
面向对象第一单元训练总结
一、前言
"面向对象编程语言的问题在于,它总是附带着所有它需要的隐含环境。你想要一个香蕉,但得到的却是一个大猩猩拿着香蕉,而其还有整个丛林。"
— Joe Armstrong(Erlang语言发明人)
在许多个夜晚,当我面对着Eclipse复杂的界面,仔细思索自己前几天刚刚写下来的、现在却已经不知道是什么意思的代码的时候,我常常会质问自己:如果没有了IDE,你还能写得下去代码吗?令人遗憾的是,直到目前为止,无论我什么时候问自己这个问题,得到的答案都是否定的——当我为了添加一个新的功能,向一个类增添一个属性或方法的时候,连带着就需要向其它类添加其它的属性或方法,从而为这个类提供它所需要的数据;而为了提供这些数据,这些类又需要向另外的类申请更多的数据,直到所有的类混在一起,成为一滩稀泥,吓跑所有试图去维护它的人。最终的结果就是,我自己也忘记了我的类里面有哪些数据和方法,那些用于核心算法的方法和用于向其它类提供数据的方法互相交缠在一起,把整个类撑成了一个畸形的胖子。我只好将自己的显示器竖过来摆放,以便自己可以在一页里完整地看完一个类的定义——这还是在我的显示器长宽比是21:9的前提下。然而即便如此,如果没有了自动补全,我将依然寸步难行。
而调试的过程则更加绝望。有两个类,它们仿佛要比赛似的一个比一个长,却你中有我我中有你,每修改一处微小的地方,就会引发一连串的连锁反应,导致Bug从莫名其妙的地方冒出来。而在试图去修复这些刚冒出来的Bug时,又会引发新的Bug。不借助于IDE的单步调试功能,我甚至无法确定在自己的代码中,Bug可能会出现在哪一个方法中——因为每一个方法都与另外的方法产生了强耦合,引发一个方法中Bug的代码很可能在另一个方法中。即使我幸运地调好了一个Bug,我依然不敢肯定自己的程序能够通过之前已经测试过的样例,于是我只好把之前的样例重新再跑一遍,并祈祷它不要出错。这样一连串的过程下来,再多的时间也不够用。
本次总结,正是为了解决以上的两个问题。
二、三次作业的程序结构分析
1、第一次作业 – 多项式加减
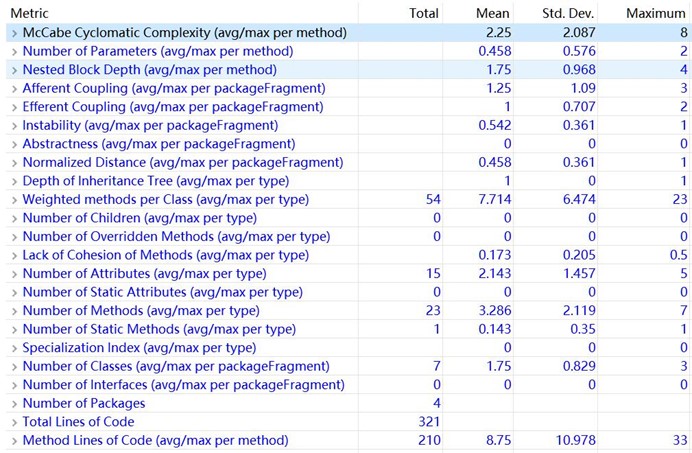
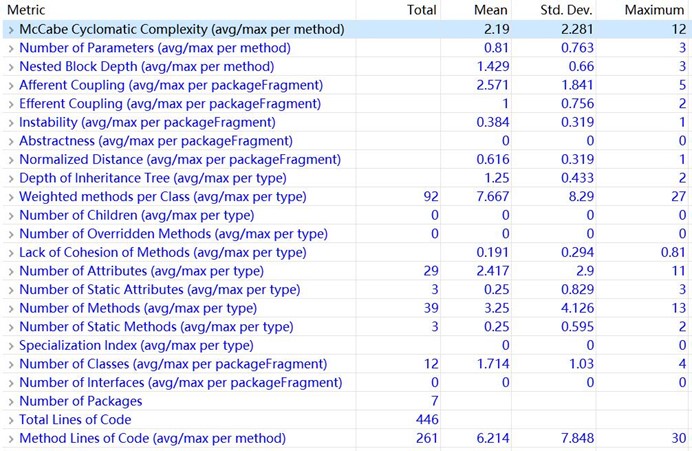
设计回顾:为了避免正则表达式爆栈,解析多项式阶段采用了双层解析的方法,先解析外层花括号,在解析内层小括号,有效避免了正则表达式效率低的缺陷。在整体的设计上,解析模块与计算模块分离,计算模块一旦获得一个多项式,就一定获得的是正确的多项式,减少了输入和计算之间的耦合。计算时则采取一了一个相对简单的算法,先对每个多项式按幂次升序排序,然后再依次归并。
自我评价:可能是由于之前在学习Python的时候有了一点点面向对象的思维基础,第一次作业写起来,我大体上遵循了面向对象的程序设计思路,而不是像C语言那样把所有东西都堆在主函数里。这次作业进行得比较顺利,在公测和互测中都有着不错的成绩。
2、第二次作业 – 单电梯傻瓜调度

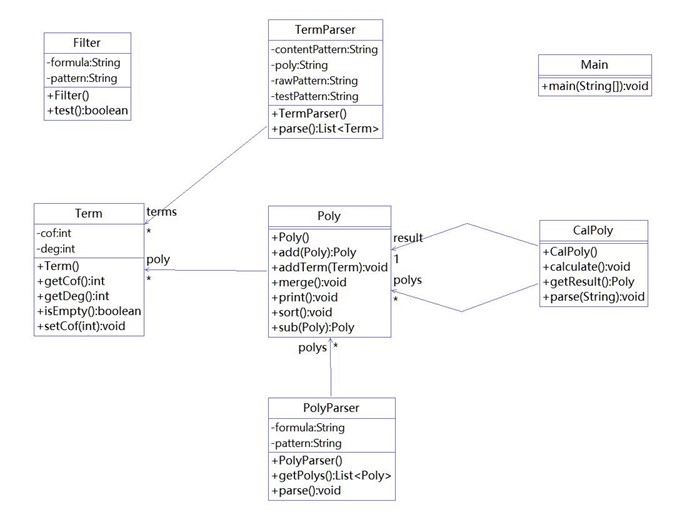
设计回顾:沿袭第一次作业的设计,解析部分与计算部分合理地分离,为核心算法的实现减少了难度。由于采用了傻瓜调度,调度器类的代码比较少,其核心方法为Schedule方法,每一次调用该方法,该方法从请求队列中选择下一个要执行的请求,并喂给电梯类去执行。电梯类承担了主要的状态保存工作。
自我评价:第二次作业的难度相比第一次作业有了一个难度上的提高,这主要是由算法带来的。第一次作业可谓根本不需要算法,但对于电梯调度问题,即使是傻瓜调度,如何判断同质请求也是一个算法上的难点。在这次作业中,我采用了一个比较简洁的算法来判断请求是否同质,时间复杂度比较低,代码实现也很简单。但万万没想到,这个看似简洁的算法为第三次作业挖了一个大坑。
3、第三次作业 – 单电梯ALS调度
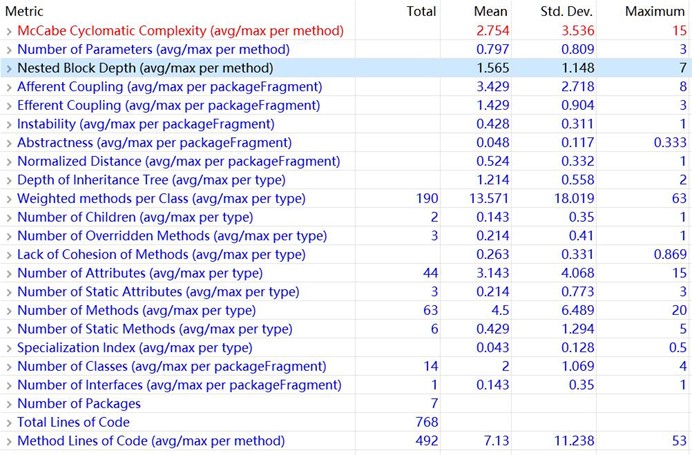
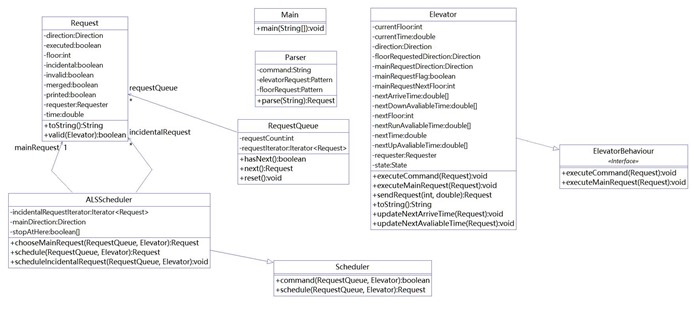
设计回顾:这一次作业相比第二次作业,重写了调度器类的Schedul方法,并大幅调整了电梯类的代码结构。Schedule方法依旧保持着其优秀的特性:每次调用,从请求队列中返回下一个将被执行请求。但为了保持这个特性,调度器类的代码变的冗长,并且电梯类增加了许多事后看来多余的方法,从整体上来说,这个设计相比第二次作业的设计,显得异常繁杂而丑陋。
个人评价:第三次作业的算法难度相比第二次作业又提高了一个层次。在这次作业中,想要又快又好地写完,就必须有一个优秀的算法。然而我在写这次作业的过程中,发现第二次作业的算法无法很简单地移植到第三次作业上来,又限于继承Scheduler类的要求不能全盘颠覆上一次的代码,因此只能在现有的基础上不断打补丁来完成需求,造成了我在前言中遇到的那两个问题。第三次作业总体上来说是失败的,程序主算法的时间复杂度达到了平方级别,并且代码又臭又长,难于调试和修改。如果有机会的话,重构应该是一个必选选项。
三、自己程序中存在的Bug
这三次作业在测试环节总体来说还是比较幸运的,只在第三次作业被别人挑出了一个涉及到100条输入边界判断的小Bug,其它的地方都没有被查出问题。当然,这个Bug是确实存在的,对此我也无可反驳。我分析了一下这个Bug出现的原因——我在对输入的请求进行是否合法的判断时,是分两个步骤进行的,第一个步骤是正则表达式的过滤,第二个步骤是判断特殊情况(一层向下或十层向上),其中任何一个步骤不通过都会立即报错,但只有第二个步骤才会检验是否超过100条指令。这意味着我的输入判断流程应该加以改变:把这两个步骤合并成一个步骤,并进行统一的报错和边界判断。
从程序结构上来讲,将输入的合法性判断放在两个类里确实不是一个好的设计。在面向对象的程序设计中,一个类应该一次性做完它所应做的工作,并把正确的结果传递给其它的类。这个Bug归根结底,还是设计上的欠缺和疏漏。
四、如何发现别人的Bug
我不太愿意去抠别人边角上的细节,因此我的测试主要集中在功能性方面,有时可能会稍微测一点Readme相关的东西,但绝不会做出跟别人玩文字游戏这种缺德 事。与其绞尽脑汁去恶心别人,不如用这时间去努力提高自己的编程水平。
拿到测试任务后,首先把自己构造的、用于测自己程序的测试用例在别人的程序上跑一遍。如果前期构造测试用例上花了功夫,这个时候应该就已经能测出绝大多数的Bug了。如果没有的话,再将程序下载下来,并通过IDE的单步调试功能分析对方代码的行为,寻找对方代码中的逻辑漏洞,并针对性地根据这些漏洞设计测试样例。最后,查看Readme,对边界条件和特殊情况进行检查。这一套流程做完之后,如果找不到Bug,那就意味着基本没有Bug了。
五、心得与体会
在前言中我提到,本次总结的最终目标在于解决类之间耦合性过强导致的代码冗长、调试不易的问题。经过对之前三次作业代码的度量和分析,我有了了以下这个即将支配我今后的作业的心得和体会——
把算法从战略需求变成战术需求。
这听起来很玄,但说透了却很简单。在以往的C语言程序中,程序=算法+数据结构的铁律支配着每一次作业的设计和实现,算法是整个程序的战略需求。因此,C语言代码的编写过程中,一切都是为算法服务的——执行核心算法的函数可以从任何地方获得它需要的任何数据,它的触角伸到程序的每一个地方,像一个全知全能的神。这使得在C语言中构造一个大型的算法非常简单,但也导致了用C语言写出来的程序稍一不注意就会有非常强的耦合性。
在Java中,类的封装特性使得在不同的方法(这里特指不同类中的不同方法)之间传递参数变得比较困难。因此,如果再沿袭C语言的设计思路,把算法放在战略的层面,一切数据和方法都为算法服务,势必会导致每一个类都互相纠缠在一起,而类属性的Private可见性会使它变得更加复杂。可以说,在Java中,一个算法不适合横跨多个类而存在,如果硬要把算法作为整个程序的战略目标,让一个类去承担全部的核心算法,就不太可能避免类之间的强耦合。
然而算法又是如此的重要,绝不可能忽视它的存在。对此,我的解决办法是,把算法在整个程序中的重要性做一个降级——从战略层面降到战术层面,尽量确保一个算法只需要类内部的数据就可以实现。这就需要在一开始对程序各个类做出一个良好而完整的规划。在Java程序设计中,顶层规划取代了原来的顶层算法,一个大的、战略层面上的算法被拆成几个小的、战术层面上的算法,交给各自所属的类去实现。通过类的封装,把算法禁锢在一个小的范围里,不让它去调用其它类中的数据。这样,就可以很好地避免类之间数据的耦合,也就能最终解决我遇到的难题。
总而言之,用Java编写程序的时候,思路和之前的C语言可以说是完全不同的。C语言可以立刻开始写起,不需要过多的构思,因为所有的数据都是唾手可得的,一个函数想要获取数据不存在任何难度。但在Java里,私有属性大大增加了其它的类访问本类数据的难度,为了防止后期不断增增补补,一开始就要对程序作出一个整体的构思和规划。如果规划合适,那写出一手漂亮的代码,不过是动动手指的事。

