
间隙缓冲区
间隙缓冲区
电子科技大学软件学院 03级02班 周银辉
在文本编辑器中,我们得为文本创建一个缓冲区,那么采用什么形式的缓冲区呢? 字符串、 字符数组、链表? 还是其他? 这里推荐“间隙缓冲区”,它来得更为高效。
1,关于字符数组缓冲区
如果使用普通的字符数组(char[])来 作为缓冲区的话,很明显的会面临一个问题:当在数组中插入或删除一个字符时,会导致数组的后半部分的移动,一个极端的例子是在数组的开头插入一个字符将导致后面的Length-1的字符逐一向后移动一个位置。很明显地,这将导致严重的性能问题。
2,关于字符串缓冲区
也许我们可以没有必要照顾字符数组是如何移动的,因为String类 已经为我们做了很多工作,但了解String后会发现,其实String具有不变性,表面上的变化实质是通过创建新字符串来实现的,频繁的创建新对象将使用不少的资源。
3,关于链表缓冲区
链表的插入和删除操作代价是很小的,所以也许可以将缓冲区中的字符作为链表的节点来构造一个链表缓冲区,但如果编辑的文本较多时,即链表较长时,迭代到链表的指定位置处所花的时间将是难于忍受的,也就是说它不能像数组那样快速地索引。
4,关于间隙缓冲区
这是一种较好的方式。
间隙缓冲区其实也是一个数组,但我们会想办法来尽量避免频繁的字符移动。
我们在插入符号(要插入或删除字符的位置)的左侧增加一个“间隙”。
假设编辑器中的文本为“this is a string”,并且插入符号(当前编辑位置)在字符‘a’后面,那么它在缓冲区中的布局是这样的:
t h i s i s a * * * * s t r i n g
其中的“****”就是我们插入的“间隙”。
当我们要新插入一个字符‘n’(注意插入符号我们假定的是在字符‘a’后面哈),那么编辑器中的文本变成“this is an string”,而缓冲区中的布局变成:
t h i s i s a n * * * s t r i n g
其实我们可以发现此次插入操作并没有字符的移动(这是普通字符数组所不能达到的),没有新字符串的创建(这是String所不能达到的),而它仅仅是将该字符数组中的“间隙”的第一个‘*’替换成‘n’,即仅仅是“间隙”变短了。
同样的道理,我们发现这是一个错误语法后,要求删除字符‘a’后的‘n’,只需要执行上述过程的逆过程,将该字符数组中的“间隙”变长,将字符‘a’后的‘n’替换成‘*’就可以了。
可以发现在间隙缓冲区中,大多数的插入和删除操作仅仅导致了“间隙”的伸长或缩短,而缓冲区中的其他位置却是不发生任何变化的。
只有当插入的字符过多,导致“间隙”长度接近0时,我们才有必要重新分配空间以便将“间隙”回复到一个合理长度。比如我们可以将“间隙”默认长度设置为255,当插入了244个字符后,发现“间隙”很快将被用尽了,这时我们才重新分配空间来将“间隙”恢复至255,而这中分配次数相对与插入次数是微不足道的。
同样只有当删除的字符过多,导致“间隙”过大的时候,我们才有必要“缩紧”数组以求占用更少的空间。
不要忘了,我们是建立在插入符号(编辑位置)在“间隙”附近的假设之上,为了让该假设一直成立,当插入符号移动到“间隙”之外后,我们需要重新调整“间隙”的位置使“间隙”始终保持在插入符号附近。
5, DEMO
以下是字符串缓冲区与间隙缓冲区在长度为21000的文本的开始位置各自插入和删除10000次所花费的时间对比(单位:滴答数)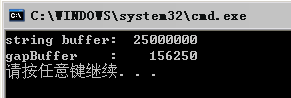
可以在这里下载这个demo: https://files.cnblogs.com/zhouyinhui/TextBufferDemo.rar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号