多线程下载壁纸
本章节主要是下载https://www.h128.com/pc/anime/0/2/1920x1080/t/1.html下的电脑壁纸
第一步: 对请求路径翻页分析
经过多次请求发现utl地址,发现url中 t 后面的参数为页码
https://www.h128.com/pc/anime/0/2/1920x1080/t/1.html
https://www.h128.com/pc/anime/0/2/1920x1080/t/2.html
这样依次类推
第二步:分析每一页中的图片下载地址
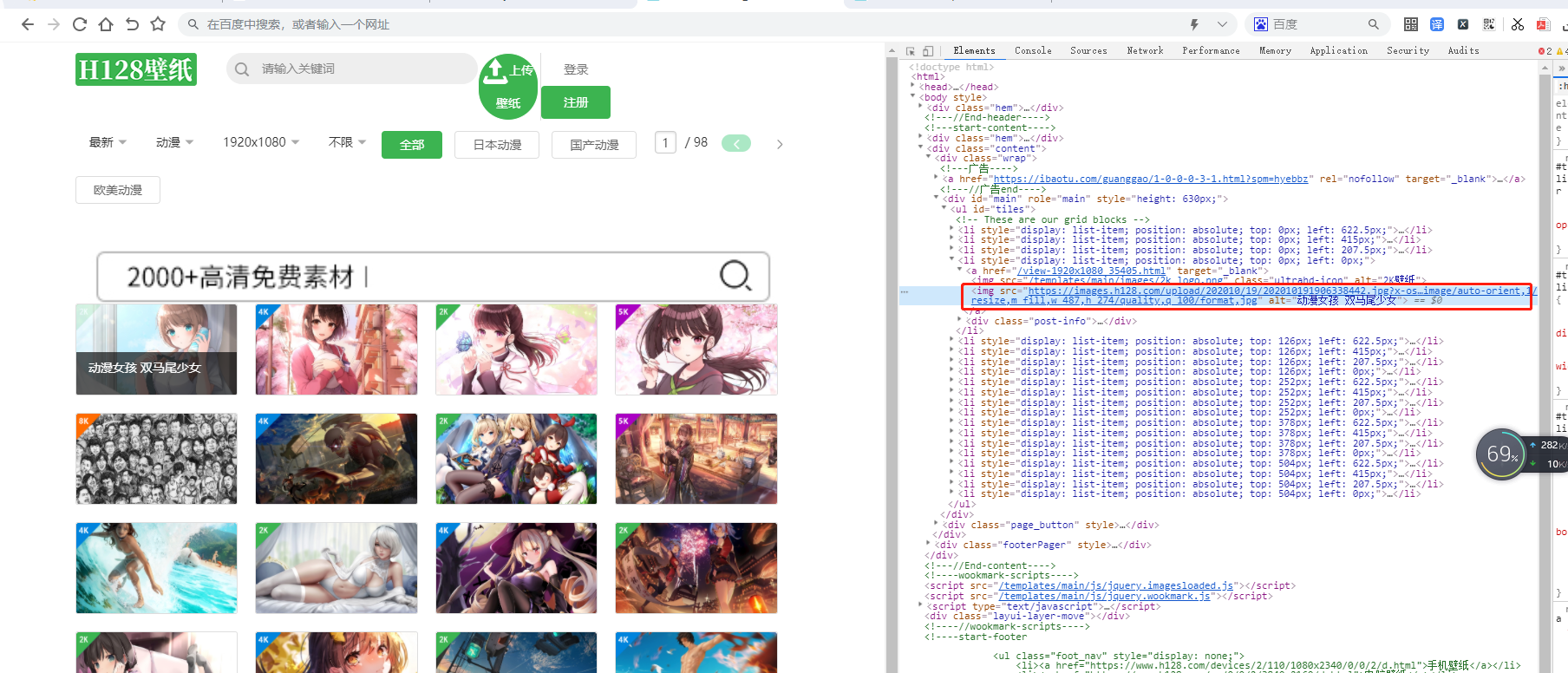
通过页面分析,每个页面的下载地址我们可以使用正则表示一次下载下来
正则表达式: '<img src="https:(.*?)" alt'
第三步:完整代码如下
代码如下:
import requests import re import os import threading import time headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"} dir = os.path.join(os.getcwd(), "下载图片") if not os.path.exists(dir): os.mkdir(dir) image_url = [] def download_imgurl(limit_page): # 获取图片下载地址 page = 1 while True: url = f"https://www.h128.com/pc/anime/0/2/1920x1080/t/{page}.html" resp = requests.get(url=url, headers=headers) if resp.status_code == 200 and len(re.findall('<img src="https:(.*?)" alt', resp.text)) > 0 and page <= limit_page: image_url.extend(re.findall('<img src="https:(.*?)" alt', resp.text)) else: break page += 1 def write_image(url): # 下载图片 imag_name = url.split("/")[6].split("?")[0] resp = requests.get("https:" + url) with open(os.path.join(dir, imag_name), "wb") as f: f.write(resp.content) def main(): thread_list = [] for url in image_url: thread = threading.Thread(target=write_image, args=[url]) thread.start() thread_list.append(thread) # 让主线程阻塞,等待所有子线程执行 for thread in thread_list: thread.join() if __name__ == '__main__': start_time = time.time() limit_page = 10 # 下载前多少页的图片 download_imgurl(limit_page) main() end_time = time.time() print(f"共计消耗{end_time-start_time}S") # 7.78秒
效果如下: