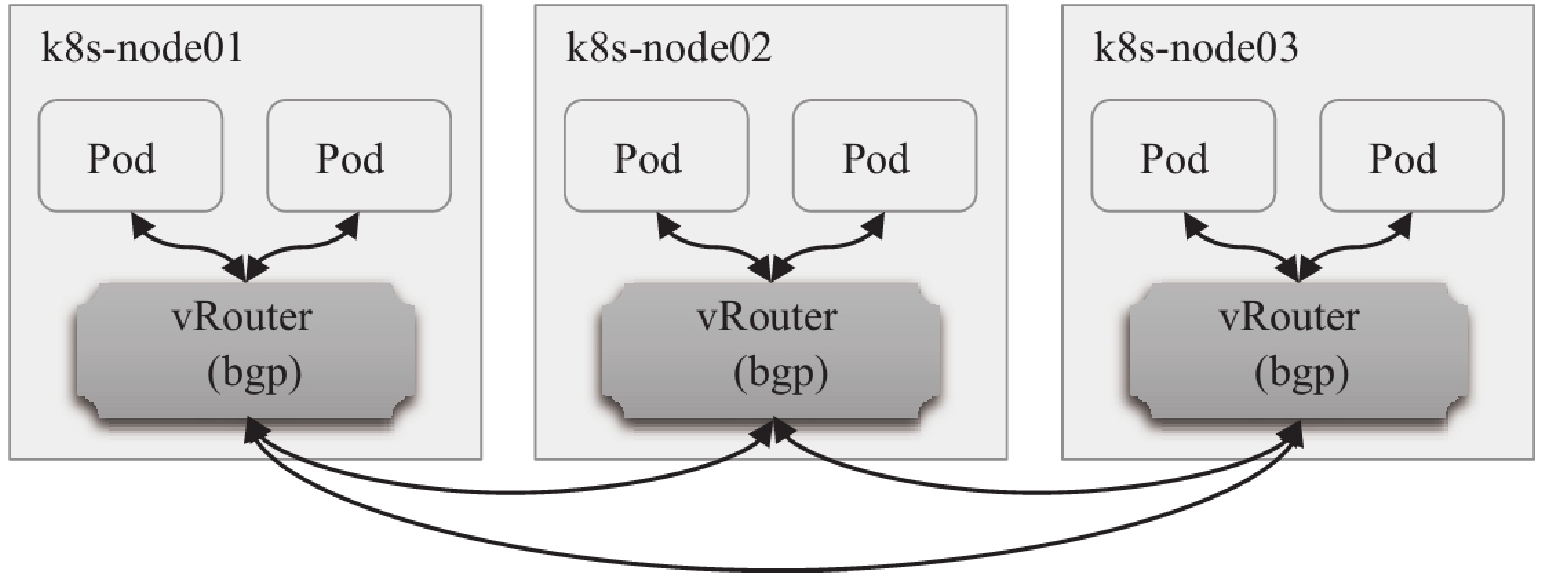
3、node-to-node mesh模式
全互联模式 每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N*(N-1),如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式。
2.1 Calico开启IPIP模式
calico是使用node-to-node mesh的方式要维护路由规则,及每个node节点上都有n(n-1)条路哟规则,n为node的节点数量。
以k8s-node1为例来验证路由信息
calico 2.x 版本默认使用etcd v2 API
calico 3.x 版本默认使用etcd v3 API
root@k8s-node1:~# calicoctl node status Calico process is running. IPv4 BGP status +---------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------+-------------------+-------+----------+-------------+ | 192.168.1.101 | node-to-node mesh | up | 15:25:25 | Established | | 192.168.1.103 | node-to-node mesh | up | 15:25:26 | Established | +---------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found. #k8s-node01所有的master和node节点都建立了BGP邻居关系
运行4个pod
root@k8s-deploy:/etc/kubeasz# kubectl run testpod-1 --image=ikubernetes/demoapp:v1.0 pod/testpod-1 created root@k8s-deploy:/etc/kubeasz# kubectl run testpod-2 --image=ikubernetes/demoapp:v1.0 pod/testpod-2 created root@k8s-deploy:/etc/kubeasz# kubectl run testpod-3 --image=ikubernetes/demoapp:v1.0 pod/testpod-3 created root@k8s-deploy:/etc/kubeasz# kubectl run testpod-4 --image=ikubernetes/demoapp:v1.0 pod/testpod-4 created root@k8s-deploy:/etc/kubeasz# kubectl get pod -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES default testpod-1 1/1 Running 2 69m 172.20.169.129 192.168.1.103 <none> <none> default testpod-2 1/1 Running 2 69m 172.20.36.66 192.168.1.102 <none> <none> default testpod-3 1/1 Running 0 5s 172.20.36.67 192.168.1.102 <none> <none> default testpod-4 1/1 Running 0 2s 172.20.169.130 192.168.1.103 <none> <none>
查看k8s-node1的路由信息
root@k8s-node1:~# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 172.20.36.64 0.0.0.0 255.255.255.192 U 0 0 0 * 172.20.36.65 0.0.0.0 255.255.255.255 UH 0 0 0 cali146f692ec0d 172.20.36.66 0.0.0.0 255.255.255.255 UH 0 0 0 cali3d1e6ac0b31 172.20.36.67 0.0.0.0 255.255.255.255 UH 0 0 0 cali4a41f53597d 172.20.169.128 192.168.1.103 255.255.255.192 UG 0 0 0 tunl0 172.20.235.192 192.168.1.101 255.255.255.192 UG 0 0 0 tunl0 192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 root@k8s-node1:~# ip route default via 192.168.1.1 dev eth0 proto static 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown blackhole 172.20.36.64/26 proto bird 172.20.36.65 dev cali146f692ec0d scope link 172.20.36.66 dev cali3d1e6ac0b31 scope link 172.20.36.67 dev cali4a41f53597d scope link 172.20.169.128/26 via 192.168.1.103 dev tunl0 proto bird onlink 172.20.235.192/26 via 192.168.1.101 dev tunl0 proto bird onlink 192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.102 #1、k8s-node1上访问本地容器走cali3d1e6ac0b31接口,Calico并不会为容器在主机上使用网桥,而是仅为每个容器生成一对veth设备,留在主机上的那一端会在主机上生成目标地址,作为当前容器的路由条目。 #2、k8s-node01上需要跨主机访问时,走tunl0隧道
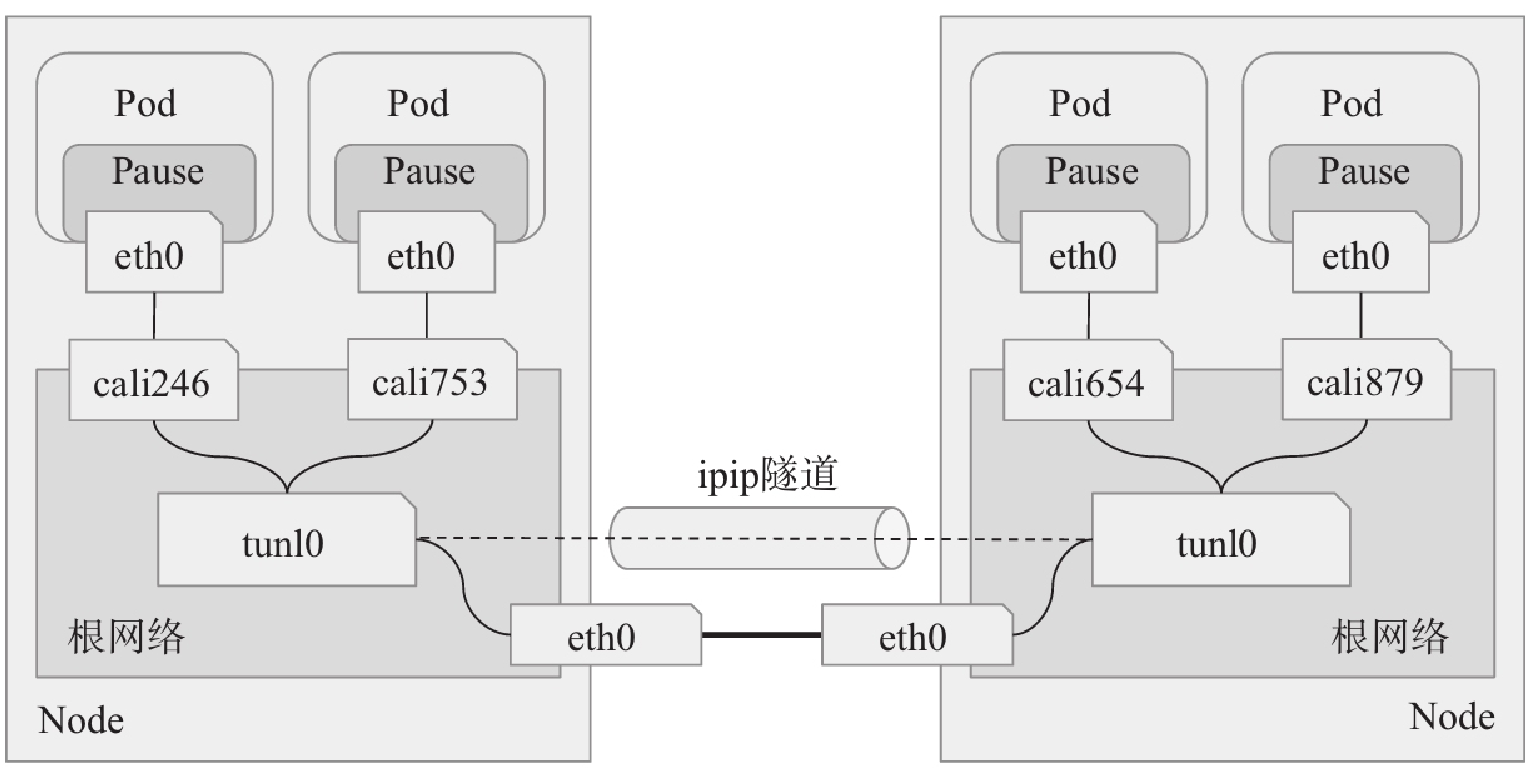
当访问同一个node的不同pod时,node节点会查询路由表把报文发往相应的calixxx目标地址;当访问不同node上的pod时,node会把数据包发往tunl0,再根据etcd中的保存的路由信息来转发。
root@k8s-node1:~# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 172.20.36.64 0.0.0.0 255.255.255.192 U 0 0 0 * 172.20.36.65 0.0.0.0 255.255.255.255 UH 0 0 0 cali146f692ec0d #本地容器接口 172.20.36.66 0.0.0.0 255.255.255.255 UH 0 0 0 cali3d1e6ac0b31 #本地容器接口 172.20.36.67 0.0.0.0 255.255.255.255 UH 0 0 0 cali4a41f53597d #本地容器接口 172.20.169.128 192.168.1.103 255.255.255.192 UG 0 0 0 tunl0 #隧道接口 172.20.235.192 192.168.1.101 255.255.255.192 UG 0 0 0 tunl0 #隧道接口 192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 kubectl run testpod-1 --image=ikubernetes/demoapp:v1.0 kubectl run testpod-2 --image=ikubernetes/demoapp:v1.0 kubectl run testpod-3 --image=ikubernetes/demoapp:v1.0 kubectl run testpod-4 --image=ikubernetes/demoapp:v1.0 root@k8s-deploy:/etc/kubeasz# kubectl get pod -A -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES default testpod-1 1/1 Running 2 69m 172.20.169.129 192.168.1.103 <none> <none> default testpod-2 1/1 Running 2 69m 172.20.36.66 192.168.1.102 <none> <none> default testpod-3 1/1 Running 0 5s 172.20.36.67 192.168.1.102 <none> <none> default testpod-4 1/1 Running 0 2s 172.20.169.130 192.168.1.103 <none> <none> #测试在同一个node下pod的访问,k8s-node01上有2个pod,testpod-2和testpod-3 root@k8s-deploy:/etc/kubeasz# kubectl exec -it testpod-2 -- sh [root@testpod-2 /]# traceroute 172.20.36.67 traceroute to 172.20.36.67 (172.20.36.67), 30 hops max, 46 byte packets 1 192.168.1.102 (192.168.1.102) 0.004 ms 0.005 ms 0.002 ms 2 172.20.36.67 (172.20.36.67) 0.001 ms 0.003 ms 0.001 ms #1、数据包从testpod-2出到达Veth Pair另一端(宿主机上,以cali前缀开头cali3d1e6ac0b31) #2、宿主机根据路由规则,将数据包转发给下一跳(网关) #3、发现下一跳为自己的cali4a41f53597d,直接转发数据包给cali4a41f53597d,到达test-pod3 #测试在不在同一个node下pod的访问,testpod-2和testpod-4 [root@testpod-2 /]# traceroute 172.20.169.130 traceroute to 172.20.169.130 (172.20.169.130), 30 hops max, 46 byte packets 1 192.168.1.102 (192.168.1.102) 0.004 ms 0.003 ms 0.002 ms 2 172.20.169.128 (172.20.169.128) 0.268 ms 0.082 ms 0.163 ms #走的tunl0隧道 3 172.20.169.130 (172.20.169.130) 0.191 ms 0.207 ms 0.153 ms #1、数据包从 testpod-2 出到达Veth Pair另一端(宿主机上,以cali前缀开头cali3d1e6ac0b31) #2、宿主机根据路由规则,将数据包转发给下一跳(网关) #3、到达 Node3,根据路由规则将数据包转发给 cali 设备,从而到达 testpod-3。
IPIP就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel,看起来似乎是浪费,实则不然。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。ipip 的源代码在内核 net/ipv4/ipip.c 中可以找到。
2.2 Calico关闭IPIP模式
与Flannel的host-gw的模式相似,后端通过添加必要的路由信息,并使用节点的二层网络直接发送Pod间的通信报文,同时也跟host-gw一样不支持跨网段。
Calico关闭IPIP模式将不会有tunl0隧道,pod之间的访问全靠
root@k8s-deploy:~# vim /etc/kubeasz/clusters/k8s-test/config.yml ...... # [calico]设置 CALICO_IPV4POOL_IPIP=“off”,可以提高网络性能,条件限制详见 docs/setup/calico.md #CALICO_IPV4POOL_IPIP: "Always" CALICO_IPV4POOL_IPIP: "off" ......
创建4个pod
kubectl run testpod-1 --image=ikubernetes/demoapp:v1.0 kubectl run testpod-2 --image=ikubernetes/demoapp:v1.0 kubectl run testpod-3 --image=ikubernetes/demoapp:v1.0 kubectl run testpod-4 --image=ikubernetes/demoapp:v1.0 root@k8s-deploy:/etc/kubeasz# kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES testpod-1 1/1 Running 3 97m 172.20.169.132 192.168.1.103 <none> <none> testpod-2 1/1 Running 3 96m 172.20.36.69 192.168.1.102 <none> <none> testpod-3 1/1 Running 1 27m 172.20.36.68 192.168.1.102 <none> <none> testpod-4 1/1 Running 1 27m 172.20.169.131 192.168.1.103 <none> <none>
查看k8s-node1上的路由信息
root@k8s-node1:~# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 172.20.36.64 0.0.0.0 255.255.255.192 U 0 0 0 * 172.20.36.68 0.0.0.0 255.255.255.255 UH 0 0 0 cali4a41f53597d 172.20.36.69 0.0.0.0 255.255.255.255 UH 0 0 0 cali3d1e6ac0b31 172.20.36.70 0.0.0.0 255.255.255.255 UH 0 0 0 cali146f692ec0d 172.20.169.128 192.168.1.103 255.255.255.192 UG 0 0 0 eth0 172.20.235.192 192.168.1.101 255.255.255.192 UG 0 0 0 eth0 192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
没有tunl0隧道接口
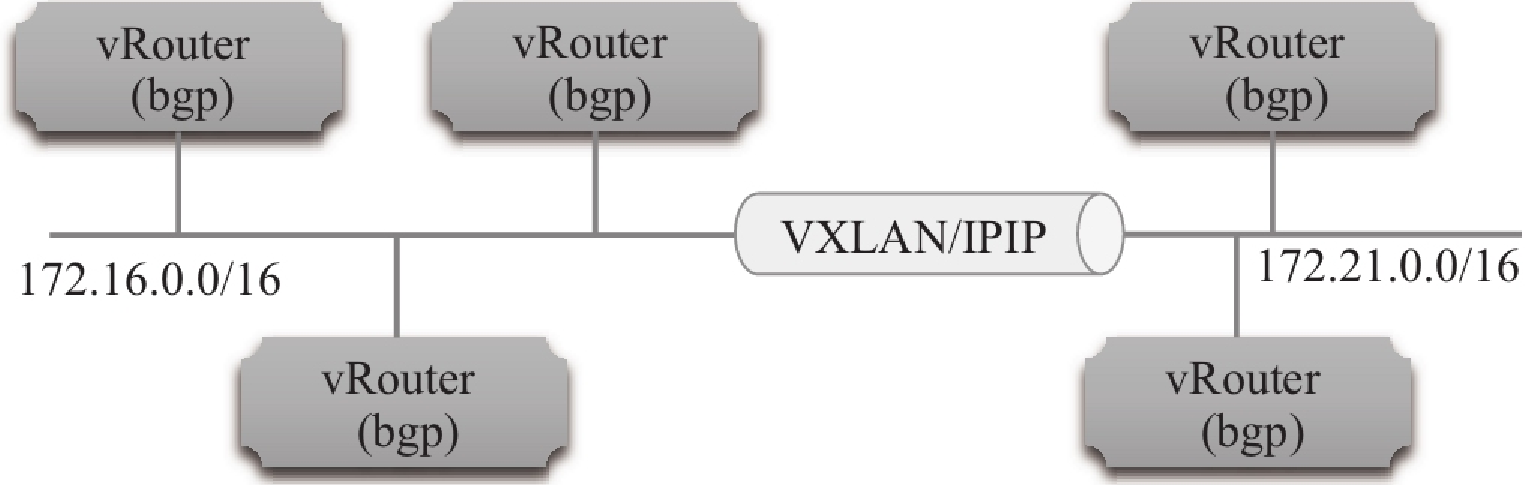
4、Route Reflector 模式(RR)(路由反射)
设置方法请参考官方链接 https://docs.projectcalico.org/master/networking/bgp
Calico 维护的网络在默认是 (Node-to-Node Mesh)全互联模式,Calico集群中的节点之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。确定一个或多个Calico节点充当路由反射器,让其他节点从这个RR节点获取路由信息。
在BGP中可以通过calicoctl node status看到启动是 node-to-node mesh 网格的形式,这种形式是一个全互联的模式,默认的BGP在k8s的每个节点担任了一个BGP的一个喇叭,一直吆喝着扩散到其他节点,随着集群节点的数量的增加,那么上百台节点就要构建上百台链接,就是全互联的方式,都要来回建立连接来保证网络的互通性,那么增加一个节点就要成倍的增加这种链接保证网络的互通性,这样的话就会使用大量的网络消耗,所以这时就需要使用Route reflector,也就是找几个大的节点,让他们去这个大的节点建立连接,也叫RR,也就是公司的员工没有微信群的时候,找每个人沟通都很麻烦,那么建个群,里面的人都能收到,所以要找节点或着多个节点充当路由反射器,建议至少是2到3个,一个做备用,一个在维护的时候不影响其他的使用。
四、CNI的选择
CNI 网络方案优缺点及最终选择
1、需要细粒度网络访问控制?
这个flannel是不支持的,calico支持,所以做多租户网络方面的控制ACL,那么要选择 calico。
2、追求网络性能?
选择 flannel host-gw模式 calico BGP(关闭IPIP)模式。
3、服务器之前是否可以跑BGP协议?
很多的公有云是不支持跑BGP协议,那么使用calico的BGP模式自然是不行的。
4、集群规模多大?
如果规模不大,100以下节点可以使用flannel,优点是维护比较简单。
5、是否有维护能力?
1、需要细粒度网络访问控制?
这个flannel是不支持的,calico支持,所以做多租户网络方面的控制ACL,那么要选择 calico。
2、追求网络性能?
选择 flannel host-gw 模式 和calico BGP模式。
3、服务器之前是否可以跑BGP协议?
很多的公有云是不支持跑BGP协议,那么使用calico的BGP模式自然是不行的。
4、集群规模多大?
如果规模不大,100以下节点可以使用flannel,优点是维护比较简单。
5、是否有维护能力?
calico的路由表很多,而且走BGP协议,一旦出现问题排查起来也比较困难,上百台的,路由表去排查也是很麻烦,这个具体需求需要根据自己的情况而定。
6、CNI选择总结
calico支持更多的网络层的安全策略,flannel不支持
公有云大多数都是使用的flannel,早期使用UDP,后来有了vxlan之后就使用vxlan+Directrouting
自建IDC里面使用什么都可以,flannel配置比较交单,calico功能更加完善 性能差别不是很大,据统计,calico性能略高于flannel
私有云推荐使用calico
公有云可以使用flannel

 浙公网安备 33010602011771号
浙公网安备 33010602011771号