
FP - growth 发现频繁项集
FP - growth是一种比Apriori更高效的发现频繁项集的方法。FP是frequent pattern的简称,即常在一块儿出现的元素项的集合的模型。通过将数据集存储在一个特定的FP树上,然后发现频繁项集或者频繁项对。通常,FP-growth算法的性能比Apriori好两个数量级以上。
FP树与一般的树结构类似,但它通过链接(Link)来连接相似元素,被连起来的元素项可以看成一个链表。
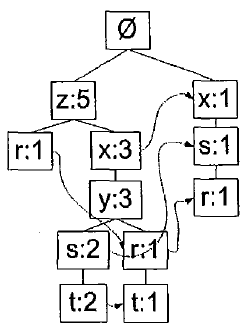
上图是一棵FP树,一个元素项可以在一棵FP树种出现多次,FP树的节点会存储项集的出现频率,每个项集会以路径的方式存储在树中。存在相似元素的集合会共享树的一部分,只有当集合之间完全不同时,树才会分叉。树节点上给出集合中的单个元素及其在序列中的出现次数,路径会给出该序列的出现次数。相似元素之间的链接即节点链接,用于快速发现相似项的位置。

表中给出了生成上面FP树(支持度>=3)的数据集。在所有数据集中,元素项z出现了5次,集合{r,z}出现了1次,于是可以得出结论:z一定是自己本身或者和其他符号一起出现了4 次。集合{t,s,y,x,z}出现了2次,集合{t,r,y,x,z}出现1次,z自身出现了1次。因为使用的最小支持度是3,所以q,p等小于3次的元素没有出现在FP树中。
FP树的构建过程中,需要对原始数据集进行两次扫描(Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁),第一遍对所有元素项的出现次数进行计数,用于统计每个元素的出现频率,Apriori算法告诉我们,如果某元素是不频繁的,那么包含该元素的超集也是不频繁的,所以就不需要考虑这些超集了。第二遍用于构建FP树,扫描中只考虑哪些频繁元素。
FP树的节点的类定义如下:
class treeNode: def __init__(self, nameValue, numOccur, parentNode): self.name = nameValue self.count = numOccur self.nodeLink = None self.parent = parentNode #needs to be updated self.children = {} def inc(self, numOccur): self.count += numOccur def disp(self, ind=1): print ' '*ind, self.name, ' ', self.count for child in self.children.values(): child.disp(ind+1)
类中包含用于存放节点名字的变量name和一个个记数值count,nodeLink变量用于链接相似的元素项。parent变量用于指向当前节点的父节点,children变量为一个字典类型,用于存放节点的子节点。inc()用于对count进行计数,disp()用于将树以文本方式显示。
构建FP树,还需要一个字典类型的头指针表来指向给定类型的第一个实例。利用头指针表,可以快速访问FP树中一个给定类型的所有元素,同时,头指针表还用来保存FP树中每类元素的总数。
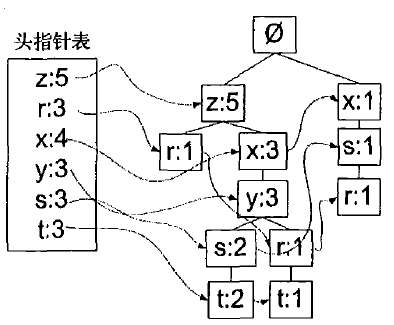
构建FP树的步骤。第一次遍历数据集,计算得到每个元素项出现的频率,接下来,去掉不满足最小支持度的元素项。第二次遍历构建FP树,读入每个项集并将其添加到一条已经存在的路径中,如果该路径不存在,则创建一条心路径。每个数据集都是一个无序集合,假设有集合{z,x,y}和{y,z,r},那么在FP树中,相同项会只表示一次。为解决此问题,在将集合添加到树之前,需要对每个集合进行排序,排序基于元素项的绝对出现频率来进行。

在对集合过滤和排序之后,就可以构建FP树了。从空集开始,向其中不断添加频繁项集。过滤、排序后的事物一次添加到树中,如果树中已存在现有元素,则增加现有元素的值;如果现有元素不存在,则向树添加一个分支。
FP树的构建代码:
def createTree(dataSet, minSup=1): #create FP-tree from dataset but don't mine headerTable = {} #go over dataSet twice for trans in dataSet:#first pass counts frequency of occurance for item in trans: headerTable[item] = headerTable.get(item, 0) + dataSet[trans] for k in headerTable.keys(): #remove items not meeting minSup if headerTable[k] < minSup: del(headerTable[k]) freqItemSet = set(headerTable.keys()) #print 'freqItemSet: ',freqItemSet if len(freqItemSet) == 0: return None, None #if no items meet min support -->get out for k in headerTable: headerTable[k] = [headerTable[k], None] #reformat headerTable to use Node link #print 'headerTable: ',headerTable retTree = treeNode('Null Set', 1, None) #create tree for tranSet, count in dataSet.items(): #go through dataset 2nd time localD = {} for item in tranSet: #put transaction items in order if item in freqItemSet: localD[item] = headerTable[item][0] if len(localD) > 0: orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)] updateTree(orderedItems, retTree, headerTable, count)#populate tree with ordered freq itemset return retTree, headerTable #return tree and header table def updateTree(items, inTree, headerTable, count): if items[0] in inTree.children:#check if orderedItems[0] in retTree.children inTree.children[items[0]].inc(count) #incrament count else: #add items[0] to inTree.children inTree.children[items[0]] = treeNode(items[0], count, inTree) if headerTable[items[0]][1] == None: #update header table headerTable[items[0]][1] = inTree.children[items[0]] else: updateHeader(headerTable[items[0]][1], inTree.children[items[0]]) if len(items) > 1:#call updateTree() with remaining ordered items updateTree(items[1::], inTree.children[items[0]], headerTable, count) def updateHeader(nodeToTest, targetNode): #this version does not use recursion while (nodeToTest.nodeLink != None): #Do not use recursion to traverse a linked list! nodeToTest = nodeToTest.nodeLink nodeToTest.nodeLink = targetNode
在FP树构建完成之后,就可以利用FP树挖掘频繁项集了。思路与Apriori算法大致相似,基于FP树,首先从单元素项集合开始,然后在此基础上逐步构建更大的集合。
从FP树中抽取频繁项集的三个基本步骤:
1. 从FP树中获得条件模式基。
2.利用条件模式基,构建一个条件FP树。
3.迭代重复步骤1和2,直到树包含一个元素项为止。
条件模式基(conditional pattern base)是以所查找元素项为结尾的路径集合。每一条路径其实都是一条前缀路径,一条前缀路径是介于所查找元素项与树根节点之间的所有内容。
从下表可以看出,符号r的前缀路径是{x,s}、{z,x,y}和{z}。每一条前缀路径都与一个计数值关联,该计数值等于起始元素项r的计数值。

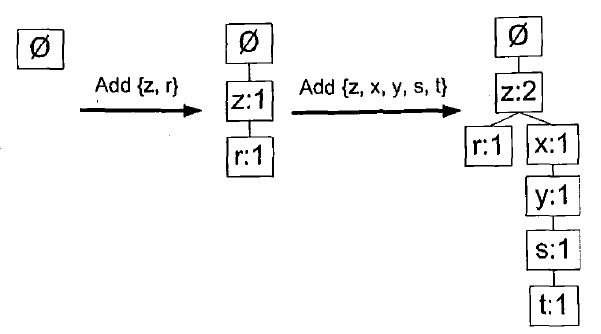
创建条件FP树:对于每一个频繁项,都要创建一棵条件FP树,以条件模式基作为输入数据,并通过构建FP树相同的代码来构建这些书。然后,我们会递归的返现频繁项、发现条件模式基,以及发现另外的条件树。假定对频繁项t创建一个条件FP树,然后对{t,y}、{t,x}、...重复该过程。元素项t的条件FP树的构建过程如下图:

实现代码如下:
def ascendTree(leafNode, prefixPath): #ascends from leaf node to root if leafNode.parent != None: prefixPath.append(leafNode.name) ascendTree(leafNode.parent, prefixPath) def findPrefixPath(basePat, treeNode): #treeNode comes from header table condPats = {} while treeNode != None: prefixPath = [] ascendTree(treeNode, prefixPath) if len(prefixPath) > 1: condPats[frozenset(prefixPath[1:])] = treeNode.count treeNode = treeNode.nodeLink return condPats def mineTree(inTree, headerTable, minSup, preFix, freqItemList): bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])]#(sort header table) for basePat in bigL: #start from bottom of header table newFreqSet = preFix.copy() newFreqSet.add(basePat) #print 'finalFrequent Item: ',newFreqSet #append to set freqItemList.append(newFreqSet) condPattBases = findPrefixPath(basePat, headerTable[basePat][1]) #print 'condPattBases :',basePat, condPattBases #2. construct cond FP-tree from cond. pattern base myCondTree, myHead = createTree(condPattBases, minSup) #print 'head from conditional tree: ', myHead if myHead != None: #3. mine cond. FP-tree #print 'conditional tree for: ',newFreqSet #myCondTree.disp(1) mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号