
一、kubernete基础
一、什么是Kubernetes
Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化工作负载和服务,有助于声明式配置和自动化。它拥有庞大且快速发展的生态系统。Kubernetes 服务、支持和工具广泛可用
使用Kubernetes可以:
自动化容器的部署和复制 随时扩展或收缩容器规模 将容器组织成组,并且提供容器间的负载均衡 很容易地升级应用程序容器的新版本 提供容器弹性,如果容器失效就替换它 密钥和配置管理 存储编排 批量处理运行 ...
传统虚拟化和容器虚拟化的对比
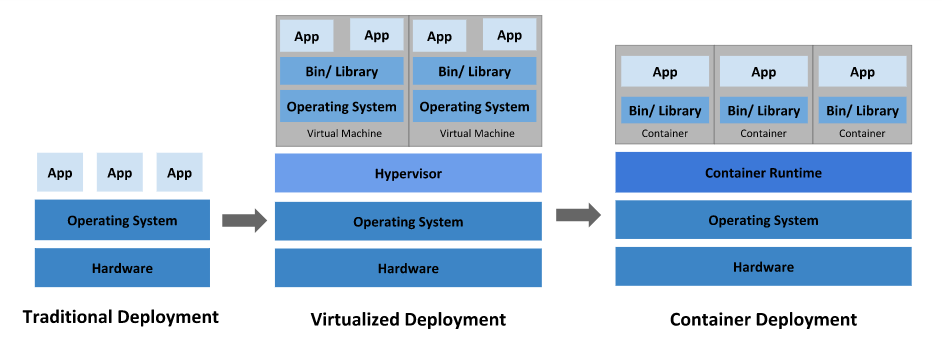
传统部署时代: 早期,组织在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。例如,如果多个应用程序在物理服务器上运行,可能会出现一个应用程序占用大部分资源的情况,结果,其他应用程序的性能将不佳。一个解决方案是在不同的物理服务器上运行每个应用程序。但这并没有扩展,因为资源没有得到充分利用,而且组织维护许多物理服务器的成本很高。
虚拟化部署时代:作为解决方案,引入了虚拟化。它允许您在单个物理服务器的 CPU 上运行多个虚拟机 (VM)。虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全性,因为一个应用程序的信息不能被另一个应用程序自由访问。
虚拟化允许更好地利用物理服务器中的资源并允许更好的可扩展性,因为可以轻松添加或更新应用程序,降低硬件成本等等。通过虚拟化,您可以将一组物理资源呈现为一次性虚拟机集群。
每个 VM 都是在虚拟化硬件之上运行所有组件的完整机器,包括它自己的操作系统。
容器部署时代:容器类似于虚拟机,但它们具有放松的隔离属性,可以在应用程序之间共享操作系统(OS)。因此,容器被认为是轻量级的。与 VM 类似,容器有自己的文件系统、CPU 份额、内存、进程空间等。由于它们与底层基础架构分离,因此它们可以跨云和操作系统分布移植。
容器之所以流行,是因为它们提供了额外的好处,例如:
- 敏捷的应用程序创建和部署:与使用 VM 映像相比,容器映像创建的简便性和效率更高。
- 持续开发、集成和部署:提供可靠且频繁的容器映像构建和部署以及快速高效的回滚(由于映像不变性)。
- Dev 和 Ops 的关注点分离:在构建/发布时而不是部署时创建应用程序容器映像,从而将应用程序与基础架构解耦。
- 可观察性:不仅可以显示操作系统级别的信息和指标,还可以显示应用程序运行状况和其他信号。
- 开发、测试和生产之间的环境一致性:在笔记本电脑上运行与在云中运行相同。
- 云和操作系统分发可移植性:在 Ubuntu、RHEL、CoreOS、本地、主要公共云和其他任何地方运行。
- 以应用程序为中心的管理:将抽象级别从在虚拟硬件上运行操作系统提高到使用逻辑资源在操作系统上运行应用程序。
- 松散耦合、分布式、弹性、自由的微服务:应用程序被分解成更小的、独立的部分,并且可以动态部署和管理——而不是在一台大型单一用途机器上运行的单一堆栈。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率、高密度。
二、Kubernets架构
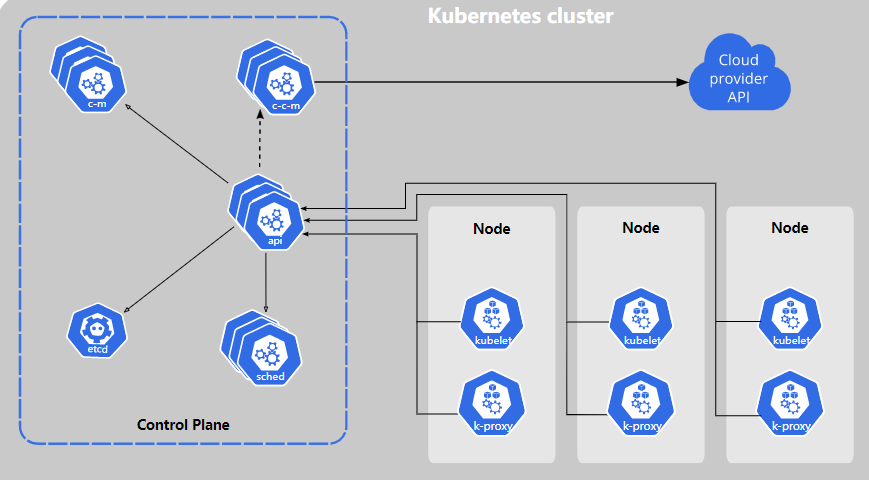
三、控制平面组件
控制平面的组件对集群做出全局决策(例如,调度),以及检测和响应集群事件(例如,启动一个新的pod当部署的replicas字段不满意时)。
控制平面组件可以在集群中的任何机器上运行。但是,为简单起见,通常在同一台机器上启动所有控制平面组件,并且不在这台机器上运行业务容器,只运行组件相关容器
kube-apiserver
Kubernetes API,集群的统一入口各组件的协调者,以RESTful API提供接口服务,所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储。
它是整个kubernetes集群的大脑,它通过部署更多实例来扩展。可以运行多个 kube-apiserver 实例并平衡这些实例之间的流量
kube-controller-manager
Kubernetes 控制器管理器是一个守护进程,它们是处理集群中常规任务的后台线程。内嵌随 Kubernetes 一起发布的核心控制回路。 说白了,Controller Manager 就是集群内部的管理控制中心,由负责不同资源的多个 Controller 构成,共同负责集群内的 Node、Pod 等所有资源的管理,比如当通过 Deployment 创建的某个 Pod 发生异常退出时,RS Controller 便会接受并处理该退出事件,并创建新的 Pod 来维持预期副本数, 目前,Kubernetes 自带的控制器例子包括副本控制器、节点控制器、命名空间控制器和服务账号控制器等。
从逻辑上讲,每个控制器是一个单独的进程,但为了降低复杂性,它们都被编译成一个二进制文件并在一个进程中运行。
这些控制器的一些类型是:
Node controller:负责在节点宕机时进行通知和响应。 Job controller:监视代表一次性任务的作业对象,然后创建 Pod 以运行这些任务以完成。 Endpoints controller:填充 Endpoints 对象(即加入 Services & Pods)。 Service Account & Token controllers:为新命名空间创建默认帐户和 API 访问令牌
kube-scheduler
scheduler的职责很明确,就是负责调度pod到合适的Node上。Kubernetes目前提供了调度算法,但是同样也保留了接口,用户可以根据自己的需求定义自己的调度算法
etcd
etcd是一个高可用的键值存储系统,Kubernetes使用它来存储当前集群中所有的状态数据
1)运行的 etcd 集群个数成员为奇数。
2)etcd 是一个 leader-based 分布式系统。确保主节点定期向所有从节点发送心跳,以保持集群稳定。
3)确保不发生资源不足。
集群的性能和稳定性对网络和磁盘 IO 非常敏感。任何资源匮乏都会导致心跳超时,从而导致集群的不稳定。不稳定的情况表明没有选出任何主节点。在这种情况下,集群不能对其当前状态进行任何更改,这意味着不能调度新的 pod。
4)保持稳定的 etcd 集群对 Kubernetes 集群的稳定性至关重要。因此,请在专用机器或隔离环境上运行 etcd 集群,以满足所需资源需求。
5)在生产中运行的 etcd 的最低推荐版本是 3.2.10+。
四、节点组件
kubelet
运行在每个节点上的主要的“节点代理”,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器,kubelet 不管理不是由 Kubernetes 创建的容器。
kube-proxy
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。就是维护节点中的iptables或者ipvs规则,这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
container-runtime
容器运行时是负责运行容器的软件
五、pod创建流程

1.kubectl 向 k8s api server 发起一个create pod 请求 2.k8s api server接收到pod创建请求后,不会去直接创建pod;而是生成一个包含创建信息的yaml,并写入etcd数据库 3.API Server告知Schedule为其分配node,在分配完node之后将结果返回API Server,并将结果存储在etcd上 4.node节点访问API Server然后读取etcd拿到分配给当前节点的pod,然后响应给docker创建容器 5.把本节点的pod信息同步到etcd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号