
elasticsearch 6.6 安装(CentOS 7.5) 修订
Centos 7.9
禁止 ping
vi /etc/sysctl.conf
#最后新增一行
net.ipv4.icmp_echo_ignore_all=1
#使其生效
sysctl -p更新系统至最新
yum update修改主机名
1、修改/etc/hostname文件,删除localhost,添加你的host_name
2、修改/etc/hosts文件 #尾部添加
192.168.xx.xx host_name修改 root 用户名
/etc/passwd
/etc/shadow
/etc/sudoers
/etc/passwd
/etc/shadow
第一行root改为你要的用户名
/etc/sudoers
root ALL=(ALL) ALL
下添加
新用户名 ALL=(ALL) ALL切换阿里云源
依次输入以下命令:
进入 yum 源配置目录
cd /etc/yum.repos.d
备份原 yum 源基础配置文件
mv CentOS-Base.repo CentOS-Base.repo.bak
切换 yum 基础源至阿里源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
网易163源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.163.com/.help/CentOS7-Base-163.repo
清空缓存
yum clean all
建立缓存
yum makecache##JDK JDK 和 Elastic 对应参考: https://www.elastic.co/cn/support/matrix#matrix_jvm
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u101-b13/jdk-8u101-linux-x64.tar.gz
tar -xvzf jdk-8u101-linux-x64.tar.gz
mv jdk-8u101-linux-x64 /usr/local/jdk
vi ~/.bashrc
//最后追加
export JAVA_HOME=/usr/local/jdk
export JAVA_BIN=$JAVA_HOME/bin
export JAVA_LIB=$JAVA_HOME/lib
export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar
export PATH=$JAVA_BIN:$PATH
//环境变量生效
source ~/.bashrc
java -version (如果还是不行,上述再来一次)
Elastic 6.6
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.5/elasticsearch-2.3.5.tar.gz
tar -zxvf elasticsearch-6.6.tar.gz
mv elasticsearch-6.6 /usr/local/elasticsearch
groupadd elasticgroup
useradd elastic -g elasticgroup -p /usr/local/elasticsearch
chown -R elastic:elasticgroup /usr/local/elasticsearch
配置文件
vi /usr/local/elasticsearch/config/elasticsearch.yml
//修改对应配置
vi /usr/local/elasticsearch/bin/jvm.options
//修改内存为合适状态,不要超过32G,不要超过系统内存的一半
##plugin
head chrome 装插件
Liunx 优化
内存分配不要大于32G,预留一半内存。
vi ~/elasticsearch.yml
bootstrap.memory_lock: true
分片多的话,可以提升建立索引的能力,5-20个比较合适。 如果分片数过少或过多,都会导致检索比较慢。 分片数过多会导致检索时打开比较多的文件,另外也会导致多台服务器之间通讯。 而分片数过少会导至单个分片索引过大,所以检索速度也会慢。 建议单个分片最多存储20G左右的索引数据,所以,分片数量=数据总量/20G
shards 最好不要超过3个,建议添加节点(也可参考这个值来适当加节点数)
定时优化、合并、删除已经打了删除标记的文档
项目开始导入数据,副本设置为 0,加快导入数据,刷新时间设置为 -1,大大加快导入时间。导入完毕后记得还原
禁用_all字段 查看设置代码
关闭防火墙
启动: systemctl start firewalld
关闭: systemctl stop firewalld
查看状态: systemctl status firewalld
开机禁用 : systemctl disable firewalld
开机启用 : systemctl enable firewalld
关闭SELINUX
// 查看 SELIUNX 状态
# sestatus -v
// 如果是 disabled 标示已经关闭
# vi /etc/sysconfig/selinux
// 设置 SELINUX=disabled
修改最大文件打开数
vi /etc/security/limits.conf #尾部追加
* soft nofile 204800
* hard nofile 204800
* soft nproc 204800
* hard nproc 204800
vi /etc/security/limits.d/20-nproc.conf #尾部追加
* soft nproc 204800
* hard nproc 204800
vi /etc/pam.d/login #尾部追加
session required pam_limits.so
//重启一下
定,精,简,俭

 浙公网安备 33010602011771号
浙公网安备 33010602011771号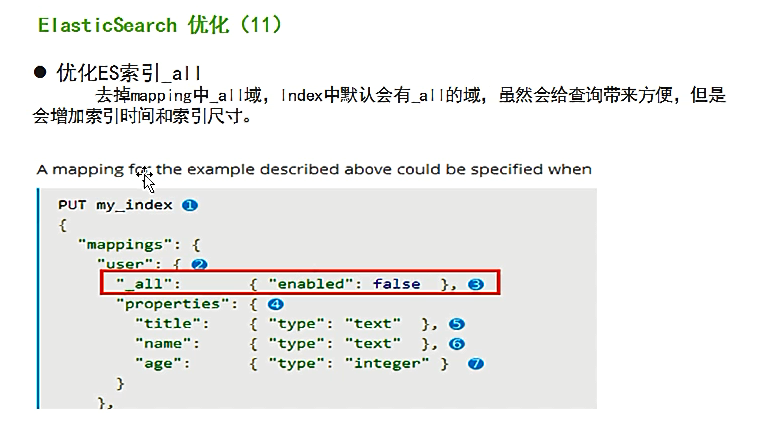{kind=link}