Internet and Telecommunication Fraud Prevention Analysis based on Deep Learning
基于深度学习的互联网和电信欺诈防范分析
BIO标注法和BIOES标注法
NLP中的序列标注方式常用的有两种:BIO标注法和BIOES标注法。
BIO标注法:
B-begin,代表实体的开头
I-inside,代表实体的中间或结尾
O-outside,代表不属于实体
BIOES标注法:
B-begin,代表实体的开头
I-inside,代表实体的中间
O-outside,代表非实体,用于标记无关字符
E-end,代表实体的结尾
S-single,代表单个字符,本身就是一个实体
摘要
近年来,通过电信和互联网进行的非接触式诈骗犯罪迅速增长。同时,刑事案件的破案率要低得多,这主要有两个原因。首先,在新的互联网和电信诈骗犯罪领域,风险因素的定义不全面,导致问题没有得到很好的界定。其次,互联网诈骗犯罪信息大多使用自然语言记录,数量巨大,缺乏自动化和智能化的方法来深入分析和提取风险因素。为了更好地分析互联网和电信诈骗犯罪,帮助解决更多的案件,本文提出了一种新的互联网和电信欺诈犯罪风险因素提取系统,一种基于BERT的风险因素提取技术。这种新技术可以在多维风险因素提取过程中优雅地处理多源和异构数据问题;同时,它可以显著减少对计算资源的需求,提高在线服务性能。经过实验,该技术可以显著减少训练时间60%-70%,同时可以减少80%的计算资源,在服务期间将服务性能提高5倍。在我们的方法中,我们提出了一种基于数据特征和模型训练期间的数据分布来设置样本权重和损失权重的新方法,这可以显著提高提取精度。通过在模型训练过程中调整样本权重,可以提高1.56%的精度。此外,在模型训练期间设置减重,与基线模式相比,精度可以提高1.63%。
互联网和电信欺诈风险因素知识框架
可以从几个方面研究互联网和电信诈骗的特点以及风险因素的构成,包括犯罪工具、作案手法、犯罪目标、受害者地理分布和犯罪组织。
- 欺诈工具分析:互联网和电信欺诈形式多样,发展极为迅速。截至2020年12月底,中国网民规模达9.89亿,互联网普及率为70.4%;手机用户达到9.86亿,中国网民使用手机上网的比例高达99.70%(CNNIC(中国互联网络信息中心)2021)。常用的即时通讯应用程序极易被犯罪分子用来实施诈骗。根据中华人民共和国最高人民法院发布的《网络犯罪司法大数据》和《电信和网络诈骗犯罪十大典型案例》(2019年),微信、QQ、TikTok等网络信息平台已成为互联网和电信诈骗犯罪最常用的媒介,这导致了一个灰色产业链。近年来,犯罪分子还将他们的犯罪渗透到更多的网络平台,如动物世界、交易猫、清心一狗、火币等。考虑到新型互联网和电信欺诈的快速增长,自动发现新的互联网欺诈平台以帮助识别欺诈风险非常重要。
- 作案手法分析:互联网和电信诈骗模式不断演变,诈骗脚本更新非常迅速,互联网诈骗犯罪的诈骗手法也根据公众的意识和防范措施不断更新。早期的欺诈模式,如“冒充政府代理人”、“猜猜我是谁”、“在电视节目中赢得大奖”等,正逐渐广为人知,此类欺诈的成功率越来越低,因此此类欺诈模式越来越不常见。与此同时,互联网和电信诈骗团伙发展了新的诈骗模式,如luol、兼职、快递、投资等,这些模式与目标受害者的日常生活密切相关。根据公安部门发布的文章,互联网和电信诈骗的类型大致可分为48类,包括300多个子类(网络犯罪司法大数据和2019年电信和网络诈骗犯罪十大典型案例)。新型欺诈手段和犯罪模式层出不穷,而且更加隐蔽和令人困惑。因此,如何自动发现新的犯罪模式是欺诈风险识别的另一个关键,需要将其纳入新的互联网和电信欺诈风险因素分析框架。
- 目标受众分析:为了提高成功率,犯罪分子撒下了广泛的网,涉及广泛的地理区域和众多受众。根据欺诈手法的不同,所选组也有所不同。例如,在学生贷款诈骗中,骗子往往会选择大学生作为目标;在保健品欺诈中,欺诈者往往选择老年人作为目标。因此,对目标受众的分析对于准确识别和预防互联网和电信欺诈风险至关重要。
- 受害者地理分析:根据《2018年第一季度反电信互联网和电信诈骗大数据报告》,除山东、江苏、四川、河南和广西外,广东省在诈骗电话、短信和病毒感染数量方面排名第一(李2017)。根据2017年至2019年公布的数据,互联网和电信诈骗犯罪已集中在浙江、广东、福建、河南、江苏、安徽和海南等省份。因此,分析网络欺诈受害的地理区域有利于准确防范网络欺诈犯罪风险(施2021)。
- 欺诈性财产分析:随着互联网和电信欺诈形式的多样化,欺诈性财产已从最初的单一类型(货币)发展到多种形式,如虚拟财产,包括游戏账户、游戏设备、虚拟货币等。除了银行转账,转账方式也发展成多种渠道,包括红包、扫码、微信转账、平台转账等多种形式。欺诈性财产和转移方式的多样性也使得阻止和停止支付变得更加困难。
在本文中,我们基于现有研究和领域专家的知识,通过应用故障树分析方法(Vesely等人,1981),提出了一个全面的互联网和电信诈骗犯罪风险因素知识框架。在这种方法中,新的互联网和电信欺诈风险被视为社会发展过程中产生的“错误”,“欺诈工具”、“作案手法”、“目标受众”、“受害者地理位置”、“欺诈财产”、“支付方式”等互联网和电信欺诈风险产生过程是导致系统故障的“部分”。根据故障树从系统到组件,再到部件的逻辑关系,根据“降序”分析方法,我们可以构建一个故障树图,如图1所示。
模型和实验方法
基于BERT的多源异构数据融合因子提取模型
为了克服复杂和快速发展的风险因素知识框架的问题,当前的技术需要大量标记的训练数据和巨大的模型训练工作量。为了解决互联网和电信欺诈风险因素分析,本文提出使用基于BERT的融合提取技术来解决从多来源和异构数据中提取因素的问题。输入数据支持多个数据源,不同的数据源可以用不同的因子标签进行异构标记。
模型的主要部分采用1+N的结构,其中1是多个数据集共享的BERT主体,N是与N个分类器对应的风险因素标签的数量。该模型结构支持数据集的水平扩展,避免重复的特征计算和数据标记。模型结构如图2所示。
训练过程如下:
步骤1:对于每个批次,从多个数据集获取数据的样本batch_size。
步骤2:编码数据,在本文中,我们使用BIOES标记方案来编码每一类因素。我们还将每个数据中标记的风险因素类别转换为掩码,用于计算损失函数。
步骤3:使用BERT作为融合网络结构的主要框架,并将文本数据的字符信息和位置信息传递到BERT中,BERT将对它们的表示进行编码。
步骤4:将BERT生成的句子的向量序列输入到两个堆叠的双向LSTM层中,在这两个层之间应用批量归一化,并处理文本以进行序列表示,然后再次将获得的表示序列馈送到由完全连接的网络组成的隐藏层中。
步骤5:在输出层中,不同的风险因子对应不同的CRF(条件随机场),并对不同的因子标签执行单独的梯度更新。
引入了进一步的传递矩阵参数,以生成具有有界关系的最终序列,从而可以更准确地预测BIOES标签的起始跨度和结束跨度,并可以解码风险因素类型。
步骤6:在解码阶段,在计算每个数据的所有风险因素类型的损失后,将其与步骤2中的“每个数据中标记哪些因素类型的掩码”相乘,以便未标记的因素类型不参与损失的优化。
该基于BERT的融合提取模型可以基于相同的BERT预训练模型执行不同的风险因素提取任务,该模型同时考虑了模型的共性和每个任务的特征;同时,风险因素训练数据可以从覆盖不同因素类型和不同文本类型的多个数据集中积累。这种新颖方法的优点包括:
(1) 具有不同标签的多个异构数据集可以组合在一个模型中,以帮助模型提高准确性,从而大大提高数据利用率。
(2) 它可以避免数据的重复标记,并降低标记成本。
(3) 当进行模型推断时,只需要部署一个模型,即可以同时预测多个结果,从而降低部署和硬件成本。
(4) 可以训练公共数据集和私有数据集,从而提高模型的泛化能力。

抽样权重
考虑到不同的风险因素在不同的数据集中可能具有不同的标记数据量和不同的发生概率,我们通过添加sample_weight来修改训练阶段的数据选择过程,这控制了每个批次中不同数据集的采样率。该方法提高了在同一批训练中看到更多多样性标记信息的可能性。在本文中,我们通过平滑来细化随机样本策略,这提高了训练过程中具有较少数据的因子类型的采样率,从而提高了在较少数据中因子类型的准确性。
基于sample_weight相加的数据采样过程如下。
步骤1:随机化每个数据集中的数据顺序。
步骤2:给每个数据集一个指针,最初指向每个数据集中的第一条数据。
步骤3:根据sample_weight选择数据集。例如,当前有三个数据集,数据集1、数据集2和数据集3,每个数据集的样本权重分别为0.3、0.5、0.2,然后以(0,1)之间的随机概率进行采样。
当概率介于[0.0,0.3)之间时,选择dataset2;当概率介于[0.3,0.8)之间时选择dataset3。
步骤4:获取该数据集中指针当前指向的数据,然后将指针移回一个位置。当指针移动到末尾时,数据集再次随机无序,指针指向第一个数据。
步骤5:每次获取数据时重复步骤3和4。
我们分别为随机样本和平滑样本策略设置了sample_weight配置,如下所示:
随机样本:
其中\(n\)表示有多少数据集,\(d_i\)表示第\(i\)个数据集中的数据量。随机\(sample\_weight\)与数据集的数量有关。
平滑样本:
其中\(n\)表示有多少数据集,\(d_i\)表示第\(i\)个数据集中的数据量。\(smooth\_sample\_weight_i\)是第\(i\)个数据集的采样权重,在标准化之前进行平滑。\(sample\_weight_i\)是归一化后第\(i\)个数据集的最终样本权重。这样,较少数据中的因子类型将被更频繁地采样。
损失权重:
模型主体采用1+N结构,N对应N个分类器,每个分类器负责一个风险因素的序列标记。考虑到风险因素的差异,例如发生概率较低的因素类型,该模型更难学习,因此与平均计算每个数据损失的模型相比,本文比较了无调整的损失函数和平滑损失权重的损失函数,提出了融合因子的损失权重,它综合了两个影响因素:一个是每个因子类型的标记数量,另一个是该因子类型在所属数据集中的注释出现频率。这种方法将增加损失计算中不常见风险因素的权重。
三种类型的损失函数设置如下:
无调整的基线损失公式
其中\(M\)是因子类型的数量。
具有平滑损失权重的损失公式
其中\(M\)是因子类型的数量,\(e_l\)表示第\(l\)个因子类型的数据总量,\(loss\_weight_l\)表示第\(l\)种因子类型的损失权重,我们在训练过程中对更多数据给予较少的权重。\(loss\)是通过将损失重量应用于原始损失而获得的最终损失。
具有融合因子损失权重的损失公式
其中\(M\)是因子类型的数量,\(e_l\)表示第\(l\)个因子类型的数据总量,\(d_l\)表示包含第\(l\)个要素类型的数据集的数据量之和。我们使用\(factor\_show\_out\_rate_l\)来表示第\(l\)个因子的发生概率。观察结果表明,价值越低,在训练过程中学习就越困难。我们应用\(factor\_show\_out\_rate_l\)来产生\(loss\_weight_l。\)\(loss\)是通过将损失重量应用于原始损失而获得的最终损失。
实验和结果分析
数据收集
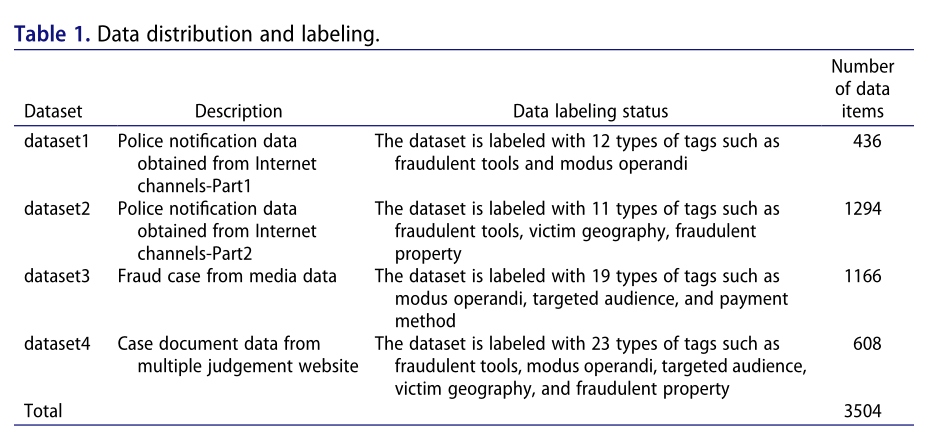
在本文中,实验数据来自从互联网获得的警方通报数据,以及来自媒体数据的诈骗案件和来自多个判决网站的案件文档数据。在筛选欺诈相关关键词后,共获得3504条文本。数据分布和标签如表1所示。
对所有获得的数据集进行了注释,表2显示了四个数据集中风险因素的总体分布。

评估标准
为了验证模型在使用时的资源使用情况和服务性能,我们使用以下指标进行比较。
(1) 硬件资源训练模型在训练期间使用的resource_GPU、训练期间GPU使用时间训练time_GPU和训练跨度时间训练持续时间。
(2) 模型推理服务占用的平均GPU资源,包括空闲GPU资源推理resource_GPU_idle、繁忙GPU资源推理resource _GPU_busy。
(3) DPS:每秒可处理的文本数量(从文本中提取的欺诈风险因素的总量)。
同时,为了验证模型在测试集上的性能,在本研究中选择了准确度(P)、召回率(R)和F1,并按照等式(12)至等式(14)计算。
在公式中,TP(真阳性)表示正确识别的风险因素的数量;FP(假阳性)表示错误识别的风险因素的数量;FN(假阴性)表示模型未正确识别的手动标记风险因素的数量。
性能分析
实验基于CPU i9-9900K和GPU GeForce RTX 2080Ti作为训练测试环境。网络结构的参数如表3所示。
以下两个比较实验是在固定参数下进行的。
(1) 基线实验:在没有本文的融合提取方法的情况下,处理本文数据集的最佳方法是训练五个不同的风险因素提取模型,以完成不同的训练任务。表4显示了5个模型的训练任务。
(2) 融合模型实验:仅需训练1个融合模型即可完成所有风险因素提取任务。模型训练任务如表5所示。
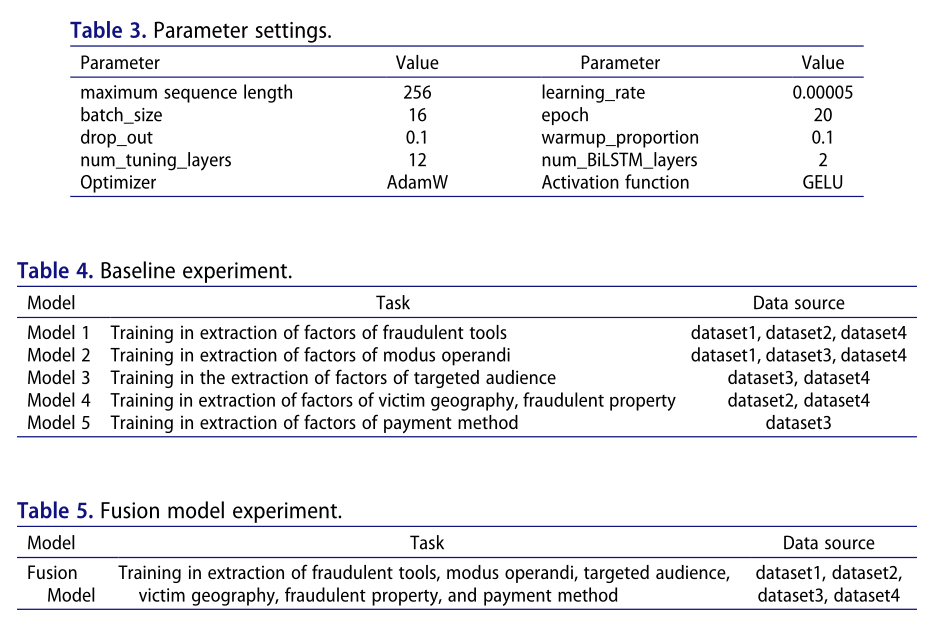
表6显示了训练过程中的相关资源占用率和绩效。
模型推断期间的相关资源占用和服务性能如表7所示。
因此,在模型设计方面,构建了基于BERT的融合因子提取技术,以解决处理多源和异构数据集的问题,与非融合模型相比,这显著减少了硬件资源并提高了使用性能。在本文所涉及的数据集上,在相同硬件资源的情况下,在训练阶段,训练时间减少了60%-70%,在模型推理阶段,硬件资源节省了70%-80%,性能提高了近5倍。
度量分析
样本权重效果比较
为了测试本文提出的数据采样权重,本文比较了两个样本权重的实验效果,并在相同的训练数据集上分别训练了两个基于BERT的融合因子提取模型,并在同一测试数据上分别计算了两个模型的P、R和F1度量。表8比较了这些指标:tensorboard图如图3所示
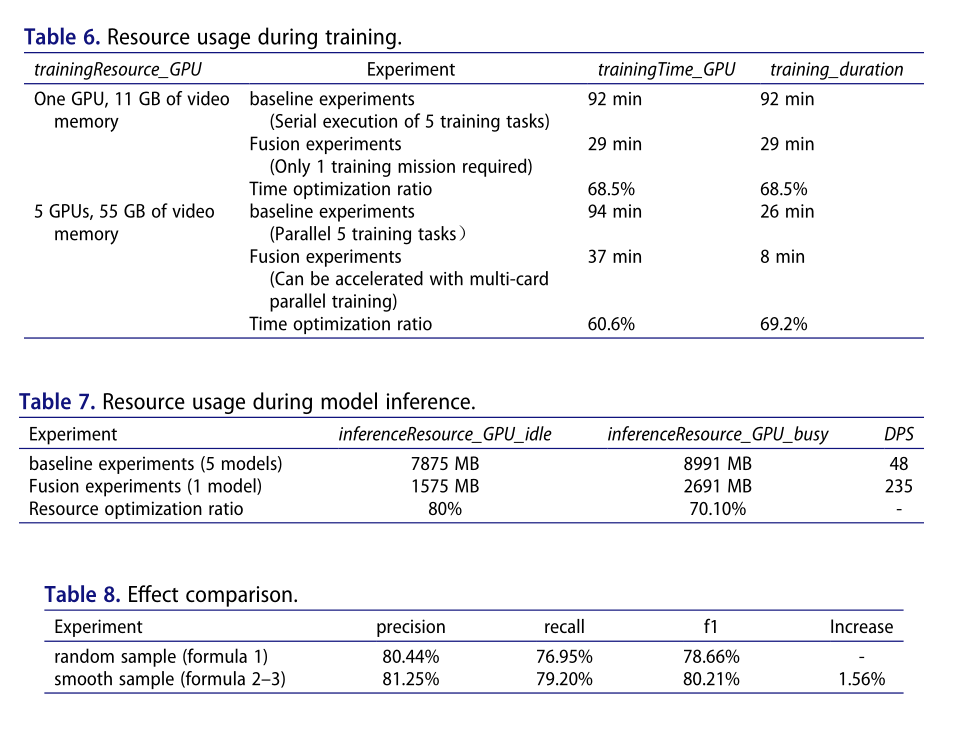
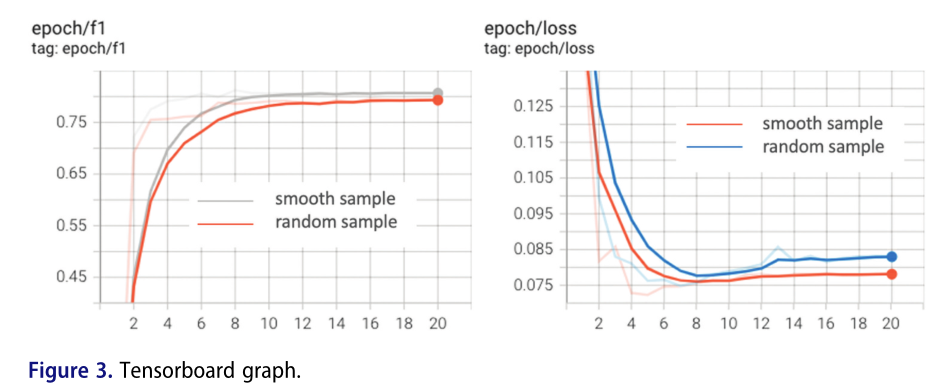
因此,在考虑具有不同标记数据量和不同发生概率的风险因素时,增加平滑样本权重以提高具有较少数据的因素类型的准确性,与随机抽样方法相比,总体准确性提高了1.56%。
损失_权重效应比较
为了测试本文提出的损失设置方法对融合因子发生概率的有效性,本文通过在同一训练数据集上训练三个基于BERT的融合因子提取模型,以及三个模型在相同测试数据上的F1度量。
表9对指标进行了比较:tensorboard图如图4所示:

因此,考虑到不同风险因素的差异,我们在损失计算中增加了融合风险因素发生概率权重的损失权重,并在损失计算时增加了不常见风险因素的权重,与基线实验相比,准确率提高了1.63%。
结论和未来工作
本文提出的新的互联网和电信欺诈风险因素从多个维度定义了新的互联网欺诈风险系统,并通过结合来自互联网的警方通报数据、来自媒体的欺诈案件数据和来自多个判决网站的案件文档数据,验证了本文方法的可行性和有效性。与非融合模型相比,本文采用的基于BERT的多源异构数据集融合因子提取技术显著减少了硬件资源,缩短了训练时间,提高了模型推理性能;本文采用的平滑数据采样方法和融合因子权重的损失方法有效地提高了新的基于互联网和电信欺诈的风险因子系统的提取精度。
本文阐述了风险因素的提取,但对基于风险因素的预警预测没有进行充分的分析。如何建立基于风险因素的预警预测模型是一个值得进一步研究的领域,这将是未来工作的一部分。
实在找不到这个主题的文章,所以看了这篇SCI四区的文章,第一次看四区的文章,有点失望,可能是我太笨,作者干的是件什么事、为什么这么做我都get不到
