
Locust的使用
定义
Locust是一款易于使用的分布式负载测试工具。即使一个Locust节点也可以在一个进程中支持数千个用户的并发,主要通过gevent(协程)的方式。
Locust是完全基于Python,http请求完全是基于requests库。Locust支持http、https协议,还支持测试其他协议,websocket等,只要采用Python调用对应的库就可以了。
http/https采用requests;
websocket采用websocket;
特点
1:不需要编写UI或者xml代码。基于协程而不是回调,脚本编写简单;
2:可以实时查看测试结果
3:支持分布式测试,便于跨平台拓展
Locust与Jmeter的区别
| 工具 | 区别 |
| Jmeter | 需要在UI界面上通过选择组件编写脚本,模拟的负载时线程绑定的,意味着模拟的每个用户都需要一个单独的线程。单机负载机可模拟的负载数有限 |
| locust | 通过编写简单易读的代码完成测脚本,基于事件,同样配置下,单机负载可模拟的负载数远超过Jmeter |
Locust的局限性在于,目前其本身对测试过程监控和测试结果展示不如Jmeter全面,需要进行二次开发才能满足越来越复杂的性能测试需求。locust并发机制摒弃了进程和线程,采用协程机制,避免了系统及资源调度,可以大大提高单机并发能力。
安装Locust: pip install locustio 或者从GitHub克隆下来,然后运行 Python setup.py install (github: https://github.com/locustio/locust)
Locust脚本使用说明
在每一个HTTP连接的机器上打开一个新文件(技术文件描述符)。操作系统可以设置一个可以打开的文件的最大数量的下限。如果限制小于模拟用户的数量,在测试时,会发生故障。增加操作系统的默认最大数量的文件限制到一个数字高于模拟用户数的数量,才能达到你想要的测试,在centos中在命令行中执行ulimit 655336,更改文件描述符最大就行不会报open too many file 的错误。
简单示例:
from locust import HttpLocust, TaskSet, task import requests from requests.packages.urllib3.exceptions import InsecureRequestWarning # 禁用安全请求警告 requests.packages.urllib3.disable_warning(InsecureRequestWarning) class Task(TaskSet): @task() def test_baidu(self): header = {"User-Agent": "Mozilla/5.0"} # self.client.get() ===>requests.get() # self.client.post() ===>requests.post() resp = self.client.get("/qq_39706141", timeout=30, headers=header) # 使用断言看请求是否正确 或者使用if判断 assert resp.status_code == 200 # task装饰该方法表示用户行为,括号里面参数表示该行为的执行权重;数值越大,执行频率越高,不设置默认是1 @task(2) def get_blog(self): header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"} resp = self.client.get("", headers=header, verify=True) if resp.status_code == 200: assert 1 else: assert 0 class websitUser(HttpLocust): # 指向上面定义的用户行为类 task_set = Task # 执行事务之间用户等待时间的上限及下限(单位: 毫秒)
# 默认情况下,时间是在min_wait和max_wait之间随机选择,但是可以通过将wait_function设置为任意函数来使用任何用户定义的时间分布 min_wait = 3000 max_wait = 6000 if __name__ == '__main__': import os os.system("locust -f locust_lx.py --host=https://www.cnblogs.com")
Locust启动
1:如果Locust文件名为locust_lx.py并位于当前目录中,可以试用贴编译器直接运行: locust --host=https://www.conblogs.com
2:如果Locust文件位于子目录下且文件名为 locust_lx2.py 需要使用-f命令启动: locust -f testscript/locust_lx2.py --host=https://www.conblogs.com
3:如果要运行分布式在多个进程中的locust,通过指定-master一下内容来启动主程序: locust -f testscript/locust_lx2.py --master --host=https://www.conblogs.com
4:如果要启动任意数量的从属进程,可以通过-salve命令来启动: locust -f testscript/locust_lx2.py --salve --host=https://www.conblogs.com
5:如果要运行分布式Locust,必须在启动从机时指定主机(运行在单台机器上不需要): locust -f testscript/locust_lx2.py --salve --master-host=192.168.0.0 --host=https://www.conblogs.com
6:启动成功后可以直接在本地浏览器输入http://localhost:8089打开UI界面,如果是其他机器搭建locust服务,输入该机器的ip+端口即可
Locust的UI界面
1:启动界面

Number of users to simulate:设置模拟的用户总数
Hatch rate (users spawned/second):每秒启动的虚拟用户数
Start swarming:执行locust脚本
2:测试结果界面
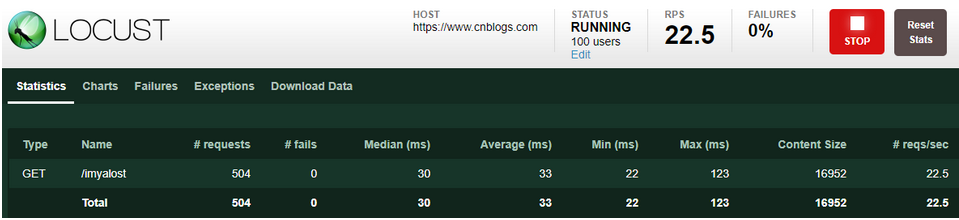
Type:请求类型,即接口的请求方法;
Name:请求路径;
requests:当前已完成的请求数量;
fails:当前失败的数量;
Median:响应时间的中间值,即50%的响应时间在这个数值范围内,单位为毫秒;
Average:平均响应时间,单位为毫秒;
Min:最小响应时间,单位为毫秒;
Max:最大响应时间,单位为毫秒;
Content Size:所有请求的数据量,单位为字节;
reqs/sec:每秒钟处理请求的数量,即QPS;
3:各模块说明
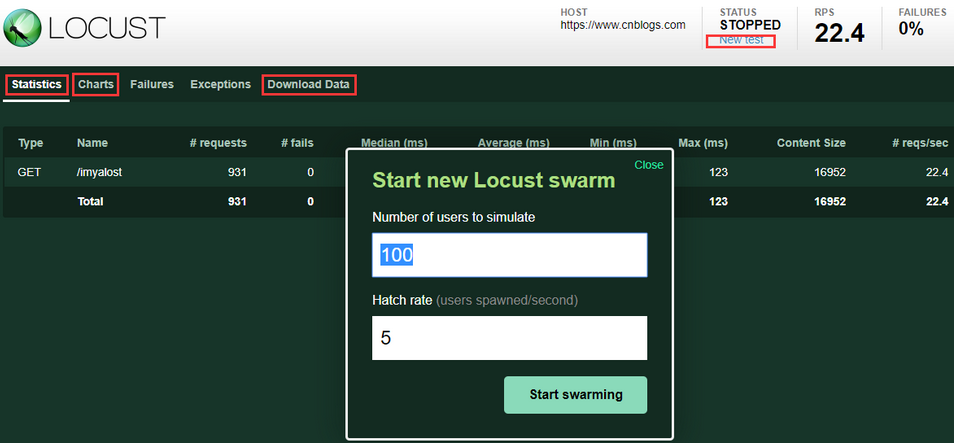
New test:点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑;
Statistics:类似于jmeter中Listen的聚合报告;
Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、不同时间的虚拟用户数;
Failures:失败请求的展示界面;
Exceptions:异常请求的展示界面;
Download Data:测试数据下载模块, 提供三种类型的CSV格式的下载,分别是:Statistics、responsetime、exceptions;
转自:https://www.cnblogs.com/imyalost/p/9758189.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号