
《Selective Kernel Networks》
神经科学界认为视皮层神经元的感受野大小受刺激的调节,即对不同刺激,卷积核的大小应该不同。
本篇论文中提出了一种在CNN中对卷积核的动态选择机制,该机制允许每个神经元根据输入信息的多尺度自适应地调整其感受野(卷积核)的大小。设计了一个称为选择性内核单元(SK)的构建块,其中,多个具有不同内核大小的分支在这些分支中的信息引导下,使用SoftMax进行融合。由多个SK单元组成SKNet,SKNet中的神经元能够捕获不同尺度的目标物体。
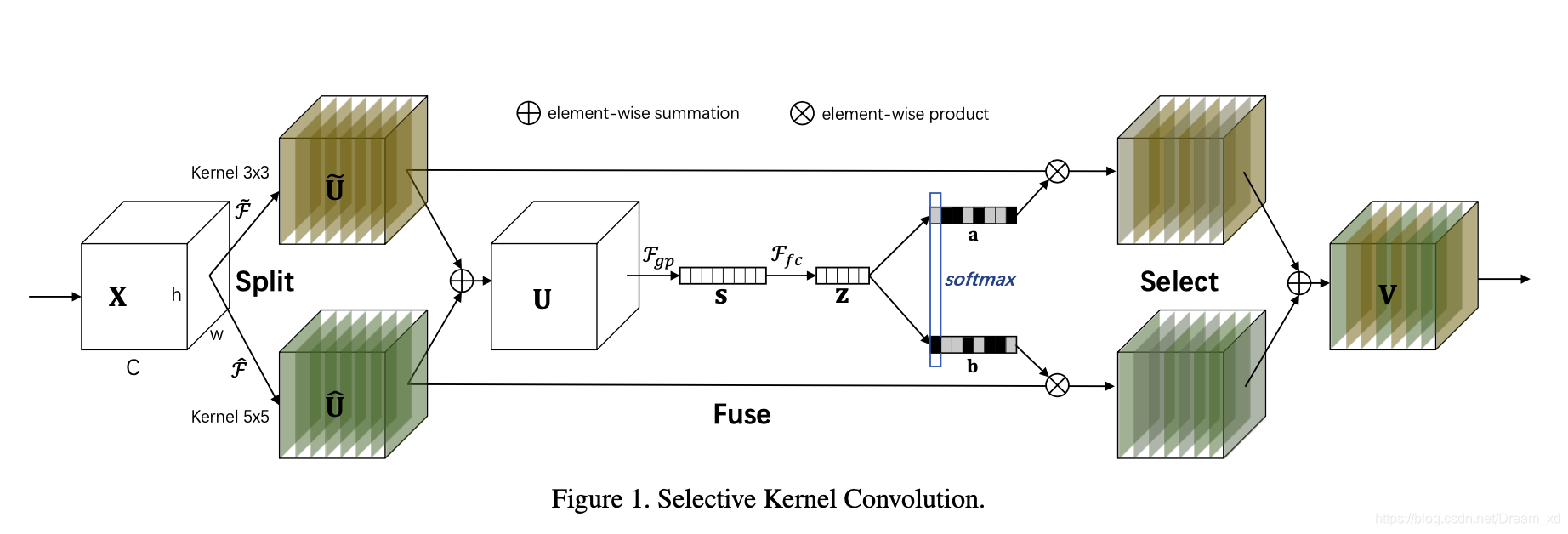
SKNet由三个运算组成:分裂(Split)、融合(Fuse)和选择(Select)。Split算子产生多条不同核大小的路径,上图中的模型只设计了两个不同大小的卷积核,实际上可以设计多个分支的多个卷积核。fuse运算符结合并聚合来自多个路径的信息,以获得用于选择权重的全局和综合表示。select操作符根据选择权重聚合不同大小内核的特征图。
Split:
如下图所示,使用多个卷积核对 X 进行卷积,以形成多个分支。
图中使用3×3和5×5的卷积核的两个分支,为了进一步提高效率,将常规的5x5卷积替换为5x5的空洞卷积,即3x3,rate = 2卷积核。下图为5x5的空洞卷积
Fuse:
首先通过元素求和从多个分支中融合出结果。
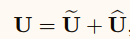
通过简单地使用全局平均池化来嵌入全局信息,从而生成信道统计信息s,\(s∈R^C\),C是模型图中S的特征维数或公式s的特征维数。
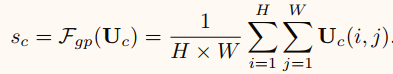
通过一个简单的全连接(fc)层创建了一个紧凑的特征Z,使其能够进行精确和自适应的选择特征,同时减少了维度以提高效率。\(z∈R^{d\times 1}\)
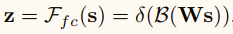
其中 δ 是relu激活函数,B表示批标准化,\(W∈R^{d\times C}\)。为了研究 d(全连接后的特征维数,即公式z或模型图中Z的特征维数) 对模型效率的影响,使用一个折减比 r 来控制其值。
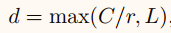
L表示d的极小值,通过 L=32 是原文中实验的设置。
Select
按照信道的方向使用softmax
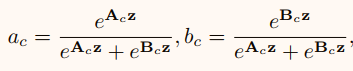
然后与Split卷积后的特征进行乘和求和操作
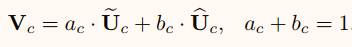
通过在自然图像中放大目标对象和缩小背景来模拟刺激,以保持图像大小不变。结果发现,当目标物体越来越大时,大多数神经元会越来越多地从更大的核路径中收集信息。这些结果表明,所提出的sknet中的神经元具有自适应的感受野大小。
《Strip Pooling: Rethinking Spatial Pooling for Scene Parsing》
本论文通过改进空间池化层来优化场景分割。传统的标准pooling多是方形,而实际场景中会有一些物体是长条形,需要模型能够尽可能捕获一个long-range的dependencies。因此,作者引入来一种long but narrow kernel。即本文的strip pooling操作。这个操作的引入使网络可以更加高效地获取网络大范围感受野下的信息,在这个理念的基础上搭建了使用多个长条池化层构建的新模块Strip Pooling Module(SPM),使得该结构在现有的网络结构中能够即插即用。进一步将strip pooling和standard spatial pooling组合,提出mixed pooling module,即综合标准的spatial pooling和strip pooling,以兼顾各种shape的物体的分割。作者基于上面的所有改进,提出SPNet,验证前面几点的有效性。
strip pooling
实现上相当于把标准的spatial pooling的kernel的宽或高置为1,然后每次取所有水平元素或垂直元素相加求平均(average pooling,按文中公式的表述,每次取的所有水平元素或垂直元素的个数分别为输入的tensor的w和h),即只是改变了spatial pooling中采样的方式。
效果图:

strip pooling module
为了能让strip pooling实现在现有的不同网络结构中即插即用,作者设计了strip pooling module,即将strip pooling封装到该模块内部,保证对于输入特征图,经过SPM模块后,是已经执行过strip pooling操作的特征图。
结构如下图所示:
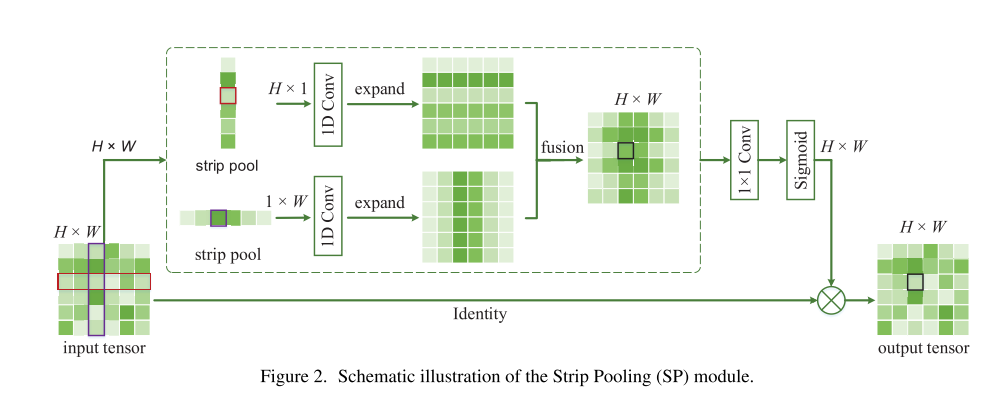
对于一个输入tensor分别处理水平和垂直的strip pooling,然后再通过上采样的插值实现expand到输入tensor的原尺寸。将两个结果相加进行融合;之后再添加一个1x1卷积改变通道个数,使用sigmoid作激活函数。
同时SPM中有一个类似residual的identity map操作,将上面两个pathway融合后经过sigmoid的结果直接通过element-wise的乘法融合到一起。这里相当于上一步sigmoid得到的是一个权重矩阵,得到输入tensor中每个位置的特征的重要性,因此,上面2路的pathway其实是可以不用重新训练的,有点像attention机制。
mixed pooling module
如果因为上面的考虑将网络中的所有pooling全部换成strip pooling操作,则必然会影响原来的非长条物体的效果,就得不偿失了。因此,作者将strip pooling和pyramid pooling都加入进来,构造成mixed pooling module
其中,strip pooling用于解决long-range dependencies,而轻量级的pyramid pooling用于解决short-range dependencies。
pyramid pooling
上面提到了pyramid pooling,这里简要介绍一下这种池化方式。Pyramid Pooling Module提出于Pyramid Scene Parsing Network。
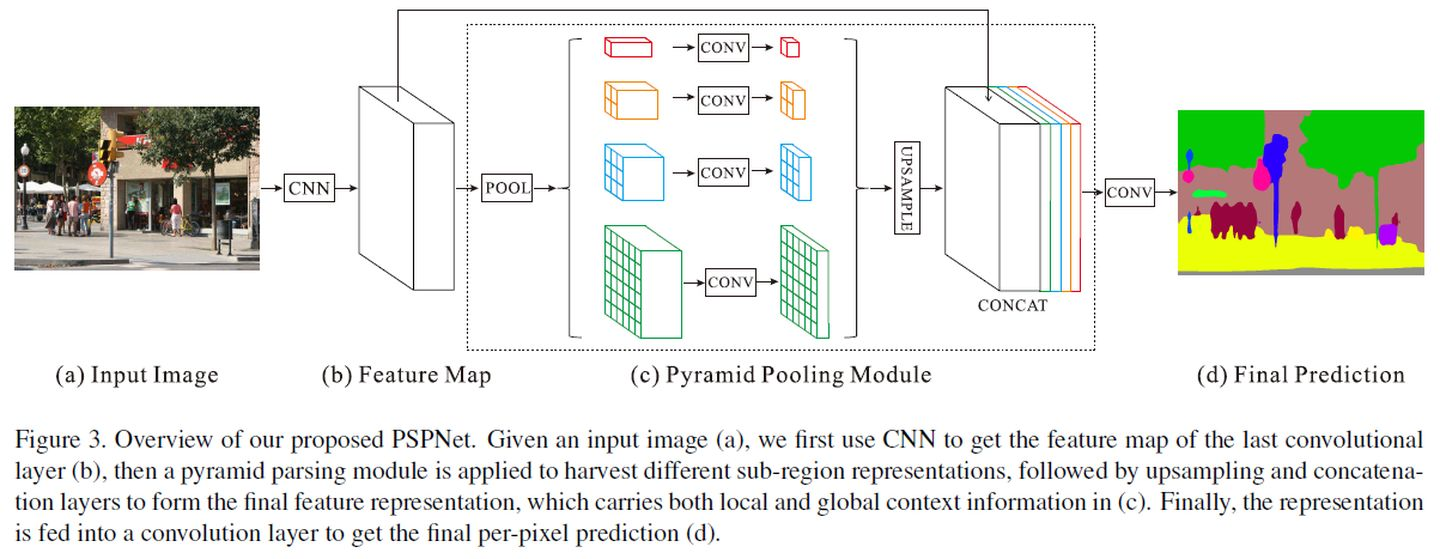
Pyramid Pooling Module的做法也很简单,使用不同窗口大小的pooling操作,得到不同尺寸的输出,然后上采样到相同的尺寸,再进行特征融合。
具体来说,包含4个pooling层次,对于原始特征图,分别通过pooling得到大小为 \(1×1\) , \(2×2\) , \(3×3\) 和 \(6×6\) 。然后分别使用\(1×1\)卷积调整通道数至 \(\frac{1}{N}\) (N即为pooling层次数,此时\(N=4\) )。然后将这些特征图全部上采样,通过双线性插值完成。再将这些pooling特征图输出,以及原始的特征图(跳跃连接),全部concat起来,作为特征输出,可以由此产生分割的预测结果。
实现过程中,这些pooling层通过AdaptivePooling层完成,根据输入输出大小计算pooling的窗口大小。其中输出大小为 \(1×1\) 时,其实就是Global Average Pooling。
《HRNet:Deep High-Resolution Representation Learning for Human Pose Estimation》
三个关键特点:
1.将高低分辨率之间的链接由串联改为并联。
2.在整个网络结构中都保持了高分辨率的表征(最上边那个通路)。
3.在高低分辨率中引入了交互来提高模型性能。
高分辨率图的存在使得空间上更加精准,低分辨率图的存在使得语义上更充分。
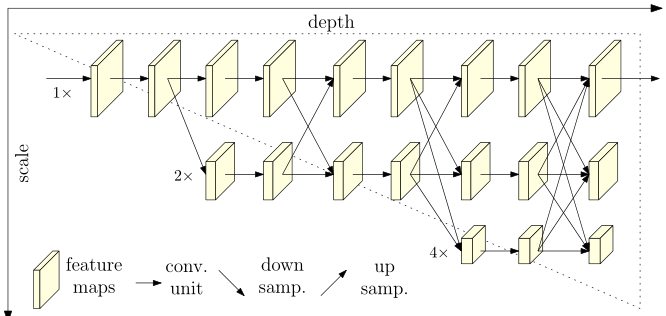
网络由四个阶段组成。第n个阶段包含对应于n个分辨率的n个流。通过反复的交换平行流中的信息来进行重复进行多分辨率的融合。
其他的高低分辨率融合都是通过融合low_level的高分率和低分辨率上采用获得的high_level高分辨率。而hrnet是在低分辨率的帮助下,多次融合高分辨率。
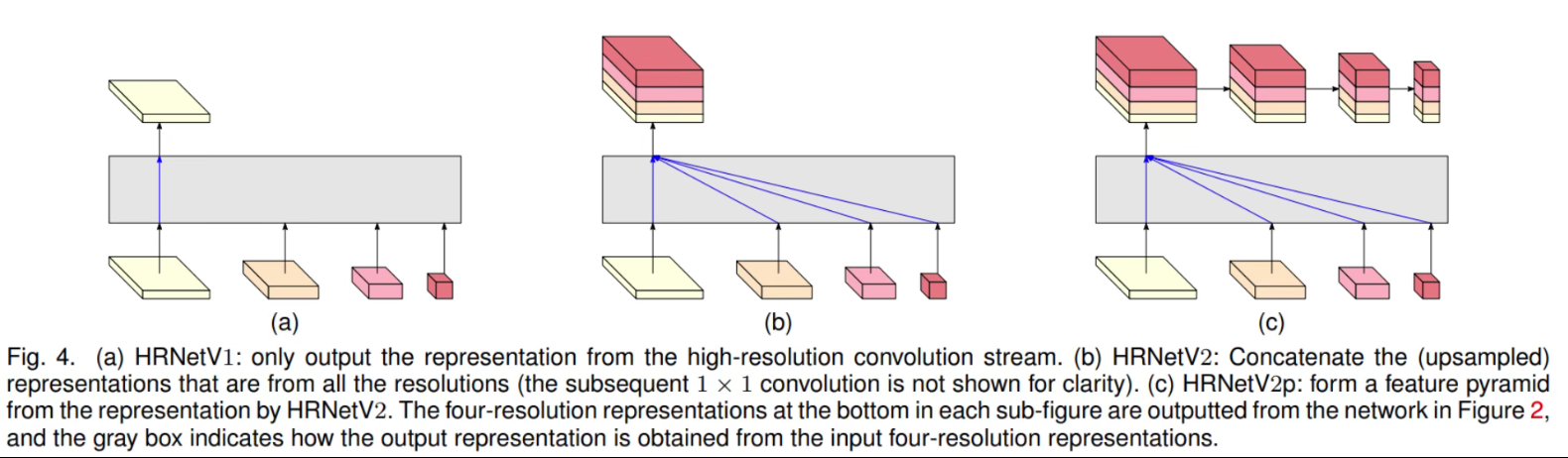
HRNetV1:只输出从高分辨率卷积流计算的高分辨率表示。
HRNetV2:结合了所有从高到底分辨率的并行流的表示。
HRNetV2p:从HRNetV2的高分辨率输出构建出multi-level representation。
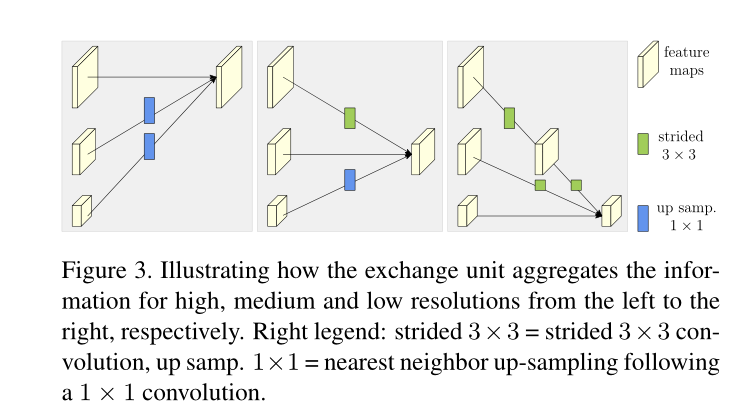
进行低分辨率和高分辨率的融合。
如果只有一行,那就不用融合。
如果有并行结构,就要进行特征融合,以论文中给出的结构为例,这是要一个三分辨率融合至三分辨率的过程。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号