

python day07
1、字符编码
文件是操作系统中的一个虚拟概念。文件是以计算机硬盘为载体存储在计算机上的信息集合,文件可以是文本文档、图片、程序,等等。在系统运行时,计算机以进程为基本单位进行资源的调度和分配;而在用户进行的输入、输出中,则以文件为基本单位。大多数应用程序的输入都是通过文件来实现的。
在初期编写程序时,接触最多的是文本文件,比如,在注册和登录功能中,用户名和密码要存储在文件里,python程序也是写成文本文件的形式。
执行一个python文件的过程:
• Cpython解释器加载到内存
• py文件从硬盘加载到内存
• Cpython解释器向CPU发出指令,处理py文件,逐行识别文本的语法
打开一个文本文档的过程:
• 1 •启动文本编辑器(程序加载到内存),开始编辑,编辑时我们看到即时输入的内容是存在了内存
• 2 •在输入→显示的过程中,涉及到中文字符→二进制→中文字符的过程
• 3 •写完保存,编辑器把内存中的数据保存到硬盘
首先来讨论一下• 2 •,字符→二进制→字符的过程,就是编码(encode)(输入),解码(decode)(输出),的过程。
最开始计算机出现,只在英文环境里使用,所以编码解码只考虑英文字符和二进制,具体用哪些二进制数字表示哪个符号,经最早的这批人达成一致,这就是ASCII码。
后来计算机普及,每个国家都产生了自己的语言与二进制的对应标准,比如中国的GBK,因为各个国家不统一,导致了这样的问题:汉语国家编写的软件,在其他语系国家里不能使用,因为他们的计算机中没有汉语字符与二进制的对照关系!为了解决这样的问题,各国统一,unicode码诞生了,它将很多国家的字符与二进制的关系都包含在内,统一使用16位二进制数字表示各国字符。
结果就是,我们在自己的电脑文本编辑器里输入一个日文字符,编码到内存,显示(输出)的时候,这16位二进制数字会解码成日文,显示出来,而不会出现乱码的问题。
可是再后来,使用计算机的过程中,又发现了新问题:在英语系国家的编程者发现,原来采用ASCII码,用8位二进制表示字符,而现在需要16位,输入的数据存入硬盘的时间几乎长了一倍!为了解决这样的问题,又出现了UTF-8(8-bit Unicode Transformation Format),这是一种针对Unicode的可变长度字符编码,它会识别unicode编码的二进制表示的字符是什么语言的字符,并分配不同的字节,比如,如果是英文,就用1个字节存储到硬盘,如果是中文,就用3个字节存到硬盘...这是• 3 •的过程
有了UTF-8之后,只要我们写一个文件,保存成utf-8编码格式,在任何国家的电脑上也能通用,而且占的空间更小,存取更快!是不是觉得,utf-8可以完全取代unicode了!理论上的确是这样,但这里又存在一个历史遗留问题了,在这之前,很多国家都用自己国家的编码标准编写了软件,而utf-8里只有与unicode 一 一对应的关系,并没有直接和GBK,shift-jis等标准建立联系,所以直至现在,我们的计算机内存采用的,仍然是unicode.就像python3刚推出,而很多python2的软件都不能用python3运行,导致很多公司和个人拒绝使用python3,于是龟叔迫不得已推出python2.7一样,我们需要unicode来作为阶段性的过渡。
但是如果以后每个人写文件,都采用utf-8格式保存,等足够长的时间后,就可以废弃unicode标准了,也就不会存在因为编码解码而导致的程序报错和乱码问题!!
这张图可以帮助你理解编码、解码的过程和乱码、报错的原因:
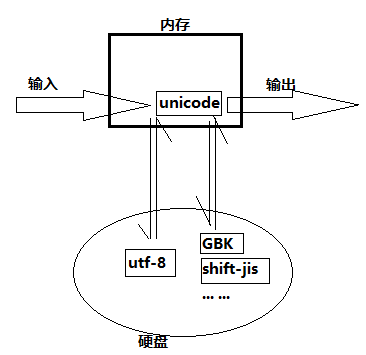
总结来说,字符编码就是字符按照某种标准转换(编码)成数字(二进制位)的过程,这个标准叫字符编码表。而解决乱码问题的关键,就是以什么格式编码的,就用什么格式解码,要保证编码解码一致,最好清晰的,人为的指定编码解码方式。比如在文件最上方添加文件头: #coding:utf-8(文件当初存的字符编码)。
python解释器默认的字符编码:python3:默认utf-8;python2:默认ASCII。
字符的指定编码转换方法:
x='张'
res=x.encode('gbk')
m=res.decode('gbk')
2、文件处理
文件是操作系统为了方便用户和应用程序管理磁盘空间,提供的虚拟单位,文件对应着磁盘空间,为了永久在磁盘存储数据,就要使用文件。应用程序和用户对文件进行读写操作都是向操作系统发送请求,由操作系统对外发送指令。
对文件进行操作首先要找到文件,也就是知道文件路径,路径有两种:绝对路径和相对路径。
• 绝对路径 是文件所在文件夹在系统中的完整位置 windows系统:D:\A_my_practice
linux系统:/use/local/lib
• 相对路径 是相对于执行文件所在文件夹的位置。
找到文件后,就可以对文件进行打开、读写、关闭操作。

# 打开文件 路径 指定读写模式(只读,以text的格式) 指定当时保存的编码格式(也就是指定解码格式) file1 = open(r'D:\A_my_practice\a.txt', mode='rt', encoding='utf-8') # 读文件 res = file1.read() print(res) # 关闭文件 file1.close()
这样打开文件,操作结束后一定要关闭,这里涉及执行文件时的内存管理:
当打开一个文件时,file1首先是python程序内存里的一个变量,占用python的内存空间,而file1的值指向一个文件,文件是操作系统这个程序产生的,所以也占用操作系统的内存,python解释器有自己的垃圾回收机制,而操作系统没有,为了不浪费内存,需要我们主动关闭文件。
还有一种打开方法,不用主动关闭:
with open('a.txt',mode='wt',encoding='utf-8') as f:
f.write("123\n")
再with...的子代码块结束之后,文件就会关闭。
以上面的代码为例,总结文件的基本操作:
打开文件有两种方式如上,open()括号内都要指定路径,r‘路径’ 表示,路径字符串是原生字符串,里面的\ 没有转义的含义。mode指定文件的操作模式:
| r | 只读,从文件头读到文件末尾,文件不存在时报错 | b | 以bytes为单位打开(二进制) |
| w |
只写,在打开时将文件内容清空,写入指定内容 文件不存时创建空文件 |
t | 以字符为单位打开 |
| a |
追加写,打开时指针移到行末,追加写入的内容 文件不存时创建空文件 |
+ |
r+ 可读可写 w+ 可写可读 a+ 可追加写可读 |
with open('a.txt', 'rb', ) as file1: # b 模式下不能指定字符编码
res = file1.read() # 一次性读全部内容
res1 = file1.readline() # 逐行读
res2 = file1.readlines() # 逐行读,将内容存放到列表
res3 = file1.readable() # 判断是否可读
with open('a.txt', 'wt', encoding='utf-8') as file1:
res = file1.write() # 清空后写入
res1 = file1.writelines() # 传入一个元素是字符串的列表,将元素逐个写入
res3 = file1.writable() # 判断是否可写
实现copy 功能:
with open('a.txt','rb') as file1,open('b.txt','wb') as file2:
file2.write(file1.read())
这种方法一次性读取文件全部内容,在内存中完成复制后存入磁盘。
缺点:如果文件过大,会占用过多内存
with open('a.txt','rb') as file1,open('b.txt','wb') as file2:
for line in file1:
file2.write(line)
这种方法逐行读取file1的内容,逐行写入file2.
优点:执行时只有一行在内存中,占用内容少。
实现修改文件功能,原理类似copy功能:
with open('a.txt','rt',encoding='utf-8') as f1:
msg = f1.read()
new_msg = msg.replace("world","python")
with open('a.txt','wt',encoding='utf-8') as f2:
f2.write(new_msg)
优点:节省磁盘空间,执行过程,只有一份数据在磁盘。编辑器采用此种方式。
缺点:如果文件过大,会占用过多内存
import os
with open('a.txt', 'rt', encoding='utf-8') as f1, \
open('.b.txt.swap', 'wt', encoding='utf-8') as f2:
for line in f1:
f2.write(line.replace("world", "python"))
os.remove('a.txt')
os.rename('.b.txt.swap', 'a.txt')
缺点:占用磁盘空间
优点:节省内存

