Python-爬取京东网站商品信息,并写入excel
from retrying import retry
import requests
from lxml import etree
import time
import os
base_url = "https://search.jd.com/Search?keyword=手机华为&enc=utf-8"
if os.path.exists("JD.xlsx"):
os.remove("JD.xlsx")
def func():
return "请求失败"
@retry(stop_max_attempt_number=7, retry_on_exception=func)
def send_resp(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
resp = requests.get(url, headers=headers)
return resp
def JD():
# 商品名称
titles = []
# 商品价格
prices = []
# 店铺名称
shop_names = []
# 图片路径
img_urls = []
i = 1
while True:
time.sleep(1)
global base_url
print(f"正在爬取链接:{base_url}")
resp = send_resp(base_url)
response = resp.content.decode()
html = etree.HTML(response)
if not html.xpath('//div[@id="J_goodsList"]'):
break
for content in html.xpath('//div[@id="J_goodsList"]/ul/li'):
title = content.xpath(".//div[@class='p-name p-name-type-2']/a/em/text()")[0].split()
price = content.xpath(".//div[@class='p-price']/strong/i/text()")[0]
try:
shop_name = content.xpath(".//div[@class='p-shop']/span/a/text()")[0]
except:
shop_name = "厂商配送"
img_url = "http:" + content.xpath(".//div[@class='p-img']/a/img/@src")[0]
titles.append(title)
prices.append(price)
shop_names.append(shop_name)
img_urls.append(img_url)
base_url = f"https://search.jd.com/Search?keyword=手机华为&enc=utf-8&page={i}"
i += 1
return titles, prices, shop_names, img_urls
def main():
titles, prices, shop_names, img_urls = JD()
df = pd.DataFrame({'标题': titles, '商品价格': prices, '商铺名称': shop_names, "图片链接地址": img_urls})
df.to_excel("JD.xlsx", sheet_name="商品", index=False)
if __name__ == '__main__':
main()
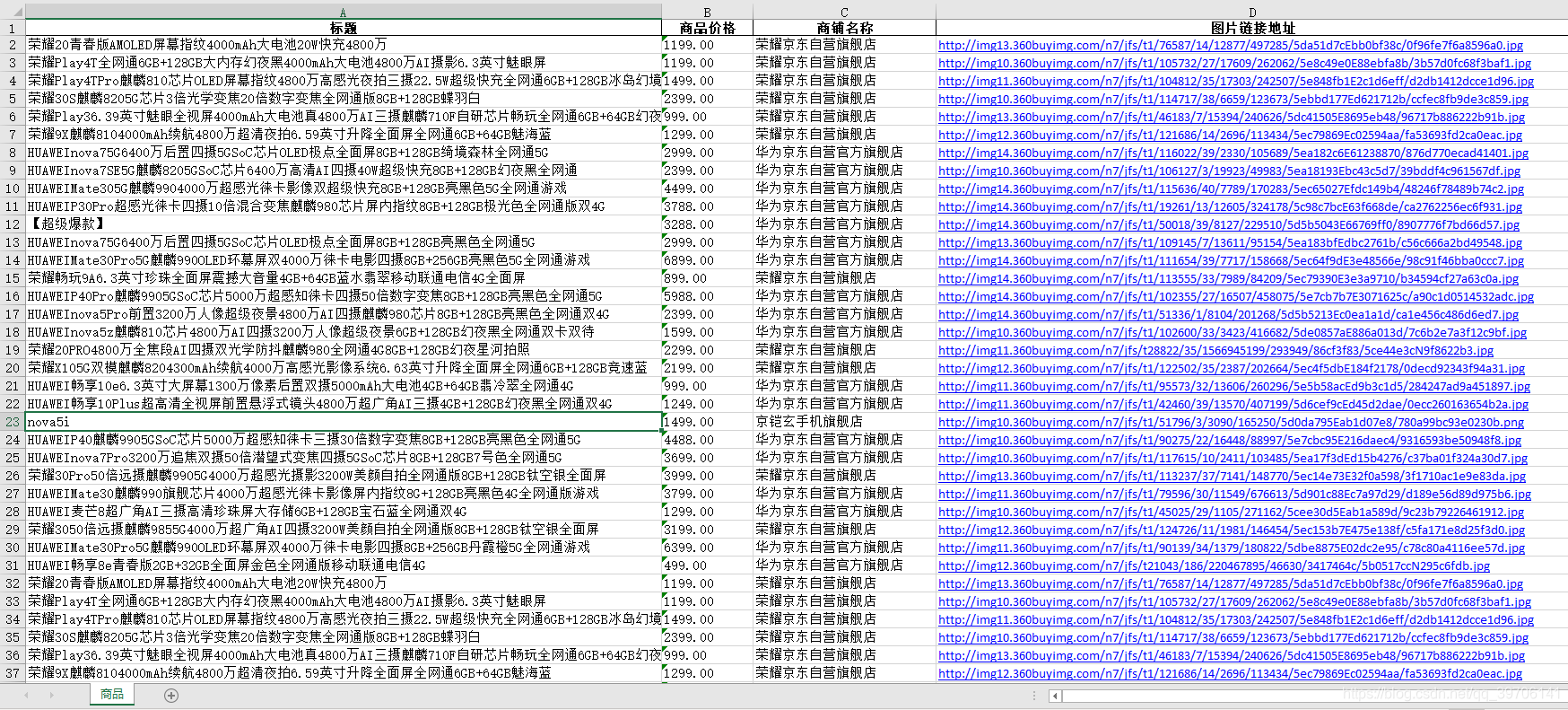
excel文件如下: