
初识RAG
检索增强生成(RAG,Retrieval-Augmented Generation)能够对大语言模型(LLM)的输出进行优化,使其能够在生成响应(response)之前引用训练数据来源之外的知识库中的数据对输入提示词(prompt)进行润色,从而让大模型给出更准确的答案。但大模型本身受限于训练时所采用的语料库,只能给出通用的响应。RAG可以在一定程度上弥补这方面的不足,使得响应的真实性,本地化和时效性方面有所提高。
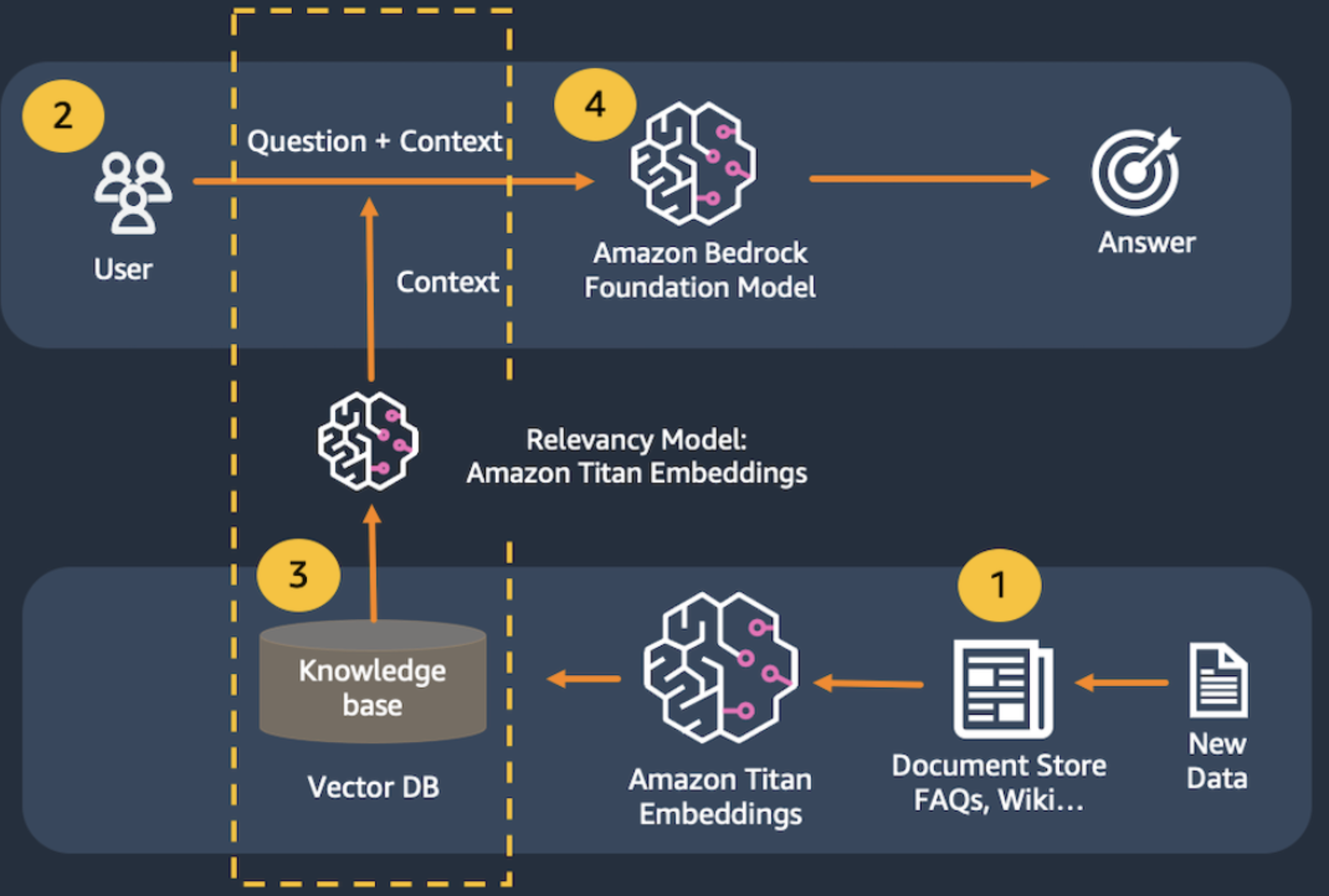
最近参加了AWS的一个AI培训,简单的学习了RGA相关的知识。RAG系统业务流程图如下:
1. 构建向量数据库。把数据切分成chunks,就是把海量文本按一定长度或自然段进行切分;再通过Amazon Titan Embeddings library转成向量,最后再把转成的向量存入向量数据库,比如Elasticsearch。
2. 用户输入问题。
3. 通过查询向量数据库,找到跟问题相关的数据,然后构造prompt,通常不同类型的问题需要构造不同的prompt模版,然后把从向量数据库中查到的相似度较高的文本填充到模版里,生成一个prompt
4. 把生成的prompt输入给大模型(这里是Amazon Bedrock Foundation Model),最后大模型给出相关的回复(response)。
如何切分chunks会对生成prompt的结果有一定的影响,比如每个chunk的size,两个相近的chunk之间的overlap
text_splitter = RecursiveCharacterTextSplitter( #create a text splitter
separators=["\n\n", "\n", ".", " "], #split chunks at (1) paragraph, (2) line, (3) sentence, or (4) word, in that order
chunk_size=500, #divide into 1000-character chunks using the separators above
chunk_overlap=50 #number of characters that can overlap with previous chunk
)
当然,采用的文本转向量的模型以及向量数据库(相似度搜索方法)也会对生成的prompt有影响。跟传统的软件开发差别较大的是,传统软件开发中有办法定位到问题的根因并有针对性的解决,但在RAG的系统中,很难定位根因是chunk size的问题,还是转向量的问题或其他问题。
构建RAG的关键是构建Knowledage base。通常的步骤是:构造数据源=>切分成chunks=>转向量=>存入向量数据库
生成高质量的Prompt是RAG的主要功能。通常不同类型的问题对应不同的Prompt模版。一般prompt的开头都是“你是一个某某方面的工程师/咨询师/科学家/...”,让AI扮演改角色,然后描绘背景知识(来自向量数据)和问题。
比如下面这Prompt模版,告诉大模型师一个财务咨询系统,回答相关财务方面的问题。
prompt = f"""
Human: You are a financial advisor AI system, and provides answers to questions by using fact based and statistical information when possible.
Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context>
{contexts}
</context>
<question>
{query}
</question>
The response should be specific and use statistics or numbers when possible.
Assistant:"""
对于一些连续的问答,把上一次的答案作为下一次的prompt中的content再输入给大模型,一般会得到更准确的结果。通常在内存里或者利用向量数据库来临时存储之前对话的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号