爬虫之XPath
XPath
XPath 是一门在 XML 文档中查找信息的语言。XPath 用来在 XML 文档中对元素和属性进行遍历。
优点:
1) 可在XML中查找信息
2) 支持HTML的查找
3) 通过元素和属性进行导航
由于XPath属于lxml库模块,所以首先要安装库lxml
pip install lxml
基础语法
选取节点
常用的表达式
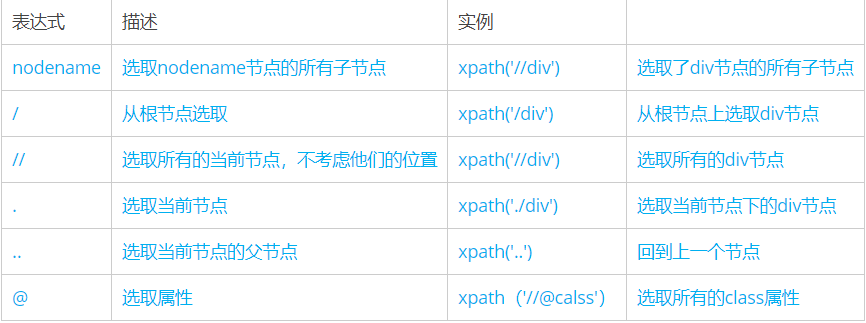
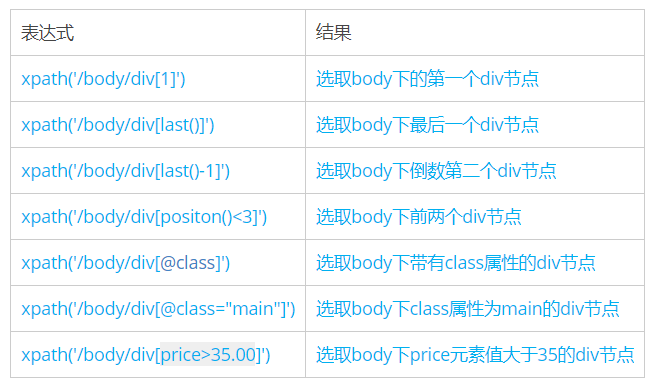
二、谓语
谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点
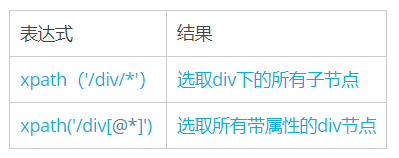
三、通配符
Xpath通过通配符来选取未知的XML元素
四、取多个路径
使用“|”运算符可以选取多个路径

五、Xpath轴
轴可以定义相对于当前节点的节点集

六、功能函数
使用功能函数能够更好的进行模糊搜索

代码实例
import requests from lxml import etree baidu=requests.get('http://www.baidu.com') #请求百度页面 baidu.encoding=baidu.apparent_encoding #页面编码 tree=etree.HTML(baidu.text) #参数只能是str格式的 a_list=tree.xpath('//*[@id="u1"]/a') #获取的结果为列表形式,故需取其中一个 for a in a_list: print(a.text,a.xpath('./@href')[0]) #遍历获取每个a标签的文本及超链接地址


 浙公网安备 33010602011771号
浙公网安备 33010602011771号