
Elasticsearch---分析器(analysis)
Elasticsearch---分析(analysis)
ES 的倒排索引即是根据分词后的单词创建,意味着在搜索的时候,匹配分词后的单词才能命中该文档。
一、倒排序简介:
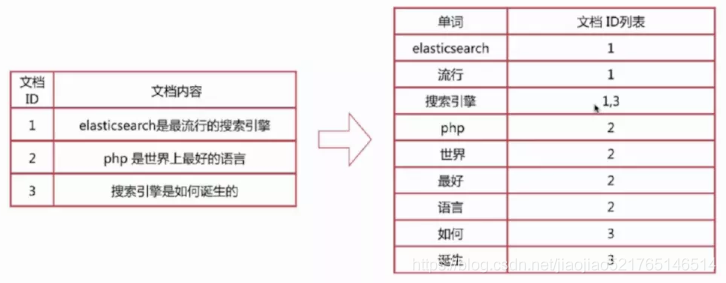
二、用到analysis的地方:
1. 写时分词:发生在写入、更新文档时,由analysis经过分析由Tokens列表,将结果存入倒排索引。
2.读时分词: 发生在用户查询时,输入的关键词进行分词,分词结果只存在内存中。
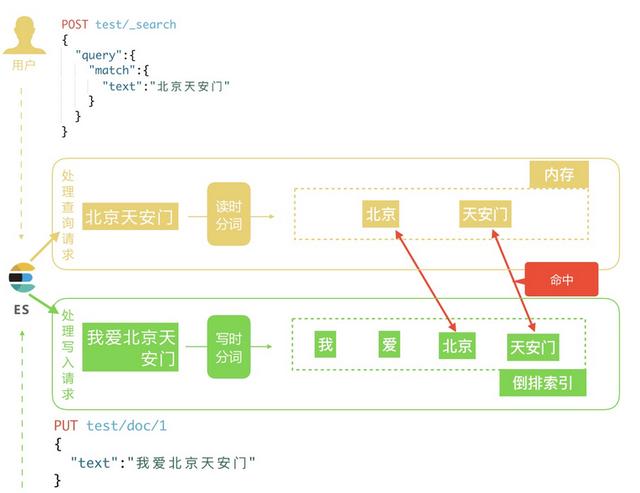
二、ES分词流程:
Character filter-->>Tokenizer-->>Token filters
分析器(Analyzer)由三部分构成:
- 0个或多个字符过滤器( Character filters)按顺序应用。
- 有且只有一个分词器(Tokenizer)
- 0个或多个过滤器(Token filters),按顺序应用。
1. 字符过滤器( Character filters):
字符过滤器以字符流的形式接收原始文本,并可以通过添加、删除或更改字符来转换该流。
Elasticearch只提供了三种字符过滤器:
- HTML字符过滤器(HTML Strip Char Filter):文本中去除HTML元素。
- 映射字符过滤器(Mapping Char Filter):映射仠替换。("mappings":["苍井空 => 666","武藤兰 => 888"])
- 模式替换过滤器(Pattern Replace Char Filter):正则表达式匹配并替换,小心导致性能变慢
| 过滤器 | 简称 | 描述 | 支持参数 |
|---|---|---|---|
| HTML Strip Char Filter | html_strip | 去除HTML元素 | escaped_tags(排除的标签数组) |
| Mapping Char Filter | mapping | 根据配置的映射配置 | mappings_path(一个key => value特定格式的文件路径,相对或config文件夹) |
| Pattern Replace Char Filter | pattern_replace | 使用java正则替换 | pattern,replacement,flags |
参考详情见:
1. https://www.cnblogs.com/Neeo/articles/10613612.html
2.分词器(Tokenizer):
一个分词器接收一个字符流,并将其拆分成单个token (通常是单个单词),并输出一个token流。
"text": "Is this déja vu?"---->Tokenizer----> tokens[...,...] token结构:
{
"token":"The", //term分词,用于倒排序。
"start_offset":0, // 所有的字符串位置信息,高亮时用到。
"end_offset":3,
"type":"word",
"position":0
}ES内置分词器:
1)标准分词器 Standard Tokenizer:
2)连词分词器 NGram Tokenizer
3)边际连词分词器 Edge NGram Tokenizer
4)关键字分词器 Keyword Tokenizer:不分词
5)字符分词器 Letter Tokenizer:将文本按非字符(non-lentter)进行分词
6)小写分词器 Lowercase Tokenizer:小写后,再按字符分词器 Letter Tokenizer
7)空格分词器Whitespace Tokenizer: 以空格来分词
8)模式分词器/正则分词器 Pattern Tokenizer
9)标准Email URL分词器 UAX Email URL Tokenizer:把email和url当作一个词
10)路径层次分词器 Path Hierarchy Tokenizer:按默认定界符: / ,路径分割
详情见:
1. https://jingyan.baidu.com/article/cbcede071e1b9e02f40b4d19.html
2. https://yuanwenjian.github.io/2018/03/10/Elasticsearch%E5%86%85%E7%BD%AE%E5%88%86%E6%9E%90%E5%99%A8/
中文分词器:
1)smartCN:一个简单的中文或中英文混合文本的分词器(官方提供)
2)IK分词器:目前比较流行的中文分词器之一,想要特别好的效果,需要自行维护词库,支持自定义词典。
3)结巴分词 : 有自行识别新词的功能,支持自定义词典
4)Ansj中文分词: 基于n-Gram+CRF+HMM的中文分词的java实现,免费开源,支持应用自然语言处理
5)hanlp: 免费开源,国人自然处理语言牛人无私风险的。
分词准确性从高到低依次是: hanlp> ansj >结巴>IK>Smart Chinese Analysis
3.Token过滤器(Token filters)
包含一个或多个,修改词(修改单词为小写),去掉词(连接词如"a”,“and”等),或者增加词(比如同义词)。处理后的结果称为索引词(Term),文档中包含几个这样的Term称为Frequency(词频 ).
es内置词元过滤器(Token Filter)
| Token Filter | 简称 | 描述 | 可支持参数 | |
|---|---|---|---|---|
| Standard | standard | standard 类型的词元过滤器规范化从 Standard Tokenizer(标准分词器)中提取的 tokens。什么也不做 | 无 | |
| ASCII Folding | asciifolding | 将不存在于ASCII中的字符转为ASCII字符 | preserve_original | |
| Flatten Graph | flatten_graph | 接受任意图形 token 流,例如由 Synonym Graph Token Filter 产生的图形 token 流,并将其平坦化为适用于索引的单个线性标记链 | 无 | |
| Length | length | 删除流中过长或过短的字词 | min && max | |
| Lowercase | lowercase | 小写过滤器 | 无 | |
| Uppercase | uppercase | 大写过滤器 | 无 | |
| NGram | nGram | 无 | min_gram && max_gram | |
| Edge NGram | edgeNGram | 无 | min_gram && max_gram | |
| Porter Stem | porter_stem | 无 tip:porter_stem限制输入必须为小写,所以之前使用lowercase货值lowercase Tokenizer | 无 | |
| Shingle | shingles | 它创建词元的组合作为单个词元 | max_shingle_size && min_shingle_size && output_unigrams && output_unigrams_if_no_shingles&& token_separator && filler_token | |
| Stop | stop | 停词过滤器 | stopwords && stopwords_path && ignore_case&& remove_trailing | |
| Word Delimiter | word_delimiter | 将单词分解为子词 | 。。。 | |
| Word Delimiter Graph | word_delimiter_graph | |||
| Stemmer | stemmer | 通过单个统一接口提供(几乎)所有可用的词干词元过滤器的访问 | name | |
| Stemmer Override | stemmer_override | 通过应用自定义映射来覆盖词干算法,然后保护这些术语不被修改词干。 必须放置在任何词干过滤器之前 | rules && rules_path | |
| Keyword Marker | keyword_marker | 保护词语不被词干分析器修改。 必须放置在任何词干过滤器之前 | keywords&& keywords_path &&keywords_pattern ignore_case | |
| Keyword Repeat | keyword_repeat | 索引两边token,一个为原始,一个为词根,所以需要添加unique过滤器,并且设置only_on_same_position 为true | 无 | |
| KStem | kstem | 用于英语的高性能过滤器 | 无 | |
| Snowball | snowball | 使用Snowball-generated 分词器 | language | |
| Phonetic | phonetic | analysis-phonetic 插件提供。 | 无 | |
| Synonym | synonym | 分析过程中轻松处理同义词。 同义词使用配置文件配置 | synonyms_path && synonyms ignore_case && expand | |
| Synonym Graph | synonym_graph | 实验版, | 无 | |
| Compound Word | hyphenation_decompounder \ | dictionary_decompounder | word_list && word_list_path &&min_word_size &&only_longest_match | 无 |
| Reverse | reverse | 将每个token反转 | 无 | |
| Elision | elision | 音节省略 | articles 设置停用词 | |
| Truncate | truncate | 将token截取为固定长度 | length 默认为10 | |
| Unique | unique | 在索引分析时仅索引唯一的token,默认为所有词条 | only_on_same_position 设为true,只删除同一位置的token | |
| Pattern Capture | pattern_capture | preserve_original true返回原始token&& patterns | ||
| Pattern Replace | pattern_replace | 基于正则替换 | ||
| Limit Token | limit | 限制每篇文档和字段索引的token数 | max_token_count 默认为1 ;consume_all_tokens,如果为ture,超出限制也会最大程度处理token | |
| Trim | trim | 去掉空白 | 无 | |
| Hunspell Token | hunspell | 用法暂时不明 | ||
| Common Grams | common_grams | 保留常用词语 | common_grams; 常用词common_words_path;ignore_case;query_mode | |
| Normalization | ||||
| CJK Width | cjk_width | |||
| CJK Bigram | cjk_bigram | |||
| Delimited Payload | delimited_payload_filter | 每当发现分隔符时,将标记分成标记和有效载荷。 | delimiter 分隔符;encoding 负载类型 | |
| Keep Words | keep | 只保留具有预定义单词集中的文本的token | keep_words保留列表;keep_words_path;keep_words_case 忽略大小写 | |
| Keep Types | keep_types | 只保留定义集合中的token | types | |
| Apostrophe | apostrophe | 过滤撇号后面字符,包括撇号 | 无 | |
| Classic | classic | 对Classic Tokenizer生成词元进行处理,从token删除后面所有权,删除省略符标点 | 无 | |
| Decimal Digit | decimal_digit | 将unicode数字转化为0-9 | 无 | |
| Fingerprint | fingerprint | 排序token,删除重复token,连接返回单个token | separator;max_output_size 如果连接的指纹增长大于max_output_size ,则过滤器将退出并且不会发出token | |
| Minhash | min_hash | 将token流中每个token一一哈希,并将生成的哈希值分成buckets,以保持每bucket最低值的散列值。 然后将这些哈希值作为token(词元)返回。minhash原理 | hash_count;bucket_count |
三、分词器设置:
1、更新分析器:
创建索引之后可以添加新的分析器,添加分析器之前必须关闭索引。
(1) 关闭:POST / my-index/_close
(2) 更新:
方式一:PUT /my-index/_settings
{
"analysis":{
"analyzer":{ //分析器列表
"my_analyzer1":{ //自定义分析器名称
"type":"custom",
"char_filter": [ "emoticons"], //0或多个(可选)
"tokenizer": "punctuation", //有且只能有一个(必须有)
"filter": [ "lowercase", "english_stop"] //0或多个(可选)
}
"my_analyzer2":{ //自定义分析器名称
"type":"custom",
"char_filter": [ "emoticons"],
"tokenizer": "punctuation",
"filter": [ "lowercase", "english_stop"]
}
}
}
}
}
方式二:PUT my-index
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": { //自定义分析器名称
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}(3) 打开:POST /my-index/_open
2. 设置默认Analyzer(全局)
default: 是索引和搜索时用的默认的 analyzer,
default_index: 是索引时用的默认的 analyzer ,
default_search: 是查询时用的默认analyzer。
操作方法: 内容填到elasticsearch/config/elasticsearch.yml中,之后重启elasticSearch(5.x 版本后,不能写在配置文件了,使用restApi来配置)
3. 自定义Tokenizer和Filter,Char_filter
(1)设置索引分析器:
基本格式:
PUT / my-index (以下设置只作用my-index索引)
{
"settings": {
"analysis": {
"char_filter": { ... custom character filters ... },
"tokenizer": { ... custom tokenizers ... },
"filter": { ... custom token filters ... },
"analyzer": { ... custom analyzers ... }
}
}
}
实例:
PUT /my_index
{
"settings":{
"analysis":{//自定义分词器的汇总
//1.分析器定义列表
"analyzer":{
"myanalyzer":{
"type":"custom", //自定义分词器
"tokenizer":"myTokenizer1", //分解器别名,具体在下边定义
"filter":["myTokenFilter1","myTokenFilter2"], //词元过滤器别名
"char_filter":["my_html"], //字符过滤器别名
"position_increment_gap":256
}
"standard": {
"type": "standard",
"stop_words": [ "it", "is", "a" ]
}
}
}
//2.分词器定义列表
"tokenizer":{ //具体定义分解器
"myTokenizer1":{
"type":"standard",
"max_token_length":900
}
}
//3.词元过滤器列表
"filter":{ //具体定义词元过滤器
"myTokenFilter1":{
"type":"stop", //stop类型用于过滤掉对应的单词
"stopwords":["stop1","stop2","stop3","stop4"], //该列表中的词都会被过滤掉
},
"myTokenFilter2":{
"type":"length",
"min":0,
"max":2000
}
}
//4. 字符过滤器列表
"char_filter":{ //具体定义字符过滤器
"my_html":{
"type":"html_strip",
"escaped_tags":[xxx,yyy],
"read_ahead":1024
}
}
}
}}2. 在字段上使用自定义分析器:
PUT /my-index/_mapping/type
{"properties":{
"title":{
"type":"text",
"analyzer":"my_analyzer"
}
}}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号