
scrapy splash模拟点击
背景
- 遇到的问题:在做爬虫时遇到用js跳转链接的

- 并且跳转的链接是加了密的,不好做拼接,这个时候一般解决办法就是
模拟点击了。

- scrapy模拟点击的话一般是用
selenium或者splash,我这里使用的是splash,貌似官方也是推荐用splash
使用splash
文档
- github https://github.com/scrapy-plugins/scrapy-splash
- 文档 https://splash.readthedocs.io/en/latest/install.html
安装
- 安装依赖库
pip install scrapy-splash
- splash需要用docker启一个服务
- 安装docker文档 https://docs.docker.com/v17.12/install/#supported-platforms,我这里写了一键安装docker脚本
wget https://github.com/1030907690/public-script/raw/master/docker/install-docker.sh && sh install-docker.sh适用于centos
docker run --name splash-standard -d -p 8050:8050 scrapinghub/splash
- 修改
settings.py文件,按照上面文档来
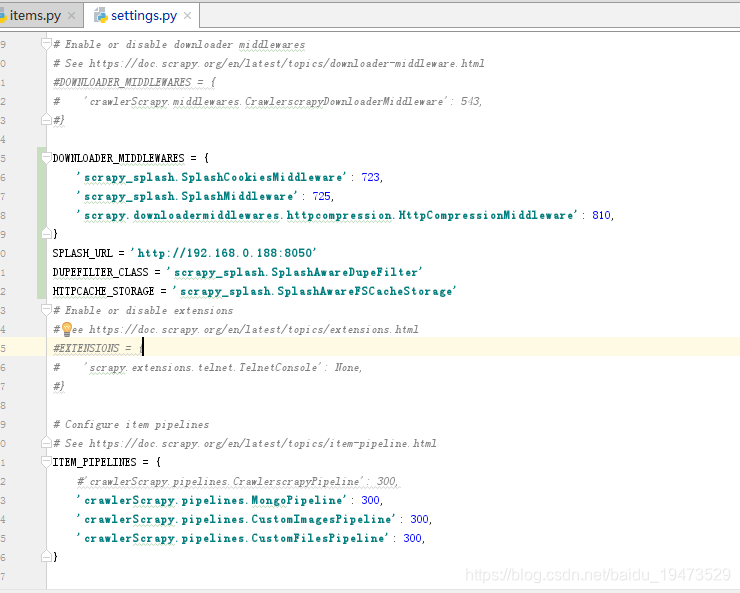
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'crawlerScrapy.middlewares.CrawlerscrapyDownloaderMiddleware': 543,
#}
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
SPLASH_URL = 'http://192.168.0.188:8050'
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#'crawlerScrapy.pipelines.CrawlerscrapyPipeline': 300,
'crawlerScrapy.pipelines.MongoPipeline': 300,
'crawlerScrapy.pipelines.CustomImagesPipeline': 300,
'crawlerScrapy.pipelines.CustomFilesPipeline': 300,
}
SPLASH_URL = 'http://192.168.0.188:8050'是刚刚启动的docker服务- 先写lua脚本,写了可以在splash的web页面测试是否成功,如下:
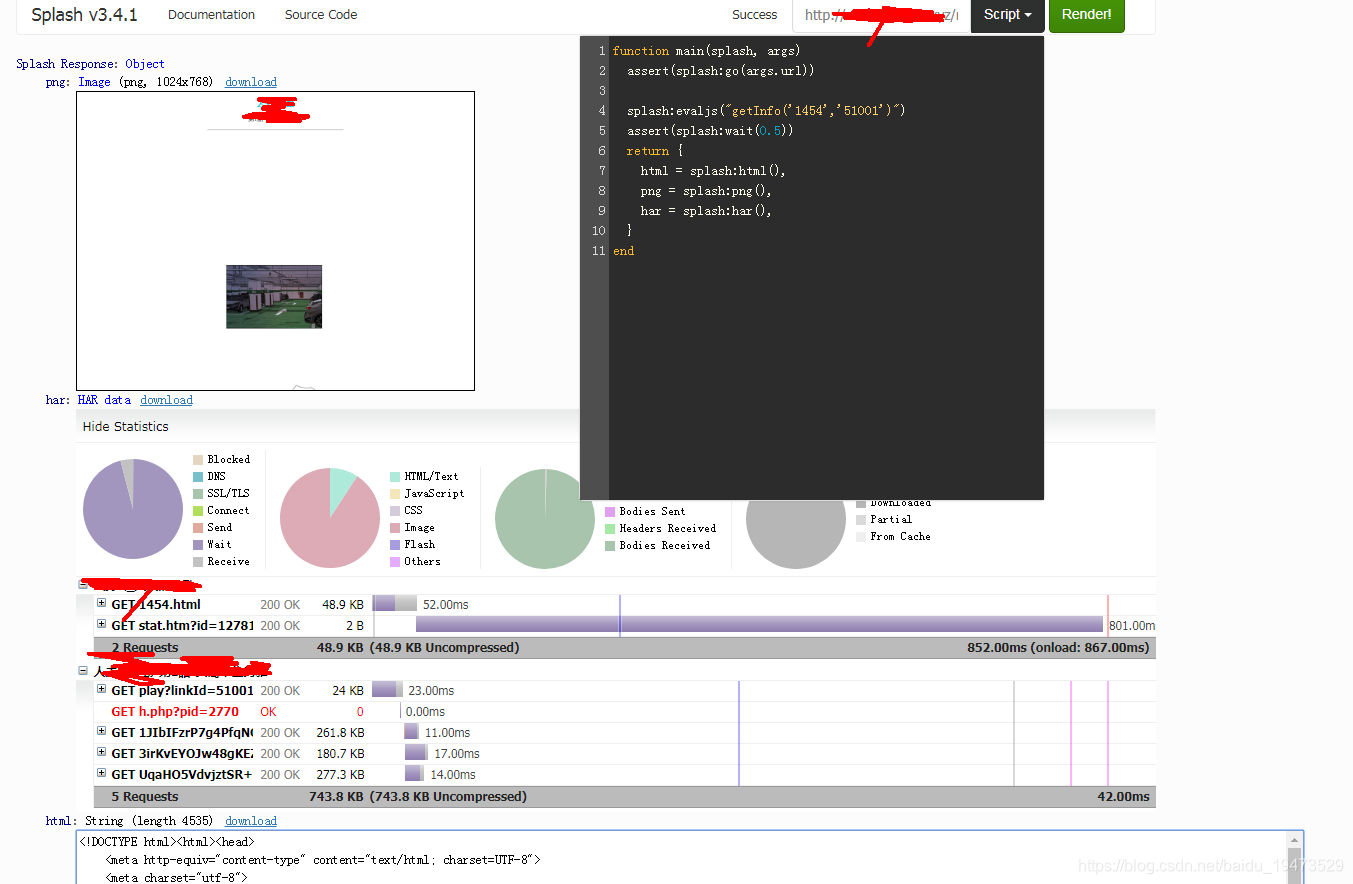
- 具体
spiders代码
import scrapy
from ..items import *
import os
import requests
from scrapy_splash import SplashRequest
#..........省略..........
class AbcComic(scrapy.Spider):
# 运行 scrapy crawl 800cms
name = "abc_comic"
allowed_domains = [host_name]
# 自定义配置
custom_settings = {
"USER_AGENT": PC_USER_AGENT,
}
start_urls = [base_url]
# 模拟点击采用js的方式
lua_script = """
function main(splash, args)
assert(splash:go(args.url))
assert(splash:wait(0.5))
splash:runjs(args.script)
assert(splash:wait(0.5))
return splash:html()
end
"""
# 进入章节内容
def chapter_info(self, response):
'''
章节详情
:param response:
:return:
'''
print(str(response.body, 'utf-8'))
def info(self, response):
'''
漫画详情
:param response:
:return:
'''
element_book_header = response.xpath("//div[@class='book-header']")
photo = element_book_header.xpath("p[1]/img[1]/@src").extract_first()
name = element_book_header.xpath("h1[1]/text()").extract_first()
author = element_book_header.xpath("p[2]/text()").extract_first()
if author:
author = author.replace("作者: ", "")
url = response.meta['relative_path']
status = 0
if name and name.find('完结') >= 0:
status = 1 # 表示完结
element_chapter_list = response.xpath("//div[@class='list-left']/div[@class='list-item']")
for chapter_item in element_chapter_list:
element_a = chapter_item.xpath("a[1]/@onclick").extract_first()
print(element_a)
yield SplashRequest(response.url,headers={"User-Agent": PC_USER_AGENT}, callback=self.chapter_info,
endpoint='execute',
args={'lua_source': self.lua_script, 'url': response.url,'script': element_a})
print(name + " " + base_url + photo)
def parse(self, response):
# print(str(response.body,'utf-8'))
element_book_list = response.xpath("//div[@id='booklist']/div")
for book_item in element_book_list:
book_click = book_item.xpath("div[1]/@onclick").extract_first()
book_url = book_click[book_click.find("'") + 1:book_click.rfind("'")]
if book_url:
yield response.follow(book_url, headers={"User-Agent": PC_USER_AGENT}, meta={"relative_path": book_url},
callback=self.info)
- 我省略了很多代码,重要的代码就是
yield SplashRequest(response.url,headers={"User-Agent": PC_USER_AGENT}, callback=self.chapter_info,
endpoint='execute',
args={'lua_source': self.lua_script, 'url': response.url,'script': element_a})
-
lua脚本的意思很简单访问
args.url页面,然后执行这个页面上的脚本args.script,变量是yield SplashRequest的时候传过去的;把这个url传进去,然后就是发起点击事件,也就是执行这个页面的jsgetInfo('1454','51001')之类的;element_a的值就是getInfo('1454','51001')这些。 -
代码运行效果,已经能执行js到下一个页面了
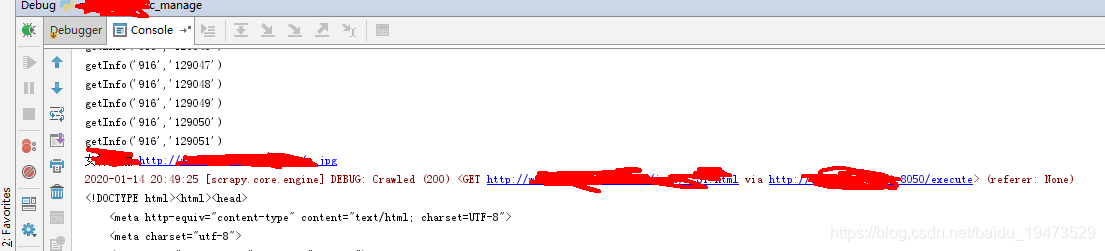
-
文章到这儿已经结束了,感谢您的观看,如果有任何问题,请批评指出,感激不尽。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现