

经典卷积神经网络模型
AlexNet
主要改进
- 丢弃法
- ReLU
- MaxPooling
VGG
主要改进
- VGG使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
NIN
NIN块
一个卷积层后跟两个全连接层,即步幅为1的无填充的\(1×1\)卷积层,输出形状与卷积层输出一样,起到全连接层的作用。


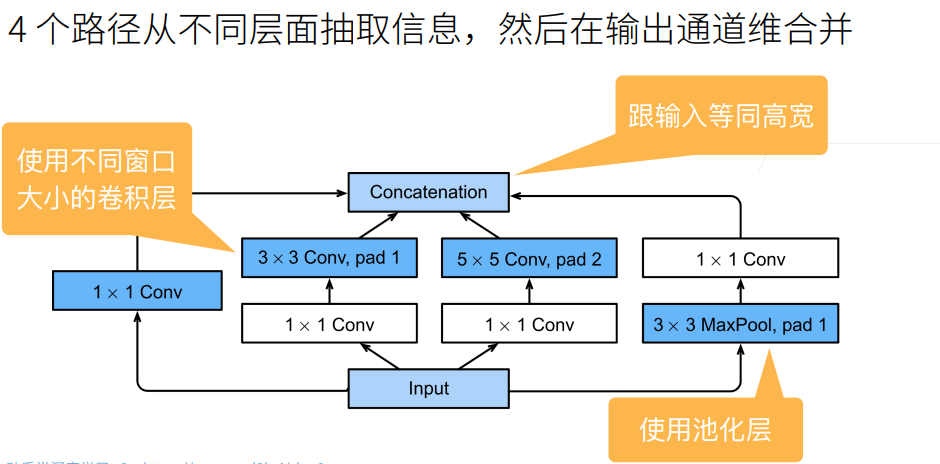
GoogleLeNet
主要改进
GoogleNet的最大贡献是提出了Inception块。Inception块具有更少的参数个数和计算复杂度。

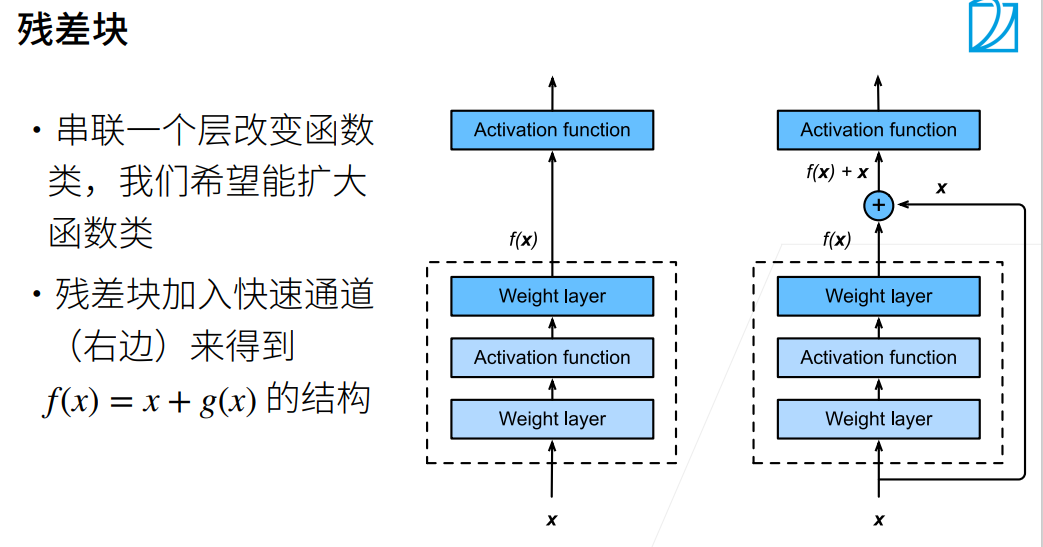
ResNet

BatchNorm



猫狗大战
解压数据集
!pip install pyunpack
!pip install patool
from pyunpack import Archive
Archive('/content/drive/MyDrive/cat_dog.rar').extractall('/content')
导包
import torch
from torch import nn
import os
import torch.utils.data as data
from PIL import Image
import numpy as np
import torch
import torchvision.transforms as transforms
from torchvision import models,transforms,datasets
import torchvision
数据处理
重写dataset方法通过文件名对图像打标签,将数据封装为dataloader类型。
IMAGE_H = 224
IMAGE_W = 224
data_transform = transforms.Compose([
transforms.ToTensor() # 转换成Tensor形式,并且数值归一化到[0.0, 1.0]
])
class DogsVSCatsDataset(data.Dataset): # 新建一个数据集类,并且需要继承PyTorch中的data.Dataset父类
def __init__(self, mode, dir):
self.mode = mode
self.list_img = [] # 新建一个image list,用于存放图片路径,注意是图片路径
self.list_label = [] # 新建一个label list,用于存放图片对应猫或狗的标签,其中数值0表示猫,1表示狗
self.data_size = 0 # 记录数据集大小
self.transform = data_transform
print(mode)
if self.mode == 'train' : # 训练集模式下,需要提取图片的路径和标签
dir = dir + '/train/'
for file in os.listdir(dir):
self.list_img.append(dir + file) # 将图片路径和文件名添加至image list
self.data_size += 1
name = file[0:3]
if name == 'cat':
self.list_label.append(0) # 图片为猫,label为0
else:
self.list_label.append(1) # 图片为狗,label为1
elif self.mode == 'val':
dir = dir + '/val/'
print(1)
for file in os.listdir(dir):
self.list_img.append(dir + file) # 将图片路径和文件名添加至image list
self.data_size += 1
name = file[0:3]
if name == 'cat':
self.list_label.append(0)
else:
self.list_label.append(1)
elif self.mode == 'test': # 测试集模式下,只需要提取图片路径就行
dir = dir + '/test/'
for file in os.listdir(dir):
self.list_img.append(dir + file)
self.data_size += 1
self.list_label.append(0)
else:
return print('Undefined Dataset!')
def __getitem__(self, item): # 重载data.Dataset父类方法,获取数据集中数据内容
if self.mode == 'train' or self.mode == 'val': # 训练集模式下需要读取数据集的image和label
img = Image.open(self.list_img[item]) # 打开图片
img = img.resize((IMAGE_H, IMAGE_W)) # 将图片resize成统一大小
img = np.array(img)[:, :, :3] # 数据转换成numpy数组形式
label = self.list_label[item] # 获取image对应的label
return self.transform(img), label
elif self.mode == 'test': # 测试集只需读取image
img = Image.open(self.list_img[item])
img = img.resize((IMAGE_H, IMAGE_W))
img = np.array(img)[:, :, :3]
label = self.list_label[item]
return self.transform(img),label # 只返回image
else:
print('None')
def __len__(self):
return self.data_size # 返回数据集大小
dir = '/content/cat_dog'
train_datasets = DogsVSCatsDataset('train',dir)
test_datasets = DogsVSCatsDataset('val',dir)
train_iter = data.DataLoader(train_datasets,batch_size=64,shuffle=True,num_workers=2)
test_iter = data.DataLoader(test_datasets,batch_size=5,shuffle=False,num_workers=2)
创建 Resnet50 Model
目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
resnet50 = models.resnet50(pretrained=True)
print(resnet50)
resnet50_new = resnet50
for param in resnet50_new.parameters():
param.requires_grad = False #预训练的模型中的大多数参数已经训练好了,因此将requires_grad字段重置为false
fc_inputs = 2048
resnet50.fc = nn.Sequential(
nn.Linear(fc_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 2),
nn.LogSoftmax(dim=1)
)
resnet50_new = resnet50_new.to("cuda")
print(resnet50.fc)
print(resnet50_new.fc)
训练并测试全连接层
包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型;第3步,测试模型。
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 使用Adam优化器
optimizer_resnet50 = torch.optim.Adam(resnet50.parameters())
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to("cuda")
classes = classes.to("cuda")
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
# 模型训练
train_model(resnet50_new,train_iter,size=len(train_datasets), epochs=1,
optimizer=optimizer_resnet50)
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to("cuda")
classes = classes.to("cuda")
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(resnet50_new,test_iter,size=len(test_datasets))
实验结果
训练集准确率
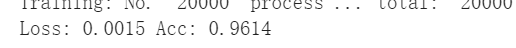
测试集准确率

使用resnet50后准确率较lenet大幅提升,可见模型的深度在图像分类中发挥着至关重要的作用,而且resnet使用了残差块的思想,减少了梯度消失,可以拥有很深的网络结构。并且resnet使用了batchnorm等方法也可以有效控制模型复杂度,加快收敛速度。


