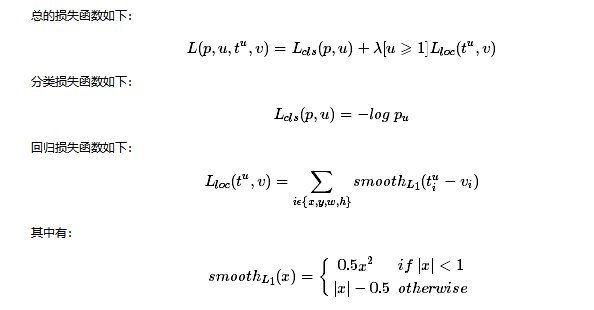一:Faster-R-CNN算法组成:
1.PRN候选框提取模块;
2.Fast R-CNN检测模块。
二:Faster-R-CNN框架介绍
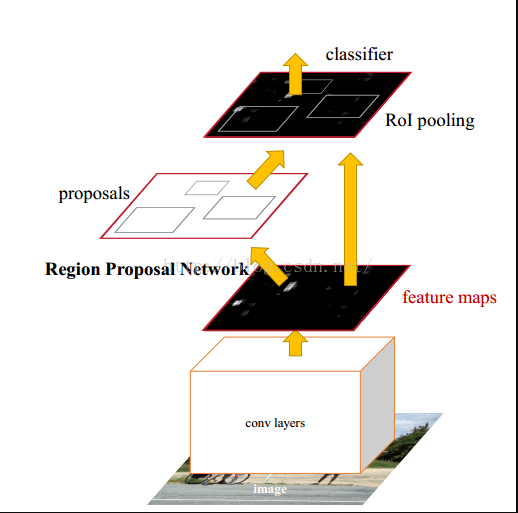
三:RPN介绍
3.1训练步骤:1.将图片输入到VGG或ZF的可共享的卷积层中,得到最后可共享的卷积层的feature map。
2.用一个小网络来卷积这个feature map
2.1在滑动窗口的每个像素点对应的原图片上上设置9个矩形窗口(3种长宽比*3种尺度),称作锚点。
至于这里为什么要在原图上,是因为最后求出来的锚点要跟原图的标定框最小梯度下降。
2.2将卷积的结果和锚点分别输入到两个小的1*1的网络中reg(回归,求目标框的位置)和cls(分类,确定该框中是不是目标)
3.训练集标记好了每个框的位置,和reg输出的框的位置比较,用梯度下降来训练网络
RPN网络把一个任意尺度的图片作为输入,输出一系列的矩形object proposals,每个object proposals都带一个objectness score。我们用一个全卷积网络来模拟这个过程,这一小节描述它。因为我们的最终目标是与Fast R-CNN目标检测网络来共享计算,所以我们假设两个网有一系列相同的卷积层。我们研究了the Zeiler and Fergus model(ZF),它有5个可共享的卷积层,以及the Simonyan and Zisserman model(VGG-16),它有13个可共享的卷积层。
为了生成region proposals,我们在卷积的feature map上滑动一个小的网络,这个feature map 是最后一个共享卷积层的输出。这个小网络需要输入卷积feature map的一个n*n窗口。每个滑动窗口都映射到一个低维特征(ZF是256维,VGG是512维,后面跟一个ReLU激活函数)。这个特征被输入到两个兄弟全连接层中(一个box-regression层(reg),一个box-classification层(cls))。我们在这篇论文中使用了n=3,使输入图像上有效的接受域很大(ZF 171个像素,VGG 228个像素)。这个迷你网络在图3(左)的位置上进行了说明。注意,由于迷你网络以滑动窗口的方式运行,所以全连接层在所有空间位置共享。这个体系结构是用一个n*n的卷积层来实现的,后面是两个1*1的兄弟卷积层(分别是reg和cls)。

3.2 Anchors(锚点)
在每个滑动窗口位置,我们同时预测多个region proposals,其中每个位置的最大可能建议的数量表示为k。所以reg层有4 k输出来编码k个box的坐标(可能是一个角的坐 标(x,y)+width+height),cls层输出2 k的分数来估计每个proposal是object的概率或者不是的概率。这k个proposals是k个参考框的参数化,我们把这些proposals叫做Anchors(锚点)。锚点位于问题的滑动窗口中,并与比例和纵横比相关联。默认情况下,我们使用3个尺度和3个纵横比,在每个滑动位置上产生k=9个锚点。对于W *H大小的卷积特性图(通常为2,400),总共有W*H*k个锚点
平移不变性的锚点
我们的方法的一个重要特性是是平移不变性,锚点本身和计算锚点的函数都是平移不变的。如果在图像中平移一个目标,那么proposal也会跟着平移,这时,同一个函数需要能够在任何位置都预测到这个proposal。我们的方法可以保证这种平移不变性。作为比较,the MultiBox method使用k聚类方法生成800个锚点,这不是平移不变的。因此,MultiBox并不保证当一个对象被平移式,会生成相同的proposal。
平移不变性也减少了模型的尺寸,当锚点数k=9时MultiBox有一个(4+1)*800维全连接的输出层,而我们的方法有一个(4+2)*9维的卷积输出层。因此,我们输出层的参数比MultiBox少两个数量级(原文有具体的数,感觉用处不大,没有具体翻译)。如果考虑到feature projection层,我们的建议层仍然比MultiBox的参数少了一个数量级。我们希望我们的方法在像PASCAL VOC这样的小数据集上的风险更小
3.3 损失函数
在计算Loss值之前,作者设置了anchors的标定方法。正样本标定规则:
1) 如果Anchor对应的refrence box 与 ground truth 的 IOU值最大,标记为正样本;
2)如果Anchor对应的refrence box与ground truth的IoU>0.7,标定为正样本。事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3)负样本标定规则:如果Anchor对应的reference box 与 ground truth的IoU<0.3,标记为负样本。
4)剩下的既不是正样本也不是负样本,不用于最终训练。
5)训练RPN的Loss是有classification loss(即softmax loss)和 regression loss(即L1 loss)按一定比重组成的。
在计算Loss值之前,作者设置了anchors的标定方法。正样本标定规则:
1) 如果Anchor对应的refrence box 与 ground truth 的 IOU值最大,标记为正样本;
2)如果Anchor对应的refrence box与ground truth的IoU>0.7,标定为正样本。事实上,采用第2个规则基本上可以找到足够的正样本,但是对于一些极端情况,例如所有的Anchor对应的reference box与groud truth的IoU不大于0.7,可以采用第一种规则生成.
3)负样本标定规则:如果Anchor对应的reference box 与 ground truth的IoU<0.3,标记为负样本。
4)剩下的既不是正样本也不是负样本,不用于最终训练。
5)训练RPN的Loss是有classification loss(即softmax loss)和 regression loss(即L1 loss)按一定比重组成的。
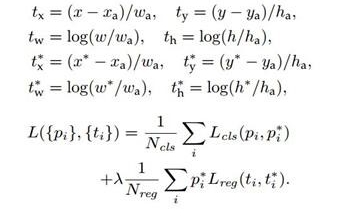
3.4 RPN训练设置
(1)在训练RPN时,一个Mini-batch是由一幅图像中任意选取的256个proposal组成的,其中正负样本的比例为1:1.
(2)如果正样本不足128,则多用一些负样本以满足有256个Proposal可以用于训练,反之亦然.
(3)训练RPN时,与VGG共有的层参数可以直接拷贝经ImageNet训练得到的模型中的参数;剩下没有的层参数用标准差=0.01的高斯分布初始化.
四:.Fast R-CNN 的介绍
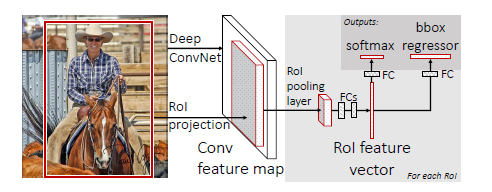
4.1 模型的流程图如下
1.1 - 训练
输入是224×224224×224的固定大小图片,经过5个卷积层+2个降采样层(分别跟在第一和第二个卷积层后面),进入ROIPooling层(其输入是conv5层的输出和region proposal,region proposal个数大约为2000个),再经过两个output都为4096维的全连接分别经过output各为21和84维的全连接层(并列的,前者是分类输出,后者是回归输出),最后接上两个损失层(分类是softmax,回归是smoothL1)
4.2 损失函数
多损失融合(分类损失和回归损失融合),分类采用log loss(即对真实分类的概率取负log,分类输出K+1维),回归的loss和R-CNN基本一样。