
第一次作业:深度学习基础
本文代码使用Google的colab作为运行环境。
使用代码安装实验所需的d2l库
!pip install git+https://github.com/d2l-ai/d2l-zh@release
与深度学习相关的数据操作
1.张量基本操作
torch.arange(n)函数作用是生成一个长度为n的由0~n-1组成的张量
x.numel()可以输出张量的元素个数
torch.zeros(),torch.ones()生成一个指定大小的全0或全1的张量。
也可以通过torch.tensor()函数生成一个指定数值的张量
import torch
x=torch.arange(12)
print(x)
print(x.shape)
print(x.numel())
x=x.reshape(3,4)
print(x)
torch.zeros(3,4)
torch.ones(2,3,4)
torch.tensor([[1,3],[2,3]])
输出:
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
torch.Size([12])
12
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
tensor([[1, 3],
[2, 3]])
2.张量运算
张量可以像数值一样进行基本运算
'+'为将两个张量对应位相加,'/'为张量对应位相除,'**'为张量的乘方
x=torch.tensor([1.0,2,4,8])
y=torch.tensor([2,3,2,2])
print(x+y)
print(x/y)
print(x**y)
输出:
tensor([ 3., 5., 6., 10.])
tensor([0.5000, 0.6667, 2.0000, 4.0000])
tensor([ 1., 8., 16., 64.])
注:将1写为1.0目的是使张量的dtype转为float,方便后续除法运算
也可以通过cat函数将两个张量进行连接
reshape()函数可以改变一个张量的形状而不改变元素数量和元素值
x=torch.arange(12,dtype=torch.float32).reshape((3,4))
y=torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
torch.cat((x,y),dim=0)
通过双等号'=='来判断两个张量的元素是否相等
x==y
输出:
tensor([[False, True, False, True],
[False, False, False, False],
[False, False, False, False]])
通过sum函数对张量的元素求和
x.sum()
输出:
tensor(66.)
3.张量的广播机制
当张量的形状不同时,仍然可以通过调用'广播机制'来执行按元素操作
所谓广播机制,就是将张量填充为相同大小
a=torch.arange(3).reshape((3,1))
b=torch.arange(2).reshape((1,2))
print(a)
print(b)
a+b
输出:
tensor([[0],
[1],
[2]])
tensor([[0, 1]])
tensor([[0, 1],
[1, 2],
[2, 3]])
4. 张量的读取与写入
可以用 [-1] 选择最后一个元素,可以用 [1:3] 选择第二个和第三个元素来进行读取
除读取外,我们还可以通过指定索引来将元素写入矩阵,具体示例如代码第四行所示
为多个元素赋值相同的值,只需要索引所有元素,然后为它们赋值,具体示例如第六行所示
print(x[-1])
print(x[1:3])
print(x)
x[1,2]=9
print(x)
x[0:2,:]=12
x
输出:
tensor([ 8., 9., 10., 11.])
tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 9., 7.],
[ 8., 9., 10., 11.]])
tensor([[12., 12., 12., 12.],
[12., 12., 12., 12.],
[ 8., 9., 10., 11.]])
5.张量的内存分配
使用y=y+x通过y对y进行赋值操作时,y的存储地址将会发生改变
使用新的张量去完成赋值时(即该张量的不参与运算时)该张量的地址不会发生改变
torch.zeros_like(y)是生成一个与y形状相同的全零张量
#为新结果分配内存
before=id(y)
print(before)
y=y+x
id(y)==before
#执行原地操作
z=torch.zeros_like(y)
print(id(z))
z[:]=x+y
print(id(z))
输出:
140412974023456
False
140412974370560
140412974370560
注:数据量大时要注意两者区别,第一种方式会消耗大量内存。可以通过y+=x来减少内存开销。
5.张量的转换
可以通过.numpy()函数来将张量转换为numpy
使用torch.tensor()将numpy转换为张量
通过a.item(),float(),int(a)等函数将大小为1的张量转换为Python标量
#转换为numpy张量
A=x.numpy()
B=torch.tensor(A)
print(type(A))
print(type(B))
#将大小为1的张量转换为Python标量
a=torch.tensor([3.5])
a,a.item(),float(a),int(a)
输出:
<class 'numpy.ndarray'>
<class 'torch.Tensor'>
(tensor([3.5000]), 3.5, 3.5, 3)
注:在pytorch训练时,一般用到.item()。比如loss.item(),item()返回的是一个浮点型数据,所以在求loss或者accuracy时,一般使用item(),而不是直接取它对应的元素。这样取得的精度更高。
数据预处理
创建一个人工数据集,并存储在csv(逗号分隔值)文件
import os
os.makedirs(os.path.join('..','data'),exist_ok=True)
data_file=os.path.join('..','data','house_tiny.csv')
with open(data_file,'w') as f:
f.write('NumRooms,Alley,price\n')
f.write('NA,Pave,127500\n')
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
导入pandas包并调用read_csv函数从创建的csv文件中加载原始数据集
import pandas as pd
data=pd.read_csv(data_file)
data
构建的数据集如表所示
| NumRooms | Alley | Price | |
|---|---|---|---|
| 0 | NaN | Pave | 127500 |
| 1 | 2.0 | NaN | 106000 |
| 2 | 4.0 | NaN | 178100 |
| 3 | NaN | NaN | 140000 |
为了处理缺失的数据,典型的方法包括插值和删除,其中插值用替代值代替缺失值,而删除则忽略缺失值。这里使用插值进行处理
使用.iloc()函数取excel数据中特定列数据
使用get_dummies()函数对数据进行分类标记,将NAN标记为一个种类
#插值法处理
inputs,outputs=data.iloc[:,0:2],data.iloc[:,2]
inputs=inputs.fillna(inputs.mean())#将空值填为剩下值的均值
print(inputs)
inputs=pd.get_dummies(inputs,dummy_na=True) #分开种类标记
print(inputs)
插值结果
| NumRooms | Alley_Pave | Alley_nan | |
|---|---|---|---|
| 0 | 3.0 | 1 | 0 |
| 1 | 2.0 | 0 | 1 |
| 2 | 4.0 | 0 | 1 |
| 3 | 3.0 | 0 | 1 |
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式
import torch
x,y=torch.tensor(inputs.values),torch.tensor(outputs.values)
x,y
输出:
(tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]], dtype=torch.float64),
tensor([127500, 106000, 178100, 140000]))
矩阵操作
可以通过张量创建一个指定大小的矩阵。
import torch
A=torch.arange(20).reshape(5,4)
通过.T进行对矩阵进行转置
对称矩阵的转置与原矩阵相同
B=torch.tensor([[1,2,3],[2,0,4],[3,4,5]])
print(B)
B==B.T
输出:
tensor([[1, 2, 3],
[2, 0, 4],
[3, 4, 5]])
tensor([[True, True, True],
[True, True, True],
[True, True, True]])
给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量
B=A.clone()分配新的内存给B
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone()
A, A + B
输出:
(tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]]),
tensor([[ 0., 2., 4., 6.],
[ 8., 10., 12., 14.],
[16., 18., 20., 22.],
[24., 26., 28., 30.],
[32., 34., 36., 38.]]))
指定张量沿哪一个轴来通过求和降低维度
X=torch.arange(24).reshape(2,3,4)
print(X)
X_sum_axis0=X.sum(axis=0)
print(X_sum_axis0)
X_sum_axis1=X.sum(axis=1)
print(X_sum_axis1)
X.sum(axis=[0,1])
输出:
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
tensor([[12, 14, 16, 18],
[20, 22, 24, 26],
[28, 30, 32, 34]])
tensor([[12, 15, 18, 21],
[48, 51, 54, 57]])
tensor([60, 66, 72, 78])
保持轴数不变,可以方便利用广播机制进行求平均等运算
sum_A=A.sum(axis=1,keepdims=True)
print(sum_A)
print(A/sum_A)
输出:
tensor([[14],
[30],
[46],
[62],
[78]])
tensor([[0.1429, 0.2143, 0.2857, 0.3571],
[0.2000, 0.2333, 0.2667, 0.3000],
[0.2174, 0.2391, 0.2609, 0.2826],
[0.2258, 0.2419, 0.2581, 0.2742],
[0.2308, 0.2436, 0.2564, 0.2692]])
矩阵点积,点积是相同位置的按元素乘积的和
可以通过.dot()函数求矩阵点积,也可以通过执行按元素乘法,然后进行求和来表示两个向量的点积
y = torch.ones(4, dtype=torch.float32)
x, y, torch.dot(x, y)
torch.sum(x * y)
输出:
tensor([0., 1., 2., 3.])
tensor(6.)
tensor(6.)
矩阵向量积\(Ax\)是一个长度为m的列向量,其第i个元素是点积\(a_i^Tx\)
A=torch.arange(20).reshape(5,4)
print(A.shape)
print(A)
x=torch.tensor([0,1,2,3])
torch.mv(A,x)#矩阵向量积
输出:
torch.Size([5, 4])
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
tensor([ 14, 38, 62, 86, 110])
可以将矩阵-矩阵乘法AB看作是简单地执行m次矩阵-向量积,并将结果拼接在一起,形成一个n×m矩阵
B=torch.ones((4,3),dtype=torch.int64)
torch.mm(A,B)
输出:
tensor([[ 6, 6, 6],
[22, 22, 22],
[38, 38, 38],
[54, 54, 54],
[70, 70, 70]])
求矩阵范数
L2范数是向量元素平方和的平方根
L1范数是所有元素绝对值的和
矩阵的弗罗贝尼乌斯范数(Frobenius norm)是矩阵元素平方和的平方根
u=torch.tensor([3.0,4.0])
print(torch.norm(u))#L2范数
torch.abs(u).sum()#L1范数
torch.norm(torch.ones((4, 9)))#F范数
输出:
tensor(5.)
tensor(7.)
tensor(6.)
自动求导



1.标量的反向传播

下述代码实现对函数y=\(2x^Tx\)关于列向量x求导
requires_grad用于说明当前量是否需要在计算中保留对应的梯度信息,默认值为False
通过调用反向传播函数backward()来自动计算y关于x每个分量的梯度
import torch
x=torch.arange(4.0)
x.requires_grad_(True)
print(x.grad) #默认值为None
y=2 * torch.dot(x,x)
y.backward()
x.grad == 4 * x
输出:
None
tensor([True, True, True, True])
需要注意的是,这里x.grad默认的初始值为None
默认情况下,PyTorch会累积梯度,这里使用.grad.zero_()清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
输出:
tensor([1., 1., 1., 1.])
2.非标量变量的反向传播
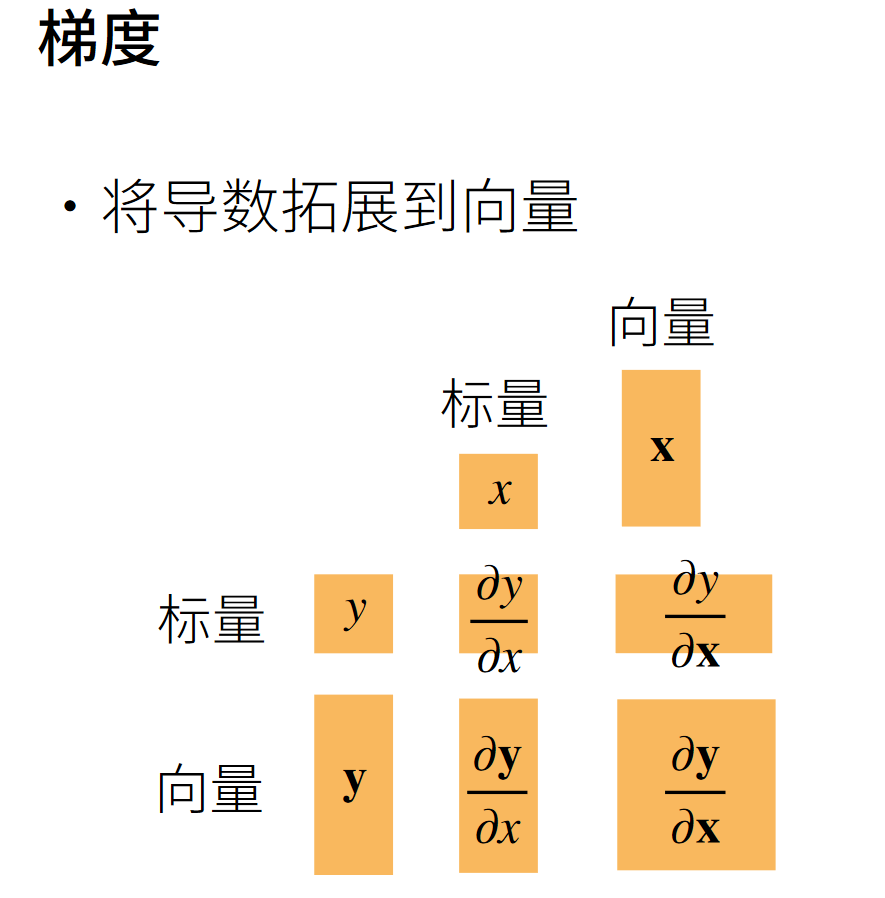
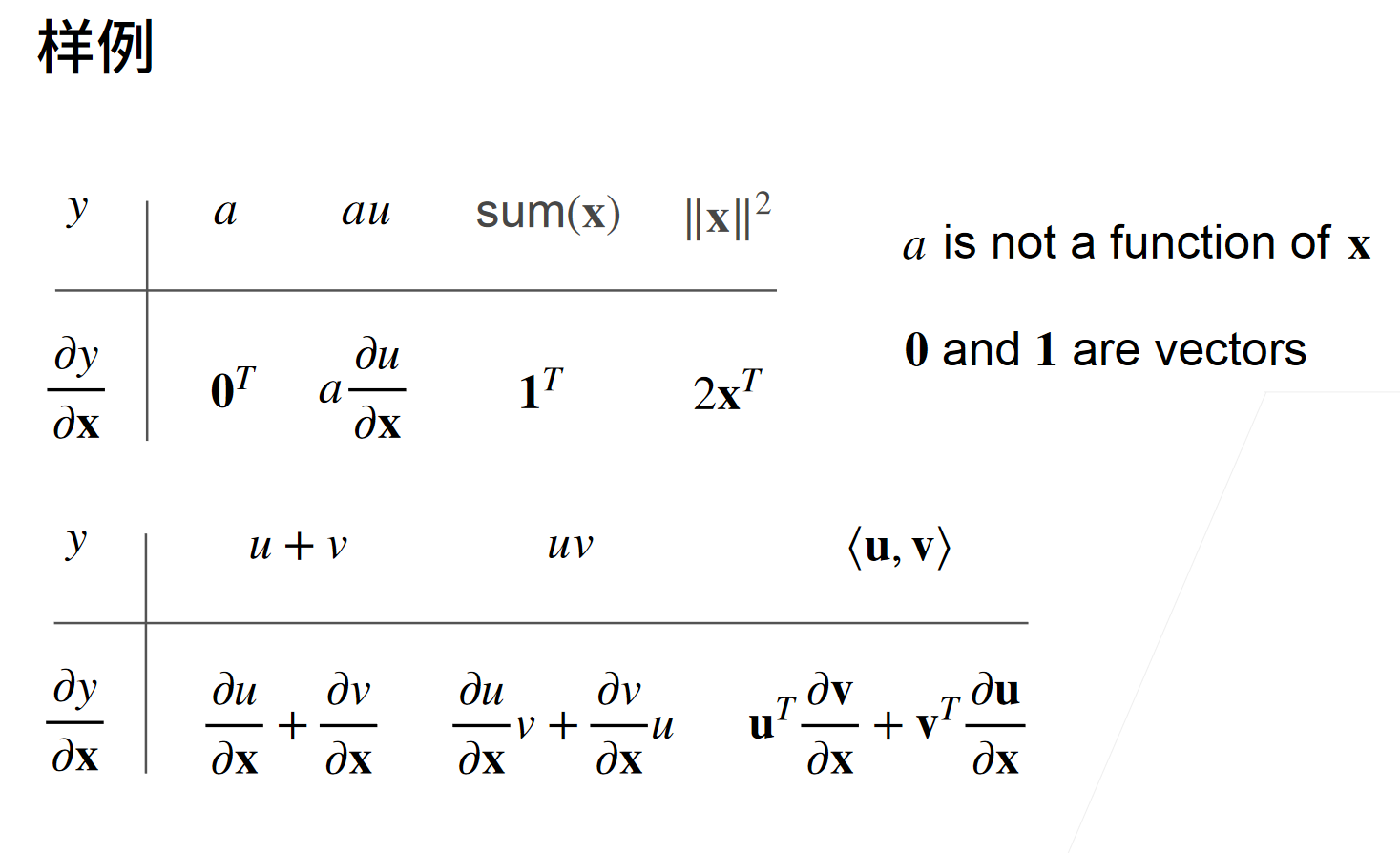

当y不是标量时,向量y关于向量x的导数的最自然解释是一个矩阵。对于高阶和高维的y和x,求导的结果可以是一个高阶张量。
对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。在我们的例子中,我们只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
#等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
输出:
tensor([0., 2., 4., 6.])
3.分离计算
有时希望将某些计算移动到记录的计算图之外。例如,假设\(y\)是作为\(x\)的函数计算的,而\(z\)则是作为\(y\)和\(x\)的函数计算的。 如果想计算\(z\)关于\(x\)的梯度,但由于某种原因,希望将y视为一个常数,并且只考虑到\(x\)在\(y\)被计算后发挥的作用。
在这里可以使用detach函数分离\(y\)来返回一个新变量\(u\),该变量与\(y\)具有相同的值,但丢弃计算图中如何计算\(y\)的任何信息。换句话说,梯度不会向后流经\(u\)到\(x\)。因此,下面的反向传播函数计算\(z=u*x\)关于\(x\)的偏导数,同时将\(u\)作为常数处理,而不是\(z=x*x*x\)关于\(x\)的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
输出:
tensor([True, True, True, True])
4.控制流的梯度计算
即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调用),仍然可以计算得到的变量的梯度
注意,\(f(a)\)在其输入\(a\)中是分段线性的。换言之,对于任何\(a\),存在某个常量标量\(k\),使得\(f(a)=k*a\),其中\(k\)的值取决于输入\(a\)。因此,使用\(d/a\)来验证梯度是否正确。
def f(a):
b=a*2
while b.norm()<1000:
b=b*2
if b.sum()>0:
c=b
else:
c=100*b
return c
a=torch.randn(size=(),requires_grad=True)
print(a)
d=f(a)
d.backward()
a.grad==d/a
输出:
tensor(1.6027, requires_grad=True)
tensor(True)
疑问
1.个人认为将requires_grad的值设为true的作用是指定求导的变量,即\(y=wx*b\),当把w的requires_grad设为true时,就是对变量\(w\)进行求导,不知是否正确?
参考了以下两篇文章
PyTorch的自动求导机制详细解析,PyTorch的核心魔法
Pytorch之autograd错误:RuntimeError: grad can be implicitly created only for scalar outputs
import torch
x=torch.ones(2,2,requires_grad=True)
print(x)
y=x+2
#y=torch.ones(2,2,requires_grad=True)
print(y)
#如果一个张量不是用户自己创建的,则有grad_fn属性.grad_fn 属性保存着创建了张量的 Function 的引用
print(y.grad_fn)
z=y+x
print(z)
z.backward(torch.ones_like(y))
print(y.grad)
输出:
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward0>)
<AddBackward0 object at 0x7fa1c4e7b550>
tensor([[4., 4.],
[4., 4.]], grad_fn=<AddBackward0>)
None
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:12: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the gradient for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more information.
if sys.path[0] == '':
输出不符合期待,发现只可以对叶节点求自动梯度,当把y更换为叶节点后,可以实现有两个requires_grad值为true的自变量求梯度。
backward()函数传参torch.ones_like(y),是因为z是一个张量,只能转化为标量使用backward()或者输入一个大小相同的张量作为参数。
2.对一些非标量的求导结果的数学推导还不太理解
感想
李沐老师的动手学深度学习课程内容安排合理,循序渐进,让我有了可以学明白的自信。想继续往前看,但是尝试发现这样做的理解并不深刻,还是要慢下脚步一点点分析,参考前任经验来加强理解,打好基础。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号